







十分遗憾要以这样一个四不像的内容作为博客开始的起点,当以后回首往事时,这可能会成为我最不愿接受的一个事实。对于在还不熟悉博客的规范和一些操作前就开始正文我深感抱歉,这篇文章可能在结构上会非常粗糙,但我保证作为一个开始,我会写得很详细。我还想申明的是,这些文字你读起来感觉会比较奇怪,但这并不是所谓的英文语法格式。
对于这次及以后的内容,我想表明我并不是想说明我的理解比别人更好,相反,我是一个很菜的人,我写东西只是为了给自己所学一个总结,也给才接触这些东西的人一个大致的了解。对于不了解的地方,我会在文中说明,也希望有人通过给我发邮件帮我和大家解决所遇到的问题。文中一些例子,数据和图形我会摘抄其他人的内容,但此只作为一个让大家理解的例子。对专业知识的描述可能看上去并不是很专业,但这只是为了让读者觉得通俗易懂。
神经网络近几年来随着计算机计算能力的提高,又火了起来。在机器学习这个领域,一说起神经网络,都会略有耳闻,说到神经网络,最大的特点就是它的每个Layer之间各个单元互连时的权值调节能力,这些权值参数都是可调的,而调节的结果就是使最后结果达到理想状态,我们通常把这个调节参数的过程叫做“训练”。网络是由人设计的,而这些参数并不会自己调节,这个调节是需要人们给予算法支持的。虽然我会一步一步的解释神经网络的大概思想,然后给出一个例子说明神经网络的BP算法是如何计算,最后推导式子由来,但我希望本文读者有梯度下降算法的知识。
下面是正文:
在LogisticRegression里面,我们使用了sigmoid函数。
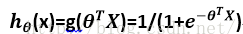
sigmoid函数原型如下:
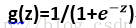
神经网络中的隐含单元使用了连续的sigmoid非线性函数来作为激活函数(activation function),而感知器使用阶梯函数这一非线性函数。这意味着神经网络函数关于神经网络参数是可微的,这个性质在神经网络的训练过程中起着重要的作用。
如果网络中的所有隐含单元的激活函数都取线性函数,那么对于任何这种网络,我们总可以找到一个等价的无隐含单元的网络。这是由于连续的线性变换的组合本身是一个线性变换。然而,如果隐含单元的数量小于输人单元的数量或者小于输出单元的数量,那么网络能够产生的变换不是最一般的从输入到输出的线性变换,因为在隐含单元出的维度降低造成了信息丢失。通常情况下,我们对线性单元的多层神经网络几乎不感兴趣。
在这里我举个例子来让初次接触神经网络的人对其有个了解,这个例子我觉得不该像其他人那样把思想公式化,用其展现自己深厚的数学功底,结果就是用一大篇累赘描述了一个并不是很简单的问题,让复杂的问题更加复杂。神经网络如果很复杂地描述,无论是从整体角度建模还是局部过程,都可以列出很多复杂的数学公式,但是为了让初次接触的人有个整体的认识,这里给一些简单的例子,但这并不代表神经网络的全部。
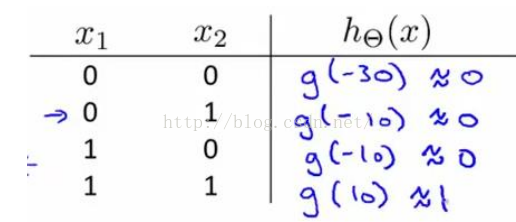
我可以用这样的一个神经网络来表示 “AND”函数:
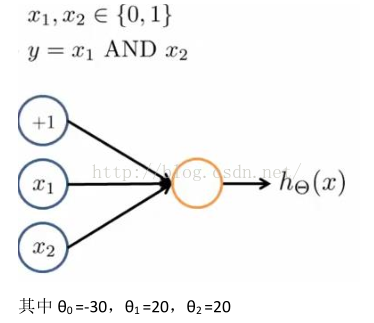
我们输出的是
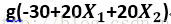
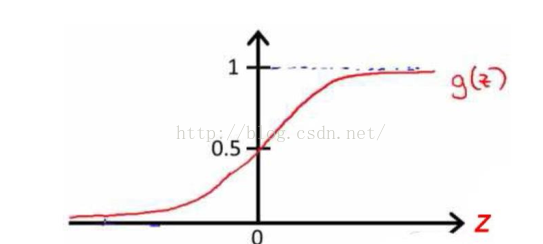
而g(z)的函数图像如下:
所以AND函数的真值表为:
这样以来,我们给出类似的几个神经元:

