







 本文介绍了如何使用带掩码的Autoencoder进行无监督学习,通过CNN和残差网络结构处理MNIST手写数字图片,实验目标是学习图片特征并实现图像还原。作者提供了构建掩码函数、神经网络模型以及训练和测试流程的详细代码示例。
本文介绍了如何使用带掩码的Autoencoder进行无监督学习,通过CNN和残差网络结构处理MNIST手写数字图片,实验目标是学习图片特征并实现图像还原。作者提供了构建掩码函数、神经网络模型以及训练和测试流程的详细代码示例。
开源仓库
JJLi0427/CNN_Autoencoder (github.com)![]() https://github.com/JJLi0427/CNN_Autoencoder
https://github.com/JJLi0427/CNN_Autoencoder
项目介绍
Autoencoder(自编码器)是一种无监督学习算法,通常用于学习数据的有效表示或特征提取。它由两部分组成:编码器(encoder)和解码器(decoder)。
编码器将输入数据转换为潜在空间中的低维表示,也称为编码或隐藏层表示。编码器的任务是将输入数据压缩到一个较小的特征空间,捕获输入数据的关键特征。解码器将编码后的表示映射回原始输入空间,并尝试重构原始输入。解码器的目标是从编码器的输出中重建一个尽可能接近原始输入的重构。
Autoencoder的训练过程旨在最小化重构误差,使重构数据尽可能接近原始输入数据。通过这种方式,Autoencoder可以学习数据的压缩表示,有助于数据去噪、降维、特征学习等任务。
之前相关的博客
对于我们的这个小实验,希望使用带掩码的Autoencoder来学习图片的特征,实现图片的还原,我们将使用手写数据集做实验
大致流程图
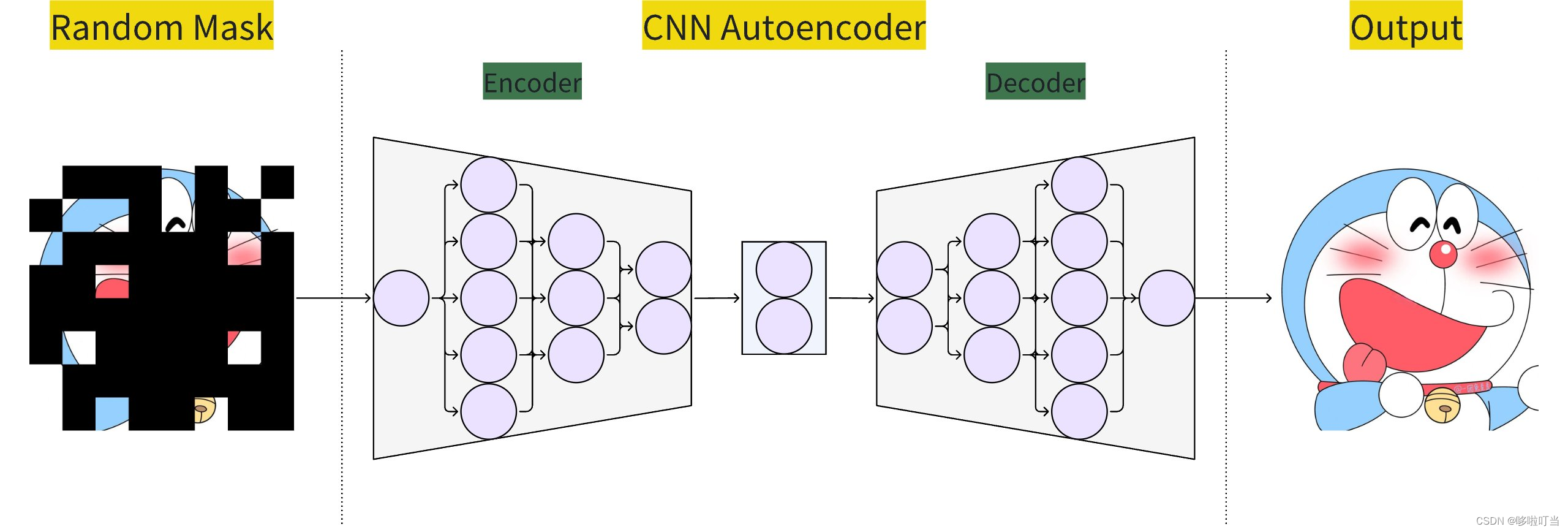
代码
1.构建掩码函数
从数据集中读取图片然后最随机的源码,同时保存原图方便做对比
def mask_image(data_loader, mask_params):
height = mask_params['height']
width = mask_params['width']
num_patches = mask_params['num_patches']
mask_id = mask_params['mask_id']
mask_data_loader = []
copy_data_loader = []
for data, label in data_loader:
masked_image = torch.zeros_like(data)
for i in range(num_patches):
row = i // (height // PATCH_SIZE)
col = i % (width // PATCH_SIZE)
if i in mask_id:
masked_image[:, :, row * PATCH_SIZE:(row + 1) * PATCH_SIZE, col * PATCH_SIZE:(col + 1) * PATCH_SIZE] = 0
else:
masked_image[:, :, row * PATCH_SIZE:(row + 1) * PATCH_SIZE, col * PATCH_SIZE:(col + 1) * PATCH_SIZE] = data[:, :, row * PATCH_SIZE:(row + 1) * PATCH_SIZE, col * PATCH_SIZE:(col + 1) * PATCH_SIZE]
mask_data_loader.append((masked_image, label))
copy_data_loader.append((data, label))
return mask_data_loader, copy_data_loader2.神经网络部分
这里除了使用卷积网络之外还加入了残差网络,效果更好
class ResidualBlock(nn.Module):
def __init__(self, in_channels):
super(ResidualBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, in_channels, 3, stride=1, padding=1)
self.relu = nn.ReLU(True)
self.conv2 = nn.Conv2d(in_channels, in_channels, 3, stride=1, padding=1)
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.relu(out)
out = self.conv2(out)
out += residual
out = self.relu(out)
return out
class AutoEncoder(nn.Module):
def __init__(self):
super(AutoEncoder, self).__init__()
self.encoder = nn.Sequential(
nn.Conv2d(1, 16, 3, stride=1, padding=1), # b, 16, 28, 28
nn.ReLU(True),
