






本章内容
R中基本的实验设计建模
拟合并解释方差分析模型
检验模型假设
当包含因子是解释变量时,我们关注的重点会从预测转向组别差异的分析(方差分析)。
9.1 术语速成
- 均衡设计 balanced design:各种治疗方案下观测数相等
- 非均衡设计unbalanced design:观测数不同
- 单因素方差分析one-way ANOVA:仅一个类别变量
- 单因素组内方差分析:每位患者在所有水平下都进行了测量,又因为每位被试都不止一次被测量,也称作重复测量分析
- 主效应 & 交互效应:疗法(therapy)和时间(time)都作为因子时,我们既可分析疗法的影响(时间跨度上的平 均)和时间的影响(疗法类型跨度上的平均),又可分析疗法和时间的交互影响。前两个称作主 效应,交互部分称作交互效应
- 因素方差分析设计:当设计包含两个甚至更多的因子时(比如双因素方差分析,三因素方差分析等
- 抑郁症会影响病症治疗,也会和焦虑症同时出现,即使受试者被随机分配到不同的治疗方案中,研究开始时两组不同疗法中的患者抑郁水平就可能不同
- 因此,治疗后的差异都有可能是最初的抑郁水平不同导致的,而不是由于实验的操作问题。
- 即,抑郁症也可以解释因变量的组间差异,因此它常称为混杂变量confounding factor/干扰变数 nuisance variable
- 假设招募患者时使用抑郁症的自我评测报告,记录了他们的抑郁水平,那么可以在评测疗法类型的影响前,对任何抑郁水平的组间差异进行统计性调整,这就是协方差分析
- 当因变量不止一个时,被称作多元方差分析MANOVA,若协变量也存在,就叫多元协方差分析MANCOVA
-
9.2 ANOVA拟合
虽然ANOVA和回归方法都是独立发展而来,但是从函数形式上看,它们都是广义线性模型 的特例。用第7章讨论回归时用到的lm()函数也能分析ANOVA模型。不过,本章我们基本都使 用aov()函数。两个函数的结果是等同的,但ANOVA的方法学习者更熟悉aov()函数展示结果 的格式。
9.2.1 aov函数
aov(formula, data=dataframe)R表达式中的特殊符号

常用研究设计的表达式
 9.2.2 表达式中各项的顺序
9.2.2 表达式中各项的顺序
R默认类型I(序贯型)方法计算ANOVA效应(参考补充内容“顺序很重要!”)。第一个模型 可以这样写:y ~ A + B + A:B。R中的ANOVA表的结果将评价:
A对y的影响;
控制A时,B对y的影响;
控制A和B的主效应时,A与B的交互效应。

样本大小越不平衡,效应项的顺序对结果的影响越大。
- 一般来说,越基础性的效应越需要放 在表达式前面。具体来讲,首先是协变量,然后是主效应,接着是双因素的交互项,再接着是三 因素的交互项,以此类推。
- 对于主效应,越基础性的变量越应放在表达式前面,因此性别要放在 处理方式之前。
- 有一个基本的准则:若研究设计不是正交的(也就是说,因子和/或协变量相关), 一定要谨慎设置效应的顺序
具体使用注意:
- car包的Anova()【注意,和标准anova()不一样】:提供了类型Ⅱ或者类型Ⅲ方法的选项,而aov()使用的是类型Ⅰ
- 若想使结果与其他软件(如SAS和SPSS)提供的结果保持一致,可以使用Anova()函数,细节可参考help(Anova, package="car")
9.3 单因素方差分析:关注分类因子定义的两个或多个组别中的因变量均值
- 以 multcomp包中的cholesterol数据集为例(取自Westfall、Tobia、Rom、Hochberg,1999),50 个患者均接受降低胆固醇药物治疗(trt)五种疗法中的一种疗法。
- 其中三种治疗条件使用药物 相同,分别是20mg一天一次(1time)、10mg一天两次(2times)和5mg一天四次(4times)。
- 剩下 的两种方式(drugD和drugE)代表候选药物。
- 哪种药物疗法降低胆固醇(响应变量)最多呢?
