







文章出处
BEVFormer这篇文章很有划时代的意义,改变了许多视觉领域工作的pipeline[2203.17270] BEVFormer: Learning Bird's-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers (arxiv.org)![]() https://arxiv.org/abs/2203.17270
https://arxiv.org/abs/2203.17270
BEV (Bird's Eye View)
即鸟瞰图通常用于描述地面上的物体、车辆、行人以及其他障碍物的位置和运动,含有丰富的特征。在自动驾驶系统中,BEV可以帮助车辆更好地理解周围的车辆和行人的位置,从而更安全地进行驾驶决策。
BEVFormer
这是一种基于Transformer的BEV编码器,从多视角摄像头和历史BEV特征中聚合时空特征,即时空编码,注意力机制用来融合时空信息。
文中提到了三个关键点
-
网格状BEV查询,通过灵活的注意机制融合空间和时间特征
-
空间交叉注意模块,用于聚合来自多摄像头图像的空间特征
-
时间自注意模块,来自RNN的思想,用于从历史BEV特征中提取时序信息,(移动物体的速度估计和遮挡物体的检测)递归操作实现的准确速度预测
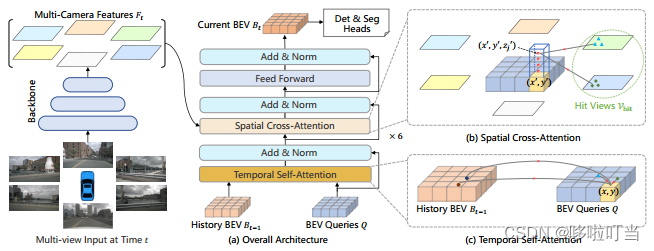
上面这个是文章中给出的示意图。输入数据是六个摄像头在相同时间段内的数据,每个时刻对应了六张图表示周围的空间。
具体工作流程
先对前一个时刻的BEV特征做查询结合上当前的时刻特征,这样就是能够学习到时序关系,输出的BEV query再空间交叉注意力查询多摄像头的特征信息,生成当前时间戳的BEV特征bev_embedding。
loss和损失评估
匈牙利算法做框匹配,利用已知的框位和模型框选计算L1 loss,结合分类损失平均最小
文中的关键概念解析
空间交叉注意力的概念
每个BEV查询只和感兴趣区域内的特征做交互,减少计算需要,也不会损失很多关键信息,学习效果也可以比全局注意力机制更强。这是基于可变注意力Deformable Attention的一个改进。首先操作是升为柱状的查询,不同高度的点只会对应某几个视角下2D图片的几个点位置,只对这些区域做查询,太高或太低导致不出现在2D图片中的投影点就不查询。
时间自注意力的概念
BEV查询会交互两个特征信息,当前的BEV和历史的BEV,比较特例的是时间序列的第一个样本不包含时间信息。操作是先将BEV查询Q和t-1时刻的特征对齐。这是因为车在运动,前后时刻的特征在空间上不对齐,使用车辆的旋转角度和偏移信息数据来做特征对齐。车周围的物体运动依靠注意力机制的学习实现对齐。文中提到的偏移量是一个车在运动时造成画面中特征的偏移值,这个根据自注意力学习得到,偏移量是对于参考点的一个修正作用。
BEV Quires
BEV中自注意力查询的方式:每次的操作在平面中查询一块的H,W大小网格中的信息,查询前对BEV查询Q做位置嵌入,目的是用于查询得到BEV特征图
应用
-
3D目标检测,利用得到的BEV特征作为3D检测头输入,实现3D边框的检测和速度预测,无需后处理。
-
地图分割,设计2D分割头,类似语义分割,利用掩码解码器做类别查询,实现车辆,道路,车道线等划分
代码部分的一些解读
观察代码部分,可以发现其中先分别构建构建分类和回归的分支。
对于目标检测和边缘标注任务,将模型输出的当前bev_embedding特征做一个解码。
用到了多层的Decoder嵌套,每一层都会有计算分类和回归结果,除了初始选定参考点,每一次都是用回归的结果对前面参考点的一个优化,最终得到分类。具体是先通过自注意力更新query以及参考点做可变形的注意力,酸菜查询特征,再调用回归分支计算得到预测输出,输出的就是预测框的坐标和相关的运动信息,拿来更新点。
框选的实现是根据已经解码出来的一组点数据,结合做3D格式转换实现视频中框选和标注

















 2069
2069











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