ResidualBlock(16),
nn.Conv2d(16, 16, 3, stride=3, padding=1), # b, 16, 10, 10
nn.ReLU(True),
nn.MaxPool2d(2, stride=2), # b, 16, 5, 5
ResidualBlock(16),
nn.Conv2d(16, 12, 3, stride=1, padding=1), # b, 12, 5, 5
nn.ReLU(True),
nn.Conv2d(12, 8, 3, stride=2, padding=1), # b, 8, 3, 3
nn.ReLU(True),
nn.MaxPool2d(2, stride=1) # b, 8, 2, 2
)
self.decoder = nn.Sequential(
nn.ConvTranspose2d(8, 8, 3, stride=2, padding=1), # b, 8, 3, 3
nn.ReLU(True),
ResidualBlock(8),
nn.ConvTranspose2d(8, 12, 3, stride=2, padding=1), # b, 12, 5, 5
nn.ReLU(True),
nn.ConvTranspose2d(12, 16, 2, stride=2), # b, 16, 10, 10
nn.ReLU(True),
ResidualBlock(16),
nn.ConvTranspose2d(16, 1, 3, stride=3, padding=1), # b, 1, 28, 28
nn.Sigmoid()
)
def forward(self, x):
encoded = self.encoder(x)
decoded = self.decoder(encoded)
return encoded, decoded3.训练函数
def train(model, optimizer, criterion, train_loader_masked, train_loader_origin, mask_params):
model.train()
training_loss = []
for i, ((mask_data, _), (train_data, _)) in enumerate(zip(train_loader_masked, train_loader_origin)):
mask_data = mask_data.to(device)
train_data = train_data.to(device)
optimizer.zero_grad()
_, decoded = model(mask_data)
loss = criterion(decoded, train_data)
loss.backward()
optimizer.step()
training_loss.append(loss.data.cpu().numpy())
avgloss = np.mean(training_loss)
return avgloss
def test(epoch, model, criterion, test_loader_masked, test_loader_origin, mask_params):
model.eval()
testing_loss = []
compare = []
with torch.no_grad():
for i, ((mask_data, _), (test_data, _)) in enumerate(zip(test_loader_masked, test_loader_origin)):
mask_data = mask_data.to(device)
test_data = test_data.to(device)
_, decoded = model(mask_data)
loss = criterion(decoded, test_data)
testing_loss.append(loss.data.cpu().numpy())
if i == 0 and (epoch == 0 or (epoch+1) % SHOW_PER_EPOCH == 0):
for j in range(SHOW_IMG_COUNT):
compare_img = torch.cat([test_data[j:j+1], mask_data[j:j+1], decoded.view(BATCH_SIZE, 1, 28, 28)[j:j+1]])
compare.append(compare_img)
avgloss = np.mean(testing_loss)
return compare, avgloss4.其他部分
import os
import torch
import random
import numpy as np
import matplotlib.pyplot as plt
from torch import nn, optim
from torchvision import datasets, transforms
from torchvision.utils import save_image
EPOCH_COUNT = 100
BATCH_SIZE = 1024