library(multcomp)
attach(cholesterol)
# 看各组样本大小
table(trt)
# 看各组均值
aggregate(response, by=list(trt), FUN=mean)
# 各组标准差
aggregate(response, by=list(trt), FUN=sd)
# 检验组间差异
fit <- aov(response ~ trt)
summary(fit)
# 绘制各组均值和置信区间的图形
library(gplots)
plotmeans(response ~ trt, xlab="Treatment", ylab="Response", main="Mean Plot\nwith 95% CI")
detach(cholesterol)
gplots包中的plotmeans()可以用来绘制带有置信区间的组均值图形➎。如图9-1所示,图 形展示了带有95%的置信区间的各疗法均值,可以清楚看到它们之间的差异。
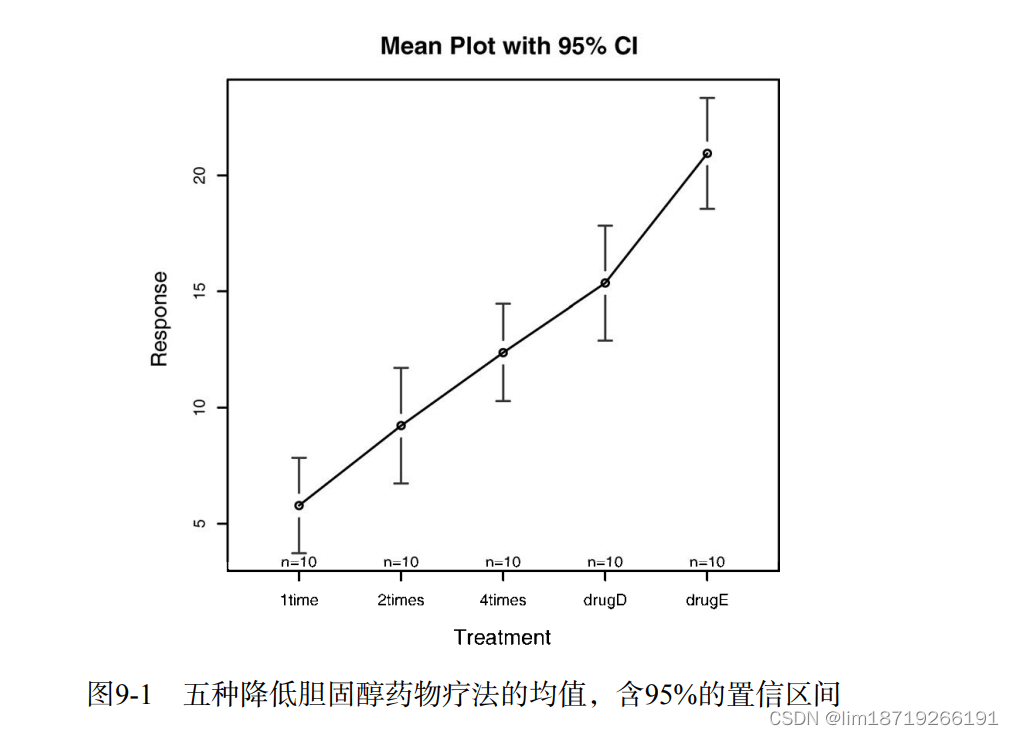
9.3.1 多重比较:虽然ANOVA对各疗法的F检验表明五种药物疗法效果不同,但是并没有告诉你哪种疗法与其 他疗法不同。多重比较可以解决这个问题:TukeyHSD()
TukeyHSD(fit)
par(las=2) # 旋转轴标签
par(mar=c(5,8,4,2)) # 增大左边面积
plot(TukeyHSD(fit)) 
比较两个p,2-1的差异小,4-1的差异大

画的是置信区间,包含0的话说明差异不显著
9.3.2 评估检验的假设条件
- 我们对于结果的信心依赖于做统计检验时数据满足假设条件的程度。
- 单 因素方差分析中,我们假设因变量服从正态分布,各组方差相等。
通过Q-Q图来检验正态性
library(car)
qqPlot(lm(response ~ trt, data=cholesterol), simulate=TRUE, main="Q-Q Plot", labels=FALSE)
qqplot要求用lm()拟合,数据落在95%的置信区间内,说明满足正态性假设
方差齐性检验:Bartlett检验
bartlett.test(response ~ trt, data=cholesterol) - Bartlett检验表明五组的方差并没有显著不同(p=0.97)。
- 其他检验如Fligner-Killeen检验 (fligner.test()函数)和Brown-Forsythe检验(HH包中的hov()函数)此处没有做演示,但它 们获得的结果与Bartlett检验相同
方差齐性检验对离群点非常敏感,可以利用car包中的outlierTest()来检测离群点
library(car)
outlierTest(fit) 从输出结果来看,并没有证据说明胆固醇数据中含有离群点(当p>1时将产生NA)。因此根 据Q-Q图、Bartlett检验和离群点检验,该数据似乎可以用ANOVA模型拟合得很好。这些方法反 过来增强了我们对于所得结果的信心
9.4 单因素协方差分析
- 单因素协方差分析(ANCOVA)扩展了单因素方差分析(ANOVA),包含一个或多个定量的 协变量。
