









花了两天时间,基本明白了CNN BP的算法。
可把conv看成局部全连接的堆砌,以全连接BP的思路推导。
https://www.cnblogs.com/tornadomeet/p/3468450.html
https://blog.csdn.net/happyer88/article/details/46772347
https://blog.csdn.net/zouxy09/article/details/9993371
https://blog.csdn.net/zy3381/article/details/44409535
问题二:当接在卷积层的下一层为pooling层时,求卷积层的误差敏感项。
假设第l(小写的l,不要看成数字’1’了)层为卷积层,第l+1层为pooling层,且pooling层的误差敏感项为: ![]() ,卷积层的误差敏感项为:
,卷积层的误差敏感项为:![]() , 则两者的关系表达式为:
, 则两者的关系表达式为:
![]()

这里符号●表示的是矩阵的点积操作,即对应元素的乘积。卷积层和unsample()后的pooling层节点是一一对应的,所以下标都是用j表示。后面的符号![]() 表示的是第l层第j个节点处激发函数的导数(对节点输入的导数)。
表示的是第l层第j个节点处激发函数的导数(对节点输入的导数)。
其中的函数unsample()为上采样过程,其具体的操作得看是采用的什么pooling方法了。但unsample的大概思想为:pooling层的每个节点是由卷积层中多个节点(一般为一个矩形区域)共同计算得到,所以pooling层每个节点的误差敏感值也是由卷积层中多个节点的误差敏感值共同产生的,只需满足两层见各自的误差敏感值相等,下面以mean-pooling和max-pooling为例来说明。
假设卷积层的矩形大小为4×4, pooling区域大小为2×2, 很容易知道pooling后得到的矩形大小也为2*2(本文默认pooling过程是没有重叠的,卷积过程是每次移动一个像素,即是有重叠的,后续不再声明),如果此时pooling后的矩形误差敏感值如下:

则按照mean-pooling,首先得到的卷积层应该是4×4大小,其值分布为(等值复制):
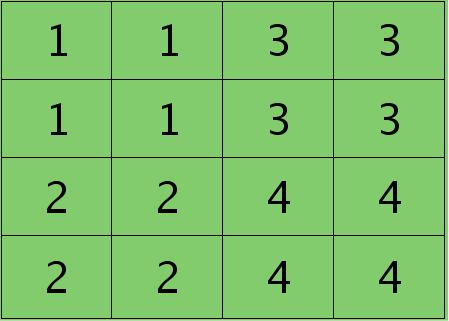
因为得满足反向传播时各层间误差敏感总和不变,所以卷积层对应每个值需要平摊(除以pooling区域大小即可,这里pooling层大小为2×2=4)),最后的卷积层值
分布为:
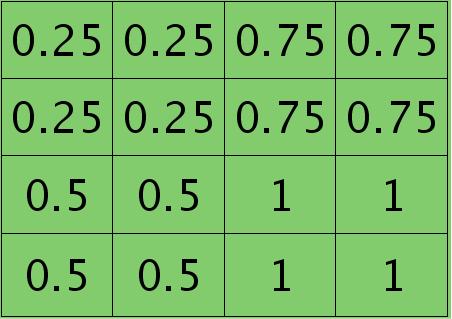
mean-pooling时的unsample操作可以使用matalb中的函数kron()来实现,因为是采用的矩阵Kronecker乘积。C=kron(A, B)表示的是矩阵B分别与矩阵A中每个元素相乘,然后将相乘的结果放在C中对应的位置。比如:

delta_meanpooling=np.array([[1,3],[2,4]])
delta_nopooling=np.kron(delta_meanpooling,np.ones([2,2])*1/4)#矩阵Kronecker乘积
print(delta_nopooling)如果是max-pooling,则需要记录前向传播过程中pooling区域中最大值的位置,这里假设pooling层值1,3,2,4对应的pooling区域位置分别为右下、右上、左上、左下。则此时对应卷积层误差敏感值分布为:
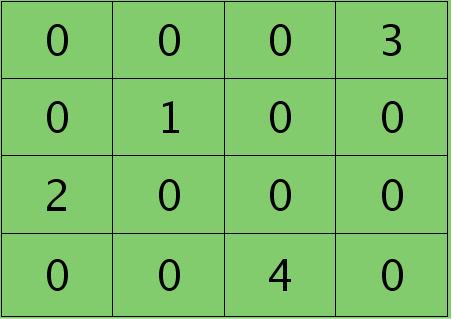
当然了,上面2种结果还需要点乘卷积层激发函数对应位置的导数值了,这里省略掉。
问题三:当接在pooling层的下一层为卷积层时,求该pooling层的误差敏感项。
假设第l层(pooling层)有N个通道,即有N张特征图,第l+1层(卷积层)有M个特征,l层中每个通道图都对应有自己的误差敏感值,其计算依据为第l+1层所有特征核的贡献之和。下面是第l+1层中第j个核对第l层第i个通道的误差敏感值计算方法:
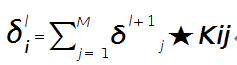