LR = 0.001
SHOW_PER_EPOCH = 10
SHOW_IMG_COUNT = 5
PATCH_SIZE = 2
MASK_RATE = 0.75
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
if __name__ == "__main__":
if not os.path.exists('./data'):
os.mkdir('./data')
train_loader = torch.utils.data.DataLoader(datasets.MNIST('./data',
train=True,
download=True,
transform=transforms.ToTensor()),
batch_size=BATCH_SIZE,
shuffle=True)
test_loader = torch.utils.data.DataLoader(datasets.MNIST('./data',
train=False,
download=True,
transform=transforms.ToTensor()),
batch_size=BATCH_SIZE,
shuffle=True)
_, height, width = train_loader.dataset[0][0].shape
num_patches = height // PATCH_SIZE * width // PATCH_SIZE
num_masked_patches = int(num_patches * MASK_RATE)
mask_params = {
'height': height,
'width': width,
'num_patches': num_patches,
'mask_id': None,
}
autoencoder = AutoEncoder()
model = AutoEncoder().to(device)
optimizer = optim.Adam(model.parameters(), lr=LR)
# optimizer = optim.SGD(model.parameters(), lr=LR)
criterion = nn.MSELoss()
comparison = []
train_loss_list = []
test_loss_list = []
for epoch in range(EPOCH_COUNT):
mask_params['mask_id'] = random.sample(range(mask_params['num_patches']), num_masked_patches)
train_loader_masked, train_loader_origin = mask_image(train_loader, mask_params)
train_loss = train(model, optimizer, criterion, train_loader_masked, train_loader_origin, mask_params)
train_loss_list.append(train_loss)
test_loader_masked, test_loder_origin = mask_image(test_loader, mask_params)
compare, test_loss = test(epoch, model, criterion, test_loader_masked, test_loder_origin, mask_params)
test_loss_list.append(test_loss)
comparison.extend(compare)
print(f'Epoch: {epoch + 1:3d} | train loss: {train_loss:.6f} | test loss: {test_loss:.6f}')
all_comparisons = torch.cat(comparison, dim=0)
name = 'show_per_' + str(SHOW_PER_EPOCH) + 'epoch.png'
save_image(all_comparisons.cpu(), name, nrow=SHOW_IMG_COUNT*3)
plt.plot(range(EPOCH_COUNT), train_loss_list, label='train loss')
plt.plot(range(EPOCH_COUNT), test_loss_list, label='test loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Image MSE Loss')
plt.legend()
plt.savefig('image_loss.png')
plt.close()
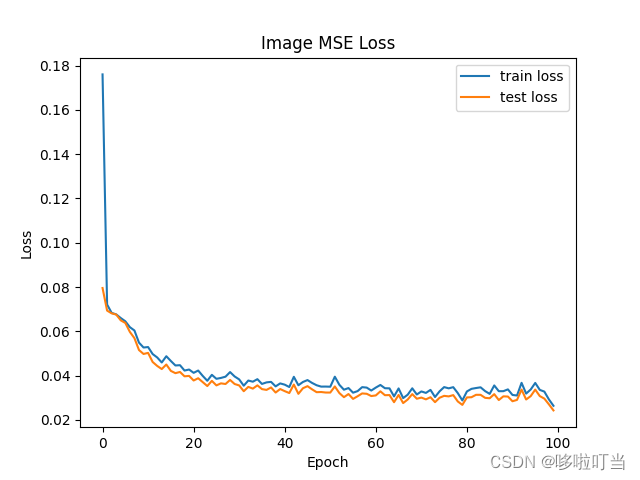
实验结果
loss图
过程中的样例截图


















 5525
5525











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