- 下面的例子来自于multcomp包中的litter数据集(见Westfall et al.,1999)。
- 怀孕小鼠 被分为四个小组,每个小组接受不同剂量(0、5、50或500)的药物处理。产下幼崽的体重均值 为因变量,怀孕时间为协变量。
data(litter, package="multcomp")
attach(litter)
table(dose)
aggregate(weight, by=list(dose), FUN=mean)
fit <- aov(weight ~ gesttime + dose)
summary(fit) - 利用table()函数,可以看到每种剂量下所产的幼崽数并不相同:0剂量时(未用药)产崽 20个,500剂量时产崽17个。
- 再用aggregate()函数获得各组均值,可以发现未用药组幼崽体重 均值最高(32.3)
- ANCOVA的F检验表明:(a)怀孕时间与幼崽出生体重相关;(b)控制怀孕时间, 药物剂量与出生体重相关。控制怀孕时间,确实发现每种药物剂量下幼崽出生体重均值不同。
由于使用了协变量,你可能想要获取调整的组均值,即去除协变量效应后的组均值。可使用 effects包中的effects()函数来计算调整的均值
library(effects)
effect("dose", fit) # 总之,effects包为复杂的研究设计提供了强大的计算调整均值的方法,并能将结果可
视化,
对于用户定义的对照的多重比较:假定你对未用药条件与其他三种用药条件影响是否不同感兴趣。代码清单9-4可以用来检验 你的假设
library(multcomp)
contrast <- rbind("no drug vs. drug" = c(3, -1, -1, -1))
summary(glht(fit, linfct=mcp(dose=contrast))) 对照c(3, -1, -1, -1)设定第一组和其他三组的均值进行比较。假设检验的t统计量(2.581) 在p<0.05水平下显著,因此,可以得出未用药组比其他用药条件下的出生体重高的结论。其他对 照可用rbind()函数添加
9.4.1 评估检验的假设条件
ANCOVA与ANOVA相同,都需要正态性和同方差性假设,可以用9.3.2节中相同的步骤来检 验这些假设条件。
另外,ANCOVA还假定回归斜率相同。本例中,假定四个处理组通过怀孕时间 来预测出生体重的回归斜率都相同。ANCOVA模型包含怀孕时间×剂量的交互项时,可对回归斜 率的同质性进行检验。交互效应若显著,则意味着时间和幼崽出生体重间的关系依赖于药物剂量 的水平
检验回归斜率的同质性
library(multcomp)
fit2<-aov(weight~gesttime*dose,data=litter)
summary(fit2)- 可以看到交互效应不显著,支持了斜率相等的假设。
- 若假设不成立,可以尝试变换协变量或 因变量,或使用能对每个斜率独立解释的模型,或使用不需要假设回归斜率同质性的非参数 ANCOVA方法。
9.4.2 结果可视化
