







【深度学习项目】用于图像压缩和去噪的深度 CNN 自动编码器(代码详解)
一、简介
🐼 自动编码器:
自动编码器(Autoencoder)是一种无监督学习算法,用于数据的降维和特征提取。它由一个编码器和一个解码器组成,可以通过将输入数据压缩成低维表示,然后再将其解压缩回原始数据空间来重构输入数据。
自动编码器的目标是尽可能地减小重构误差,使得解码器能够生成与输入数据相似的输出。为了达到这个目标,编码器将输入数据映射到潜在空间(也称为编码空间)中的低维表示,而解码器则将该低维表示映射回原始数据空间。

自动编码器的训练过程通常使用无监督学习的方法,即仅使用输入数据作为训练样本,而没有对应的标签。训练过程中,编码器和解码器的参数通过最小化重构误差来进行优化。重构误差可以使用均方差(Mean Squared Error)或其他适当的损失函数来度量。
自动编码器可以应用于多种任务,包括数据降维、特征提取、数据去噪、异常检测等。在数据降维任务中,自动编码器可以将高维数据压缩到低维表示,以便可视化或更高效地处理数据。在特征提取任务中,自动编码器可以学习到输入数据的有用特征表示,从而提高后续任务的性能。在数据去噪任务中,自动编码器可以通过学习重构干净数据来过滤掉输入数据中的噪声。在异常检测任务中,自动编码器可以学习正常数据的表示,然后用于检测与正常模式不符的异常数据。
🐼 卷积神经网络(CNN):
卷积神经网络(Convolutional Neural Network,CNN)是一种广泛应用于计算机视觉和图像处理任务的神经网络模型。与传统的全连接神经网络相比,CNN在处理具有网格结构的数据(如图像)时表现出色。
CNN的核心思想是通过卷积层、池化层和全连接层等组件来实现特征提取和分类。下面是CNN的主要组成部分:
- 卷积层(Convolutional Layer):卷积层是CNN的核心。它使用一组可学习的滤波器(卷积核)对输入数据进行卷积操作,从而提取输入数据的局部特征。每个滤波器通过滑动窗口的方式在输入数据上进行卷积操作,生成一系列的特征映射(Feature Map)。
- 激活函数(Activation Function):在卷积层之后,一般会应用一个非线性的激活函数,如ReLU(Rectified Linear Unit),来引入非线性特性。激活函数的作用是增加网络的表达能力,并且有助于提取非线性特征。
- 池化层(Pooling Layer):池化层用于降低特征映射的空间尺寸,减少参数数量,并提取主要特征。常用的池化操作是最大池化(Max Pooling),它从每个局部区域中选择最大值作为池化结果。池化操作还可以提高网络的平移不变性,使得网络对输入的微小位置变化具有鲁棒性。
- 全连接层(Fully Connected Layer):在经过多个卷积层和池化层之后,得到的特征映射被拉平成一维向量,并通过一个或多个全连接层进行分类或回归操作。全连接层的每个神经元与上一层的所有神经元相连,参数量较大。
在CNN中,通过堆叠多个卷积层、激活函数、池化层和全连接层,可以逐渐提取出输入数据的高层次特征表示,从而实现对图像内容的理解和识别。
🐼 CNN自动编码器:
CNN自动编码器是将卷积神经网络(CNN)与自动编码器(Autoencoder)结合的模型。它可以用于图像降噪、图像去噪、特征提取等任务。

