







Deeplab V1
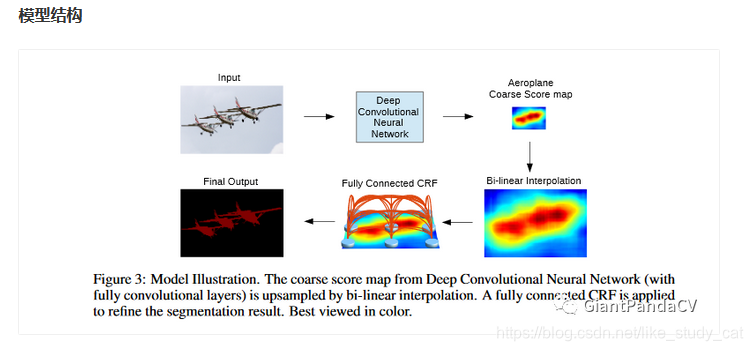
同时,我截取Caffe中的deeplabv1中的prototxt的网络结构可视化图:
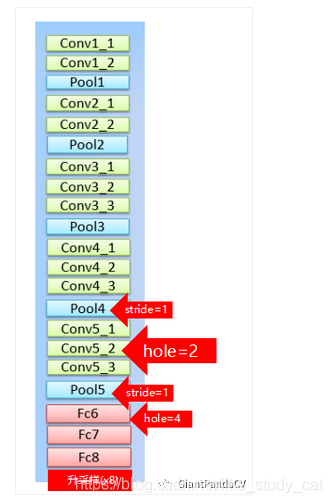
DeepLab的BackBone依赖于VGG16,具体改造方法就是:
- 将最后的全连接层FC6,FC7,FC8改造成卷积层。
- pool4的stride由2变成1,则紧接着的conv5_1,conv5_2和conv5_3中hole size为2。
- 接着pool5由2变成1,则后面的fc6中的hole size为4。
- fc7,fc8为标准的卷积。
- 由于空洞卷积算法让feature map更加精细,因此网络直接采用插值上采样就能获得很好的结果,不用去学习上采样的参数了(FCN中采用了de-convolution)。
核心问题
针对第一个问题,Deeplab提出了空洞卷积:空洞卷积的作用有两点,一是控制感受野,二是调整分辨率。这张图片截取自于有三AI公众号。
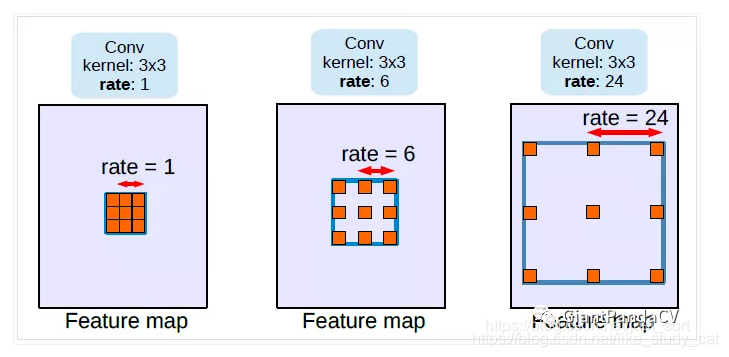
我们可以看到从左到右的hole大小分别是1,6,24,这个hole的意思就是卷积核内两个权重之间的距离。从图中可以看出,当比率为1的时候,空洞卷积退化为普通卷积。很明显,应用了空洞卷积之后,卷积核中心的感受野增大了,但是如果控制步长为1,特征图的空间分辨率可以保持不变。
针对第二个问题,我们设置滑动的步长,就可以让空洞卷积增大感受野的同时也降低分辨率。
引入CRF
首先是因为图像在CNN里面通过不断下采样,原来的位置信息会随着深度减少甚至消失。最后会导致分类结果变得十分平滑,但是我们需要细节更加突出的结果,可以看下面的图:
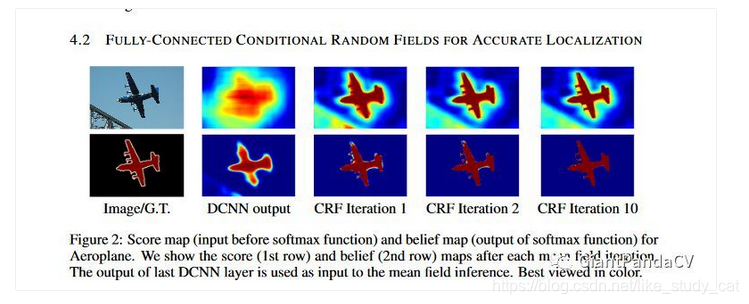 这里引入了CRF来解决这个问题,首先CRF在传统图像处理上主要做平滑处理。对于CNN来说,short-range CRFs可能会起到反作用,因为我们的目标是恢复局部信息,而不是进一步平滑图像。本文引入了全连接CRF来考虑全局信息。
这里引入了CRF来解决这个问题,首先CRF在传统图像处理上主要做平滑处理。对于CNN来说,short-range CRFs可能会起到反作用,因为我们的目标是恢复局部信息,而不是进一步平滑图像。本文引入了全连接CRF来考虑全局信息。

引入多尺度预测
和前面FCN的Skip Layer类似,在输入图片与前四个max pooling后添加MLP(多层感知机,第一层是128个3×3卷积,第二层是128个1×1卷积),得到预测结果。最终输出的特征映射送到模型的最后一层辅助预测,合起来模型最后的softmax层输入特征多了5×128=6405×128=640个通道。这个地方对每个特征图应该是需要上采样的。我最下面放的caffe的deeplabv1的网络结构没有使用多尺度预测,只使用了CRF。结果证明,多尺度预测的效果不如dense CRF,但也有一定提高。最终模型是结合了Dense CRF与Multi-scale Prediction。加了多尺度预测的网络结构如下:
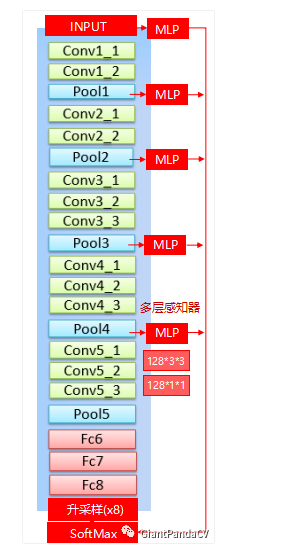
训练细节
DCNN模型采用预训练的VGG16,DCNN损失函数采用交叉熵损失函数。训练器采用SGD,batchsize设置为20。学习率初始为0.001,最后的分类层是0.01。每2000次迭代乘0.1。权重衰减为0.9的动量, 0.0005的衰减。
DeepLab由DCNN和CRF组成,训练策略是分段训练,即DCNN的输出是CRF的一元势函数,在训练CRF时是固定的。在对DCNN做了fine-tune后,再对CRF做交叉验证。这里使用 ω2=3 和 σγ=3 在小的交叉验证集上寻找最佳的 ω1,σα,σβ。
结论
论文模型基于 VGG16,在 Titan GPU 上运行速度达到了 8FPS,全连接 CRF 平均推断需要 0.5s ,在 PASCAL VOC-2012 达到 71.6% IOU accuracy。
Caffe实现
https://github.com/yilei0620/RGBD-Slam-Semantic-Seg-DeepLab/blob/master/slam_deepLab/model/test.prototxt
代码:https://github.com/automan000/DeepLab_v1_TensorFlow1.0/blob/master/nets/large_fov/model.py
import tensorflow as tf
from six.moves import cPickle
# Loading net skeleton with parameters name and shapes.
with open("./util/net_skeleton.ckpt", "rb") as f:
net_skeleton = cPickle.load(f)
# The DeepLab-LargeFOV model can be represented as follows:
## input -> [conv-relu](dilation=1, channels=64) x 2 -> [max_pool](stride=2)
## -> [conv-relu](dilation=1, channels=128) x 2 -> [max_pool](stride=2)
## -> [conv-relu](dilation=1, channels=256) x 3 -> [max_pool](stride=2)
## -> [conv-relu](dilation=1, channels=512) x 3 -> [max_pool](stride=1)
## -> [conv-relu](dilation=2, channels=512) x 3 -> [max_pool](stride=1) -> [avg_pool](stride=1)
## -> [conv-relu](dilation=12, channels=1024) -> [dropout]
## -> [conv-relu](dilation=1, channels=1024) -> [dropout]
## -> [conv-relu](dilation=1, channels=21) -> [pixel-wise softmax loss].
num_layers = [2, 2, 3, 3, 3, 1, 1, 1]
dilations = [[1, 1],
[1, 1],
[1, 1, 1],
[1, 1, 1],
[2, 2, 2],
[12],
[1],
[1]]
n_classes = 21
# All convolutional and pooling operations are applied using kernels of size 3x3;
# padding is added so that the output of the same size as the input.
ks = 3
def create_variable(name, shape):
"""Create a convolution filter variable of the given name and shape,
and initialise it using Xavier initialisation
(http://jmlr.org/proceedings/papers/v9/glorot10a/glorot10a.pdf).
"""
initialiser = tf.contrib.layers.xavier_initializer_conv2d(dtype=tf.float32)
variable = tf.Variable(initialiser(shape=shape), name=name)
return variable
def create_bias_variable(name, shape):
"""Create a bias variable of the given name and shape,
and initialise it to zero.
"""
initialiser = tf.constant_initializer(value=0.0, dtype=tf.float32)
variable = tf.Variable(initialiser(shape=shape), name=name)
return variable
class DeepLabLFOVModel(object):
"""DeepLab-LargeFOV model with atrous convolution and bilinear upsampling.
This class implements a multi-layer convolutional neural network for semantic image segmentation task.
This is the same as the model described in this paper: https://arxiv.org/abs/1412.7062 - please look
there for details.
"""
def __init__(self, weights_path=None):
"""Create the model.
Args:
weights_path: the path to the cpkt file with dictionary of weights from .caffemodel.