HH包中的ancova()函数可以绘制因变量、协变量和因子之间的关系图。例如代码:
library(HH)
ancova(weight ~ gesttime + dose, data=litter)9.5 双因素方差分析
在双因素方差分析中,受试者被分配到两因子的交叉类别组中。以基础安装中的 ToothGrowth数据集为例,随机分配60只豚鼠,分别采用两种喂食方法(橙汁或维生素C),各 喂食方法中抗坏血酸含量有三种水平(0.5mg、1mg或2mg),每种处理方式组合都被分配10只豚 鼠。牙齿长度为因变量
双因素ANOVA
attach(ToothGrowth)
table(supp, dose)
# table语句的预处理表明该设计是均衡设计(各设计单元中样本大小都相同)
aggregate(len, by=list(supp, dose), FUN=mean)
aggregate(len, by=list(supp, dose), FUN=sd)
dose <- factor(dose) #dose变量被转换为因子变量
fit <- aov(len ~ supp*dose) # 这样aov()函数就会将它当做一个分组变量,而不是一个数值型协变量
summary(fit) #用summary()函数得到方差分析表,可以看到主效应(supp和dose)和交互效应都非常显著。
detach(ToothGrowth)
可视化处理:用summary()函数得到方差分析表,可以看到主效应(supp和dose)和交互效应都非常显著。
interaction.plot(dose, supp, len, type="b",
col=c("red","blue"), pch=c(16, 18),
main = "Interaction between Dose and Supplement Type")
- 图形展示了各种剂量喂食下豚鼠牙齿长度的均值。
- 喂食方法和剂量对牙齿生长的交互作用。
- 用interaction.plot()函数绘制 了牙齿长度的均值。
还可以用gplots包中的plotmeans()函数来展示交互效应。
library(gplots)
plotmeans(len ~ interaction(supp, dose, sep=" "),
connect=list(c(1,3,5),c(2,4,6)),
col=c("red", "darkgreen"),
main = "Interaction Plot with 95% CIs",
xlab="Treatment and Dose Combination")

喂食方法和剂量对牙齿生长的交互作用。用plotmeans()函数绘制的95%的置 信区间的牙齿长度均值。
图形展示了均值、误差棒(95%的置信区间)和样本大小。
最后,你还能用HH包中的interaction2wt()函数来可视化结果,图形对任意顺序的因子 设计的主效应和交互效应都会进行展示。
library(HH)
interaction2wt(len~supp*dose) 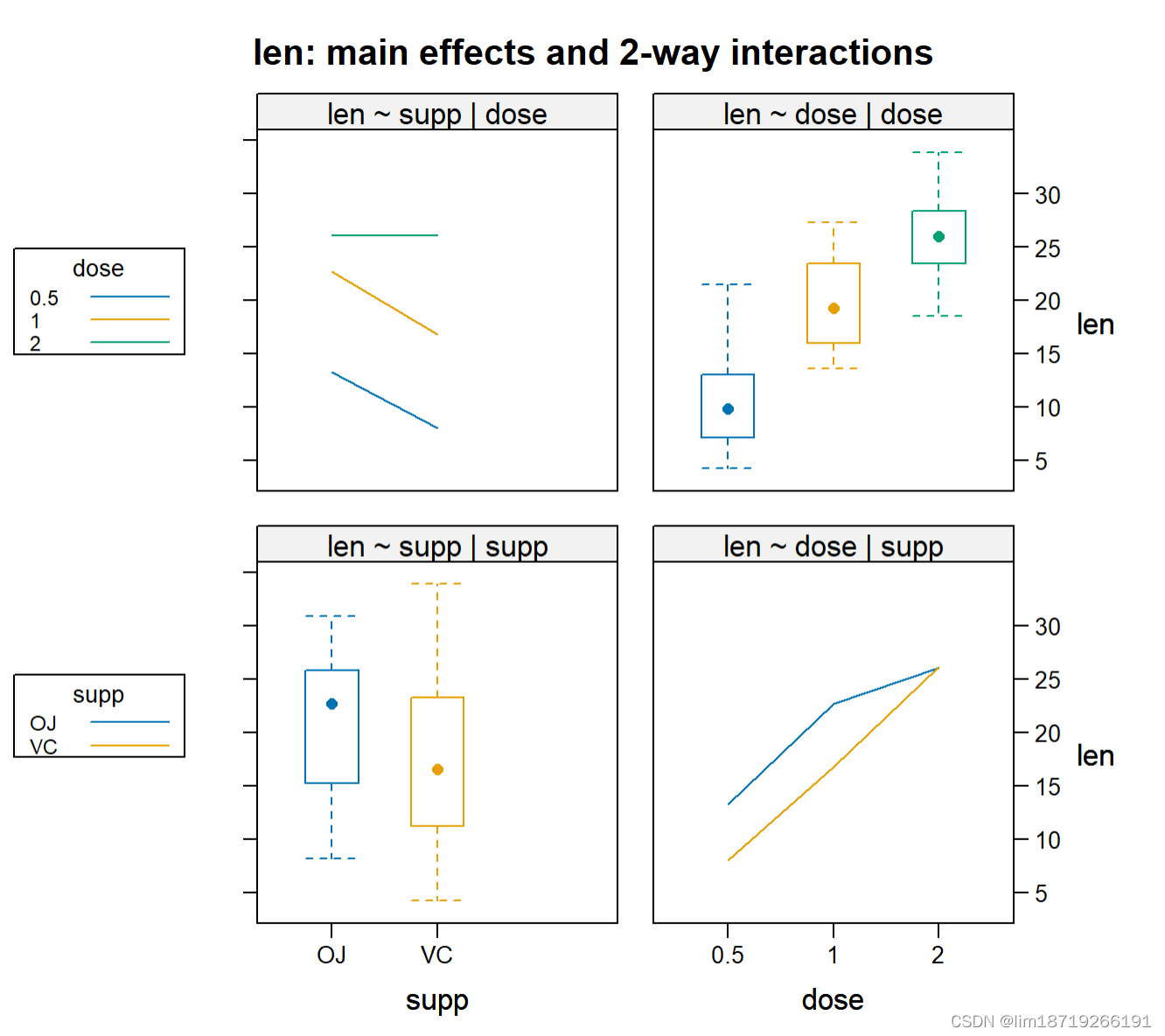