CNN自动编码器的结构与传统的自动编码器类似,但在编码器和解码器中使用了卷积层和反卷积层(也称为转置卷积层)来处理图像数据的空间结构。以下是CNN自动编码器的一般结构:
- 编码器(Encoder):编码器由一系列的卷积层、池化层和激活函数组成。卷积层用于提取输入图像的特征,通过逐渐减小空间维度和增加通道数,将输入图像压缩成低维的特征表示。通常在编码器的最后一层添加一个全连接层,将特征映射转换为更低维的表示。
- 解码器(Decoder):解码器是编码器的逆过程,由一系列的反卷积层和激活函数组成。反卷积层(转置卷积层)用于将低维的特征表示映射回原始图像的空间维度和通道数。最后一层的激活函数通常使用sigmoid或tanh函数来保证解码器输出的像素值在合适的范围内。
- 损失函数(Loss Function):常用的损失函数是均方差(Mean Squared Error),它衡量解码器输出与原始图像之间的重构误差。优化目标是最小化重构误差,使得解码器能够生成与输入图像相似的输出。
通过训练CNN自动编码器,可以学习到输入图像的有用特征表示,并通过解码器重构图像。编码器部分可以作为特征提取器使用,而解码器部分可以用于生成新的图像样本。
CNN自动编码器在图像处理任务中具有广泛的应用,例如图像降噪,它可以学习到图像的清晰结构并去除噪声;图像去噪,它可以学习到干净图像的表示,并通过解码器生成去噪后的图像;特征提取,它可以学习到图像的有用特征表示,可以用于后续的图像分类、目标检测等任务。
二、用于图像压缩的CNN自动编码器
图像压缩是通过减少图像数据的冗余性和信息损失来减小图像文件的大小的过程。CNN(卷积神经网络)自动编码器是一种有效的方法,可用于图像压缩和重建。
CNN自动编码器由编码器和解码器两部分组成。编码器将输入图像逐渐压缩到一个较低维度的表示,而解码器则将该低维度表示恢复到原始图像的尺寸。
⚙️自动编码器的流程:
*️⃣ 输入图像 -> 编码器 -> 压缩表示 -> 解码器 -> 重构输入图像
• 自动编码器需要一个输入数据样本,这里我们考虑的是一个图像,并将其输入到编码器网络中。
• 编码器网络由若干层组成,通常包括卷积层、池化层和全连接层。这些层逐步减少空间维度,从输入数据中提取有意义的特征。
• 编码器网络的最后一层产生输入数据的压缩表示。
• 编码阶段的压缩表示被传递到解码器网络中。
• 解码器网络与编码器网络是对称的,由全连接层、上采样层和有时转置的卷积层组成。它采用压缩的表示方法,并逐渐增加空间维度,以重建原始输入数据。
• 解码器网络的最后一层生成重构的输出,其目的是与原始输入数据密切相似。
▶️ 以下是用于图像压缩的CNN自动编码器的python代码在jupyter notebook中的实现:
1. 导入库
import numpy as np
import matplotlib.pyplot as plt
from keras import Sequential
from keras.layers import Dense, Conv2D, MaxPooling2D, UpSampling2D
from keras.datasets import mnist
🤖 代码详解:
import numpy as np: 导入了numpy库,并将其命名为np,这是一个常用的科学计算库,用于处理数组和矩阵等数值运算。import matplotlib.pyplot as plt: 导入了matplotlib.pyplot模块,并将其命名为plt,它是matplotlib库中的一个子模块,用于绘制图形和可视化数据。from keras import Sequential: 从keras库中导入了Sequential类,Sequential类是用于构建深度神经网络模型的基本模块。from keras.layers import Dense, Conv2D, MaxPooling2D, UpSampling2D: 从keras.layers模块中导入了Dense、Conv2D、MaxPooling2D和UpSampling2D等类,这些类用于构建神经网络的各种层。from keras.datasets import mnist: 从keras.datasets模块导入了mnist模块,mnist模块提供了加载手写数字数据集MNIST的功能。
这段代码导入了所需的库和模块,为后续的代码提供了必要的功能和工具。
2. 加载MNIST数据
(x_train, _), (x_test, _) = mnist.load_data()
🤖 代码详解:
这行代码加载了MNIST手写数字数据集,并将数据集分为训练集和测试集:
MNIST数据集是一个经典的机器学习数据集,包含了一系列的手写数字图像。这里使用的mnist.load_data()函数是keras库中的一个功能,用于从网络下载并加载MNIST数据集。
具体来说,这行代码执行的操作如下:
• 从MNIST数据集中加载训练数据集,赋值给x_train。
• 同时从MNIST数据集中加载测试数据集,赋值给x_test。
在这之后,你可以使用x_train和x_test来访问训练集和测试集的图像数据,进行后续的处理和分析。
3. 预处理图像数据
👉🏻 对图像数据进行归一化:
x_train = x_train.astype('float32') / 255
x_test = x_test.astype('float32') / 255
🤖 代码详解:
这段代码对图像数据进行了归一化处理。在机器学习和深度学习中,对输入数据进行归一化是一种常见的预处理步骤。归一化可以将数据缩放到一个特定的范围内,通常是[0, 1]或[-1, 1]之间。这有助于提高模型的训练效果和收敛速度。
这段代码执行了以下操作:
x_train = x_train.astype('float32'): 将x_train的数据类型转换为float32,这是为了进行后续的除法运算。x_test = x_test.astype('float32'): 将x_test的数据类型转换为float32,同样是为了进行后续的除法运算。/ 255: 将每个像素的数值除以255,将像素值缩放到[0, 1]的范围内。由于MNIST图像的像素值范围是0到255,所以除以255可以实现这一目的。
通过执行这些操作,x_train和x_test中的图像数据被归一化到了[0, 1]的范围内,可以更好地用于神经网络的训练和评估。
👉🏻 重塑输入图像数据:
x_train = x_train.reshape(len(x_train), 28, 28, 1)
x_test = x_test.reshape(len(x_test), 28, 28, 1)
x_test.shape
👾 运行结果:
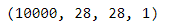
🤖 代码详解:
这段代码对训练集和测试集的图像数据进行了形状重塑操作。在深度学习中,特别是在使用卷积神经网络(CNN)处理图像数据时,通常要求输入数据的形状符合特定的要求。对于MNIST数据集中的图像数据,CNN通常要求其形状为(样本数, 图像高度, 图像宽度, 通道数)。
x_train = x_train.reshape(len(x_train), 28, 28, 1): 将x_train的形状从(样本数, 图像高度, 图像宽度)重塑为(样本数, 28, 28, 1),其中28是图像的高度和宽度,1表示图像的通道数,这里是灰度图像,所以通道数为1。x_test = x_test.reshape(len(x_test), 28, 28, 1): 将x_test的形状从(样本数, 图像高度, 图像宽度)重塑为(样本数, 28, 28, 1),同样的操作,将图像的高度、宽度和通道数设置为28、28和1。
最后,代码通过x_test.shape打印出了x_test的形状。由于前面对x_test进行了形状重塑,所以输出的形状为(样本数, 图像高度, 图像宽度, 通道数),即(10000, 28, 28, 1)。表示测试集中共有10000个样本,每个样本的图像大小为28x28,通道数为1。
4. 探索性数据分析
👉🏻 查看输入图像的样子:
# 随机选择一个图像的索引
index = np.random.randint(len(x_test))
# 显示图像
plt.imshow(x_test[index].reshape(28,28))
plt.gray()
👾 运行结果:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 876
876











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