符号★表示的是矩阵的卷积操作,这是真正意义上的离散卷积,不同于卷积层前向传播时的相关操作,因为严格意义上来讲,卷积神经网络中的卷积操作本质是一个相关操作,并不是卷积操作,只不过它可以用卷积的方法去实现才这样叫。而求第i个通道的误差敏感项时需要将l+1层的所有核都计算一遍,然后求和。另外因为这里默认pooling层是线性激发函数,所以后面没有乘相应节点的导数。
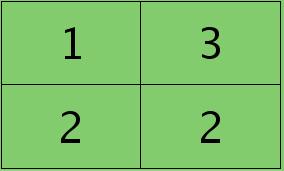
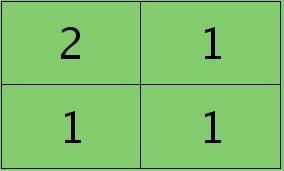
举个简单的例子,假设拿出第l层某个通道图,大小为3×3,第l+1层有2个特征核,核大小为2×2,则在前向传播卷积时第l+1层会有2个大小为2×2的卷积图。如果2个特征核分别为:


反向传播求误差敏感项时,假设已经知道第l+1层2个卷积图的误差敏感值:
离散卷积函数conv2()的实现相关子操作时需先将核旋转180度(即左右翻转后上下翻转),但这里实现的是严格意义上的卷积,所以在用conv2()时,对应的参数核不需要翻转(在有些toolbox里面,求这个问题时用了旋转,那是因为它们已经把所有的卷积核都旋转过,这样在前向传播时的相关操作就不用旋转了。并不矛盾)。且这时候该函数需要采用’full’模式,所以最终得到的矩阵大小为3×3,(其中3=2+2-1),刚好符第l层通道图的大小。采用’full’模式需先将第l+1层2个卷积图扩充,周围填0,padding后如下:
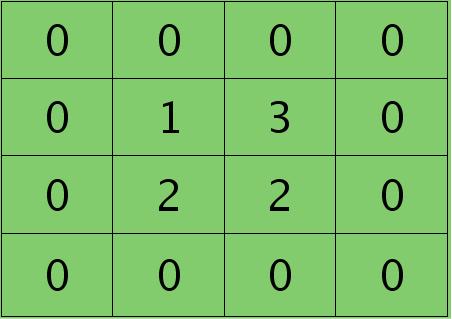
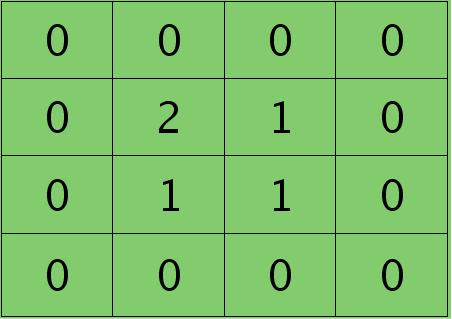
扩充后的矩阵和对应的核进行卷积的结果如下情况:
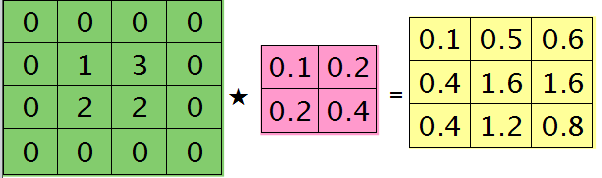

可以通过手动去验证上面的结果,因为是离散卷积操作,而离散卷积等价于将核旋转后再进行相关操作。而第l层那个通道的误差敏感项为上面2者的和,呼应问题三,最终答案为:

# coding=utf-8
import os
os.environ["TF_CPP_MIN_LOG_LEVEL"]='2' # 只显示 warning 和 Error
import numpy as np
import scipy.signal as signal
deltaj=np.array([[2,1],[1,3],[1,2],[1,2]]) #[?Red,?Greeen]
kij=np.array([[-0.3,0.1],[0.1,0.2],[0.1,0.2],[0.2,0.4]])#[wi0,wi1]
deltaj=np.reshape(deltaj,[1,2,2,2])#1X2X2 2maps
kij=np.reshape(kij,[2,2,1,2])#2X2 1输入通道 2输出通道
def get_deltai(k,i,j,deltaj,kij):
deltaj=deltaj[k,:,:,j]
kij=kij[:,:,i,j]
return signal.convolve2d(deltaj, kij,'full')
print(get_deltai(0,0,1,deltaj,kij))
print(deltaj)
print(kij)那么这样问题3这样解的依据是什么呢?其实很简单,本质上还是bp算法,即第l层的误差敏感值等于第l+1层的误差敏感值乘以两者之间的权值,只不过这里由于是用了卷积,且是有重叠的,l层中某个点会对l+1层中的多个点有影响。比如说最终的结果矩阵中最中间那个0.3是怎么来的呢?在用2×2的核对3×3的输入矩阵进行卷积时,一共进行了4次移动,而3×3矩阵最中间那个值在4次移动中均对输出结果有影响,且4次的影响分别在右下角、左下角、右上角、左上角。所以它的值为2×0.2+1×0.1+1×0.1-1×0.3=0.3, 建议大家用笔去算一下,那样就可以明白为什么这里可以采用带’full’类型的conv2()实现。
问题四:求与卷积层相连那层的权值、偏置值导数。
前面3个问题分别求得了输出层的误差敏感值、从pooling层推断出卷积层的误差敏感值、从卷积层推断出pooling层的误差敏感值。下面需要利用这些误差敏感值模型中参数的导数。这里没有考虑pooling层的非线性激发,因此pooling层前面是没有权值的,也就没有所谓的权值的导数了。现在将主要精力放在卷积层前面权值的求导上(也就是问题四)。
假设现在需要求第l层的第i个通道,与第l+1层的第j个通道之间的权值和偏置的导数,则计算公式如下:
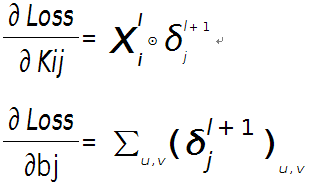