"""
self.variables = self._create_variables(weights_path)
def _create_variables(self, weights_path):
"""Create all variables used by the network.
This allows to share them between multiple calls
to the loss function.
Args:
weights_path: the path to the ckpt file with dictionary of weights from .caffemodel.
If none, initialise all variables randomly.
Returns:
A dictionary with all variables.
"""
var = list()
index = 0
if weights_path is not None:
with open(weights_path, "rb") as f:
weights = cPickle.load(f) # Load pre-trained weights.
for name, shape in net_skeleton:
var.append(tf.Variable(weights[name],
name=name))
del weights
else:
# Initialise all weights randomly with the Xavier scheme,
# and
# all biases to 0's.
for name, shape in net_skeleton:
if "/w" in name: # Weight filter.
w = create_variable(name, list(shape))
var.append(w)
else:
b = create_bias_variable(name, list(shape))
var.append(b)
return var
def _create_network(self, input_batch, keep_prob):
"""Construct DeepLab-LargeFOV network.
Args:
input_batch: batch of pre-processed images.
keep_prob: probability of keeping neurons intact.
Returns:
A downsampled segmentation mask.
"""
current = input_batch
v_idx = 0 # Index variable.
# Last block is the classification layer.
for b_idx in xrange(len(dilations) - 1):
for l_idx, dilation in enumerate(dilations[b_idx]):
w = self.variables[v_idx * 2]
b = self.variables[v_idx * 2 + 1]
if dilation == 1:
conv = tf.nn.conv2d(current, w, strides=[1, 1, 1, 1], padding='SAME')
else:
conv = tf.nn.atrous_conv2d(current, w, dilation, padding='SAME')
current = tf.nn.relu(tf.nn.bias_add(conv, b))
v_idx += 1
# Optional pooling and dropout after each block.
if b_idx < 3:
current = tf.nn.max_pool(current,
ksize=[1, ks, ks, 1],
strides=[1, 2, 2, 1],
padding='SAME')
elif b_idx == 3:
current = tf.nn.max_pool(current,
ksize=[1, ks, ks, 1],
strides=[1, 1, 1, 1],
padding='SAME')
elif b_idx == 4:
current = tf.nn.max_pool(current,
ksize=[1, ks, ks, 1],
strides=[1, 1, 1, 1],
padding='SAME')
current = tf.nn.avg_pool(current,
ksize=[1, ks, ks, 1],
strides=[1, 1, 1, 1],
padding='SAME')
elif b_idx <= 6:
current = tf.nn.dropout(current, keep_prob=keep_prob)
# Classification layer; no ReLU.
w = self.variables[v_idx * 2]
b = self.variables[v_idx * 2 + 1]
conv = tf.nn.conv2d(current, w, strides=[1, 1, 1, 1], padding='SAME')
current = tf.nn.bias_add(conv, b)
return current
def prepare_label(self, input_batch, new_size):
"""Resize masks and perform one-hot encoding.
Args:
input_batch: input tensor of shape [batch_size H W 1].
new_size: a tensor with new height and width.
Returns:
Outputs a tensor of shape [batch_size h w 21]
with last dimension comprised of 0's and 1's only.
"""
with tf.name_scope('label_encode'):
input_batch = tf.image.resize_nearest_neighbor(input_batch, new_size) # As labels are integer numbers, need to use NN interp.
input_batch = tf.squeeze(input_batch, axis=[3]) # Reducing the channel dimension.
input_batch = tf.one_hot(input_batch, depth=21)
return input_batch
def preds(self, input_batch):
"""Create the network and run inference on the input batch.
Args:
input_batch: batch of pre-processed images.
Returns:
Argmax over the predictions of the network of the same shape as the input.
"""
raw_output = self._create_network(tf.cast(input_batch, tf.float32), keep_prob=tf.constant(1.0))
raw_output = tf.image.resize_bilinear(raw_output, tf.shape(input_batch)[1:3,])
raw_output = tf.argmax(raw_output, axis=3)
raw_output = tf.expand_dims(raw_output, axis=3) # Create 4D-tensor.
return tf.cast(raw_output, tf.uint8)
def loss(self, img_batch, label_batch):
"""Create the network, run inference on the input batch and compute loss.
Args:
input_batch: batch of pre-processed images.
Returns:
Pixel-wise softmax loss.
"""
raw_output = self._create_network(tf.cast(img_batch, tf.float32), keep_prob=tf.constant(0.5))
prediction = tf.reshape(raw_output, [-1, n_classes])
# Need to resize labels and convert using one-hot encoding.
label_batch = self.prepare_label(label_batch, tf.stack(raw_output.get_shape()[1:3]))
gt = tf.reshape(label_batch, [-1, n_classes])
# Pixel-wise softmax loss.
loss = tf.nn.softmax_cross_entropy_with_logits(logits=prediction, labels=gt)
reduced_loss = tf.reduce_mean(loss)
return reduced_loss














 1327
1327











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









