







关键词:CNN、TensorFlow、卷积、池化、特征图
一. 前言
本文用TensorFlow实现了CNN(卷积神经网络)的经典结构LeNet-5, 具体CNN的LeNet-5模型原理见《深度学习(四)卷积神经网络入门学习(1)》,讲得还是比较清楚的。数据来源自MNIST, 为了方便起见,已经准备了一个脚本来自动下载和导入MNIST数据集。它会自动创建一个’MNIST_data’的目录来存储数据。
二. CNN经典结构模型
下图为CNN经典结构LeNet-5的图:
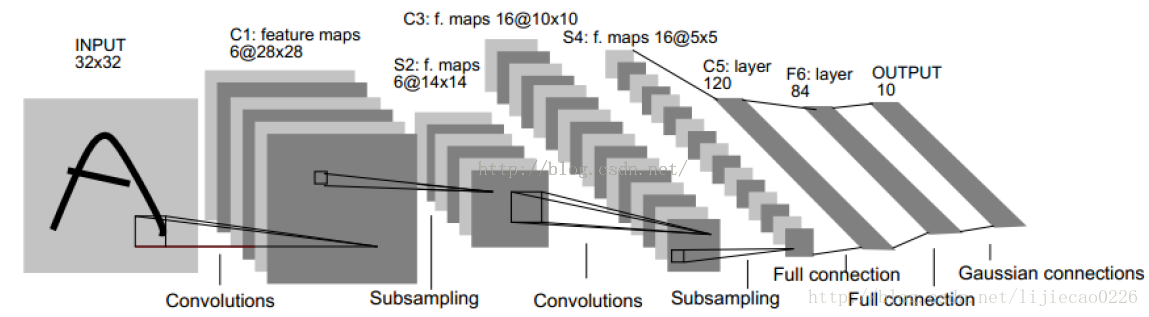
输入: 32*32的手写字体图片,这些手写字体包含0~9数字,也就是相当于10个类别的图片
输出: 分类结果,0~9之间的一个数
因此我们可以知道,这是一个多分类问题,总共有十个类,因此神经网络的最后输出层必然是SoftMax问题,然后神经元的个数是10个。LeNet-5结构:
输入层:32*32的图片,也就是相当于1024个神经元
C1层: paper作者,选择6个特征卷积核,然后卷积核大小选择5*5,这样我们可以得到6个特征图,然后每个特征图的大小为32-5+1=28,也就是神经元的个数为6*28*28=784。
S2层: 这就是下采样层,也就是使用最大池化进行下采样,池化的size,选择(2,2),也就是相当于对C1层28*28的图片,进行分块,每个块的大小为2*2,这样我们可以得到14*14个块,然后我们统计每个块中,最大的值作为下采样的新像素,因此我们可以得到S1结果为:14*14大小的图片,共有6个这样的图片。
C3层: 卷积层,这一层我们选择卷积核的大小依旧为5*5,据此我们可以得到新的图片大小为14-5+1=10,然后我们希望可以得到16张特征图。那么问题来了?这一层是最难理解的,我们知道S2包含:6张14*14大小的图片,我们希望这一层得到的结果是:16张10*10的图片。这16张图片的每一张,是通过S2的6张图片进行加权组合得到的,具体是怎么组合的呢?问题如下图所示:
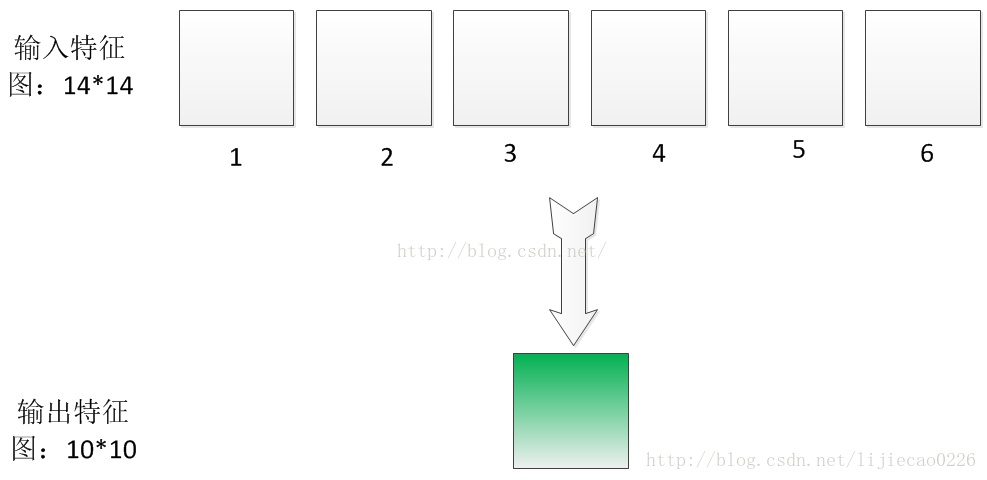
为了解释这个问题,我们先从简单的开始,我现在假设输入6特征图的大小是5*5的,分别用6个5*5的卷积核进行卷积,得到6个卷积结果图片大小为1*1,如下图所示:
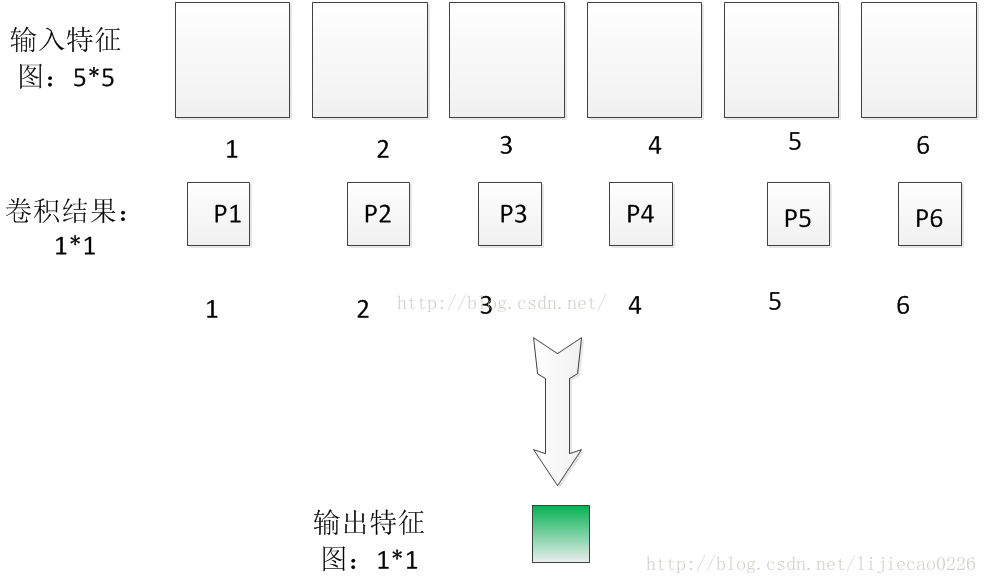
为了简便起见,我这里先做一些标号的定义:我们假设输入第i个特征图的各个像素值为x1i,x2i……x25i,因为每个特征图有25个像素。因此第I个特征图经过5*5的图片卷积后,得到的卷积结果图片的像素值Pi可以表示成:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1457
1457

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