(上面英文描述,matlab的conv2()是数学卷积,内部会把delta矩阵翻转180。他采用matlab conv2()做CNN的卷积计算,求出Kij后转180,前向探索时就不用再转了。如果使用tensorflow.nn.conv2d(),不翻转,实际是求互相关。)
其中符号⊙表示矩阵的相关操作,可以采用conv2()函数实现。在使用该函数时,需将第l+1层第j个误差敏感值翻转。
例如,如果第l层某个通道矩阵i大小为4×4,如下:
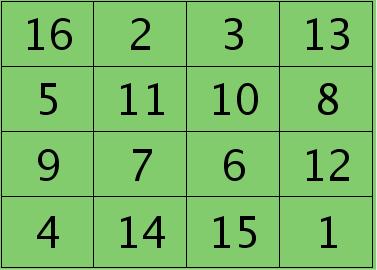
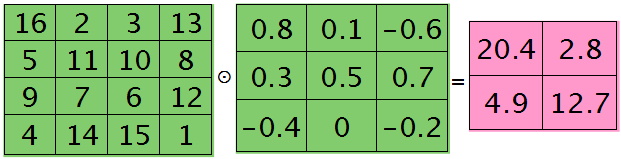
第l+1层第j个特征的误差敏感值矩阵大小为3×3,如下:

很明显,这时候的特征Kij导数的大小为2×2的,且其结果为:
# coding=utf-8
import os
os.environ["TF_CPP_MIN_LOG_LEVEL"]='2' # 只显示 warning 和 Error
import numpy as np
import tensorflow as tf
trainData_in=np.array([[16,2,3,13],\
[5,11,10,8],\
[9,7,6,12],\
[4,14,15,1]])
trainData_in=np.reshape(trainData_in,[-1,2,2,1])#np not tf
print(np.shape(trainData_in))
print(trainData_in)
print(np.sum(trainData_in,3))
print(np.reshape(trainData_in,[-1,2,2]))
print(trainData_in[:,:,:,0])
print(np.sum(trainData_in,1))
print(np.sum(trainData_in,2))
print(np.sum(trainData_in,(0,1)))
###CNN:
def nabla_kij(k,i,j,xi,deltaj):
deltaj=deltaj[k,:,:,j]
deltaj=np.reshape(deltaj,[list(deltaj.shape)[0],list(deltaj.shape)[1],1,1])
xi=xi[k:k+1,:,:,i:i+1]
return tf.nn.conv2d(xi,deltaj,strides=[1,1,1,1],padding='VALID')
x=np.reshape(trainData_in,[-1,4,4,1])
delta=np.array([[0.8,0.1,-0.6],[0.3,0.5,0.7],[-0.4,0,-0.2]])
delta=np.reshape(delta,[1,list(delta.shape)[0],list(delta.shape)[1],1])
x=np.float32(x)
sess=tf.Session()
nabla_kij=sess.run(nabla_kij(0,0,0,x,delta))
print(nabla_kij)
print(nabla_kij[0,:,:,0])
nabla_k=np.zeros([2,2,1,2])
nabla_k[:,:,0,0]+=nabla_kij[0,:,:,0]
print(nabla_k)
而此时偏置值bj的导数为1.2 ,将j区域的误差敏感值相加即可(0.8+0.1-0.6+0.3+0.5+0.7-0.4-0.2=1.2),因为b对j中的每个节点都有贡献,按照多项式的求导规则(和的导数等于导数的和)很容易得到。
为什么采用矩阵的相关操作就可以实现这个功能呢?由bp算法可知,l层i和l+1层j之间的权值等于l+1层j处误差敏感值乘以l层i处的输入,而j中某个节点因为是由i+1中一个区域与权值卷积后所得,所以j处该节点的误差敏感值对权值中所有元素都有贡献,由此可见,将j中每个元素对权值的贡献(尺寸和核大小相同)相加,就得到了权值的偏导数了(这个例子的结果是由9个2×2大小的矩阵之和),同样,如果大家动笔去推算一下,就会明白这时候为什么可以用带’valid’的conv2()完成此功能。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