他们的真值表我相信你们能够自己总结出来,和我们所了解的真值表并无什么区别。
那么有了这几种神经元之后,我想要说明的是,他们可以组合成一个复杂的结构来实现更为复杂的运算。例如我们实现XNOR功能(输入的两个值必须一样,均为1或则均为0)
即: XNOR=(X1 AND X2) OR ((NOT X1) AND (NOT X2))
首先要构造一个能表达(NOT X1) AND (NOT X2) 部分的神经元:

然后将表示AND 的神经元和表示(NOT X1) AND (NOT X2)的神经元以及表示OR的神经元进行组合:

这样我们就得到了一个能实现XNOR运算符功能的神经网络。按这种方法我们可以逐渐构造出越来越复杂的函数,也能得到更加厉害的特征值。这就是神经网络的厉害之处。
____________________________________________________________________________________________
以上是简单介绍一点神经网络的概念。现在来说BP算法(两层为例)。
对于层数,有很多种说法,有些人把输入,隐含层,输出层都算作一层;有些觉得单一的隐含层当作层数;我推荐的计算方法是看可调节参数的层数。下面言归正传。
说简单点,分为BP算法分为两个步骤,
第一个步骤是:把输入沿网络前向传播。
前向传播很好理解,我想要调参数,最起码得有个输出结果。初始化各项参数后,我的神经网络通过预设的流程跑了一遍,得到了输出结果。
第二个步骤是:使误差沿网络反向传播。
然而,这个结果可能跟我所希望的结果有很大误差。所以我希望网络通过此误差返回去一层一层修改参数,参数的修改过程也可以说是神经网络的训练过程,当参数修改后,我的输出会让误差减小。
这种思想并不是让人很难接受,这种说法让人直观上有了个概念,那么,把问题具体化,应该怎么做呢?我并不想直接推导公式,先给出一个类似于之前介绍神经网络时的简单的例子,做个简单的计算,这样会让大家更清晰,在此希望大家能自己亲自动手计算一次。
例子如下:
第一步:先初始化一些量,这些量也许你会感到陌生,这也就是我觉得读者应该了解梯度下降算法的原因。
这些变量包括:
1.权重值w,开始均设置为0.1
2.偏移值θ,开始均设置为0.2 (这个参数就是梯度下降里面的θ subscript 0)
3.学习率l,设置为0.4 (这个参数就是地图下降里面的学习速度,可以理解成下山的步长)
4.假设就一个样本,是一个二维的输入,x1=0,x2=0.08。
还有一点想说的是,初始化的参数一般为(-1,1)之间的随机产生的小数。提醒一点:初始化权重时,最开 始不能将所有的权重设置为0,这会导致训练后所有权重相同,整个网络的隐含层就失去了作用,不能产生 功能强大的网络。
第二步:初始化完毕了,开始计算。
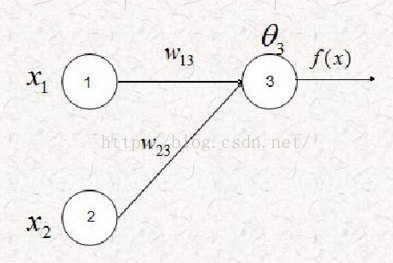
我们暂称之为网络1, 那么相印的参数计算如何呢? 下面给出计算公式
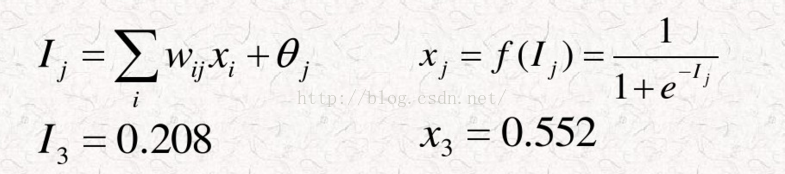
现在解释下其中含义,I3是由x1,x2和他们的权值相乘相加后再加上一个偏移值得到的。I3传入节点3的运算方式是f(x), 这里f(x),我们可以称之为激活函数,本例中才用的是sigmoid。运算后可以得到节点3输出的是x3=0.552。
下面给出网络的另外一部分:

我们称之为网络2,同理,网络2的计算公式如下:
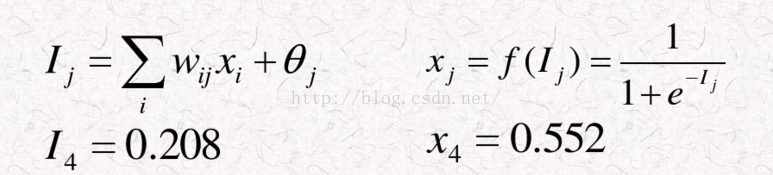
下面给出网络后续衔接图:
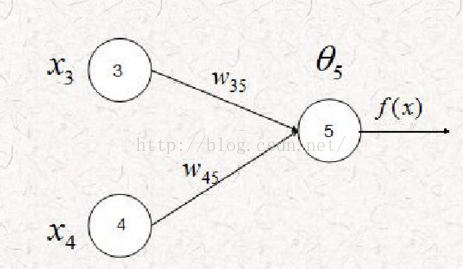
对应计算公式为:
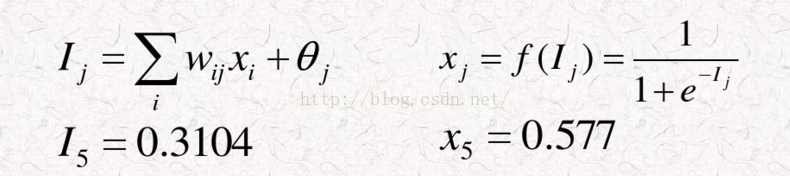
到这里为止,前向传播就结束了。那么问题来了,所有参数都是我自己给的随机初始化值,输出结果跟实际 值肯定有差距,那么,BP算法的计算过程是如何的呢?也就是,我训练该神经网络的过程是怎样的?
BP算法计算过程:
假设输出值O5=x5=0.577,而实际的这个值我们设置为T5=0
那么在节点5这个位置,我们得到输出层节点5的误差为δ5=O5*(1-O5)*(T5-O5)。计算出δ5=-0.1408
这个误差是上一层的节点3和节点4给予的,但是对于反向传播来说,我们把问题反着看,节点5有误差,那 么这个误差就会独立的影响节点3和节点4。
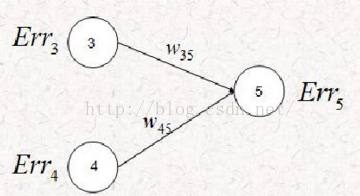
我们已经知道,隐藏层节点3的输出与隐藏层节点4的输出相同。O3=x3=O4=x4=0.552,权重均为0.1
我们给出隐藏层节点j的误差计算公式:

这样以来,上图中计算结果 Err3=Err4= -0.0035
接下来要做的事情就是调整权重,下面给出公式:
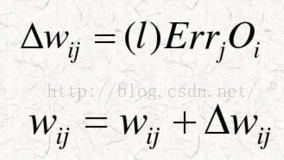
由此公式可以把网络中的其他权重都更新一遍:
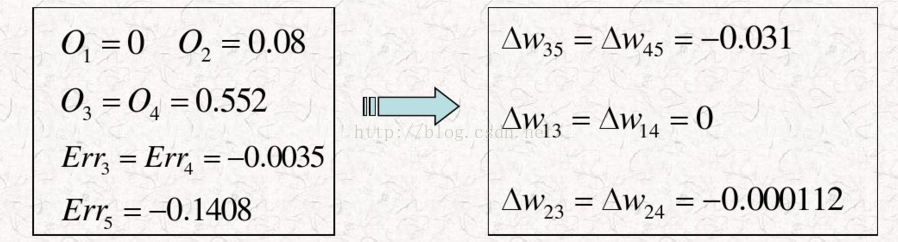
更新后,权重为:
W35=W45=0.069
W13=W14=0.1
W23=W24=0.999888
偏移值也需要更新,公式为:
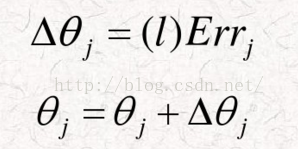
结果如下:
由
θ3=θ4=θ5=0.2 Δθ5=-0.05632 θ5=0.1436
Err3=Err4=-0.0035 → Δθ3=-0.0014 → θ3=0.1986
Err5=-0.1408 Δθ4=-0.0014 θ4=0.1986
到这里进行了一次BP算法。其中一些公式如果不深究会用即可。后续我会给出公式推导过程。
简单神经网络例子来自于Stanford University新版机器学习视频。
BP算法的计算距离我给出超链接:BP算法举例
下面我将给出BP算法的公式推导:
__________________________________________________________________________________________________________
在推导前,我先给该算法,它包含两层sigmoid单元的前馈网络的反向传播算法(随机梯度下降)
η是学习速度(例如0.05)。nin是网络输入的数量,nhidden是隐藏单元数,nout是输出单元数。
从单元i到单元j的输入表示为xji,单元i到单元j的权值表示为wji。
·创建具有nin个输入,nhidden个隐藏单元,nout个输出单元的网络
·初始化所有的网络权值为小的随机值(例如 -0.05和0.05之间的数)
·在遇到终止条件之前:
对于训练样例training_examples中的每个<x,t>(这里把x和t表为黑体代表向量,后面不重复):
把输入沿网络前向传播
1.把实例x输入网络,并计算网络中每个单元u的输出ou
使误差沿网络反向传播
2.对于网络的每个输出单元k,计算它的误差项δk
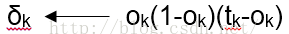
3.对于网络的每个隐藏单元h,计算它的误差项δk
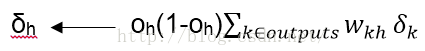
4.更新每个网络权值wji
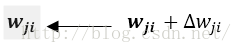
其中
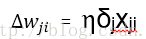
在推导过程中,有一些变量和下标,在这里给出具体含义:
●xji = 单元j的第i个输入
●wji = 与单元j的第i个输入相关联的权值
●netj =Σi wji xji(单元j的输入的加权和)
●oj = 单元 j 计算出的输出
●tj = 单元 j 的计算目标输出
●σ = sigmoid函数
●outputs = 网络最后一层的单元的集合
●Downstream(j) = 单元的直接输入中包含单元j的输出的单元的集合
我们设Ed是训练样例d的误差,通过对网络中所有输出单元的求和得到:

对每个训练样例d,利用关于这个样例的误差Ed的梯度修改权值。换句话说,对于每一个训练样例d,每个权wji被增加Δwji。
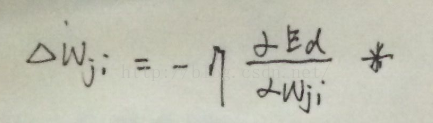
现在我们导出

由上式,我们剩下的任务就是为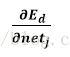
情况1:输出单元的权值训练法则
就像wji仅能通过netj影响网络一样,netj仅能通过oj影响网络。所以我们可以再次使用链式规则得出:
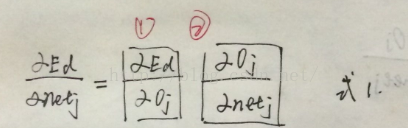
这个式子分为第一项和第二项。对第一项来说,除了当k=j时,其他所有输出单元k的倒数为0。所以我们不必对多个输出单元求和,只需设k=j。
所以对第一项:
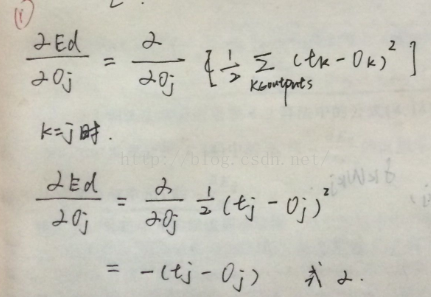
对第二项来说,就是sigmoid函数的倒数
而我们已经指出sigmoid函数的倒数为σ(netj)(1-σ(netj))
所以:
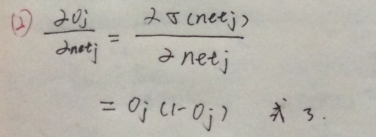
把式2和式3代入式1可以得到:
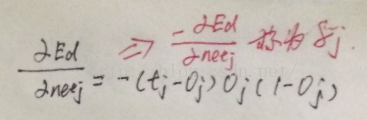
这里的δj我们在其他文中也看见过,其实这就是误差。
代回(*)式得

这个式子跟之前所看的BP算法过程更新结果对应:
以上是情况1,它给出的是输出单元的权值训练法则,下面将给出情况2。
情况2:隐藏单元的权值训练法则
输出的权值训练法则有了,那么隐藏单元的该怎么通过一个反向传播过程求解呢?
对于网络中的内部单元或则说隐藏单元的情况,推导wji必须考虑wji间接地影响网络输出,从而影响Ed。由于这个原因,我们发现定义网络中单元j的所有直接下游单元集合是有用的。什么叫直接下游单元集合,在第二部分具体事例中已经让大家清楚明白了,所以我不做多的解释。我们用Downstream(j)表示这样的单元集合。值得注意是,netj只能通过Downstream(j)中的单元影响网络输出(再影响Ed)。
推导如下:

最后两步骤,我们是用-δj表示了
整个推导到此完毕。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