ToothGrowth数据集的主效应和交互效应。图形由interaction2wt()函数 创建
- 以上三幅图形都表明随着橙汁和维生素C中的抗坏血酸剂量的增加,牙齿长度变长。
- 对于 0.5mg和1mg剂量,橙汁比维生素C更能促进牙齿生长;
- 对于2mg剂量的抗坏血酸,两种喂食方法 下牙齿长度增长相同。
三种绘图方法中,我更推荐HH包中的interaction2wt()函数,因为它能展示任意复杂度 设计(双因素方差分析、三因素方差分析等)的主效应(箱线图)和交互效应。
- 此处没有涵盖模型假设检验和均值比较的内容,因为它们只是之前方法的一个自然扩展而 已。此外,该设计是均衡的,故而不用担心效应顺序的影响。
9.6 重复测量方差分析:即受试者被测量不止一次。
本节重点关注含一个组内和一个组间因 子的重复测量方差分析(这是一个常见的设计)。
示例来源于生理生态学领域,研究方向是生命 系统的生理和生化过程如何响应环境因素的变异(此为应对全球变暖的一个非常重要的研究领 域)。
- 基础安装包中的CO2数据集包含了北方和南方牧草类植物Echinochloa crus-galli (Potvin、 Lechowicz、Tardif,1990)的寒冷容忍度研究结果,在某浓度二氧化碳的环境中,对寒带植物与 非寒带植物的光合作用率进行了比较。
- 研究所用植物一半来自于加拿大的魁北克省(Quebec), 另一半来自美国的密西西比州(Mississippi)。
- 首先,我们关注寒带植物。
- 因变量是二氧化碳吸收量(uptake),单位为ml/L,自变量是植 物类型Type(魁北克VS.密西西比)和七种水平(95~1000 umol/m^2 sec)的二氧化碳浓度(conc)。
- 另外,Type是组间因子,conc是组内因子。Type已经被存储为一个因子变量,但你还需要先将 conc转换为因子变量。
- 首先,我们关注寒带植物。
CO2$conc <- factor(CO2$conc)
w1b1 <- subset(CO2, Treatment=='chilled')
fit <- aov(uptake ~ conc*Type + Error(Plant/(conc)), w1b1)
summary(fit)
par(las=2)
par(mar=c(10,4,4,2))
with(w1b1, interaction.plot(conc,Type,uptake,
type="b", col=c("red","blue"), pch=c(16,18),
main="Interaction Plot for Plant Type and Concentration"))
boxplot(uptake ~ Type*conc, data=w1b1, col=(c("gold", "green")),
main="Chilled Quebec and Mississippi Plants",
ylab="Carbon dioxide uptake rate (umol/m^2 sec)") 方差分析表表明在0.01的水平下,主效应类型和浓度以及交叉效应类型×浓度都非常显著, 图9-9中通过interaction.plot()函数展示了交互效应
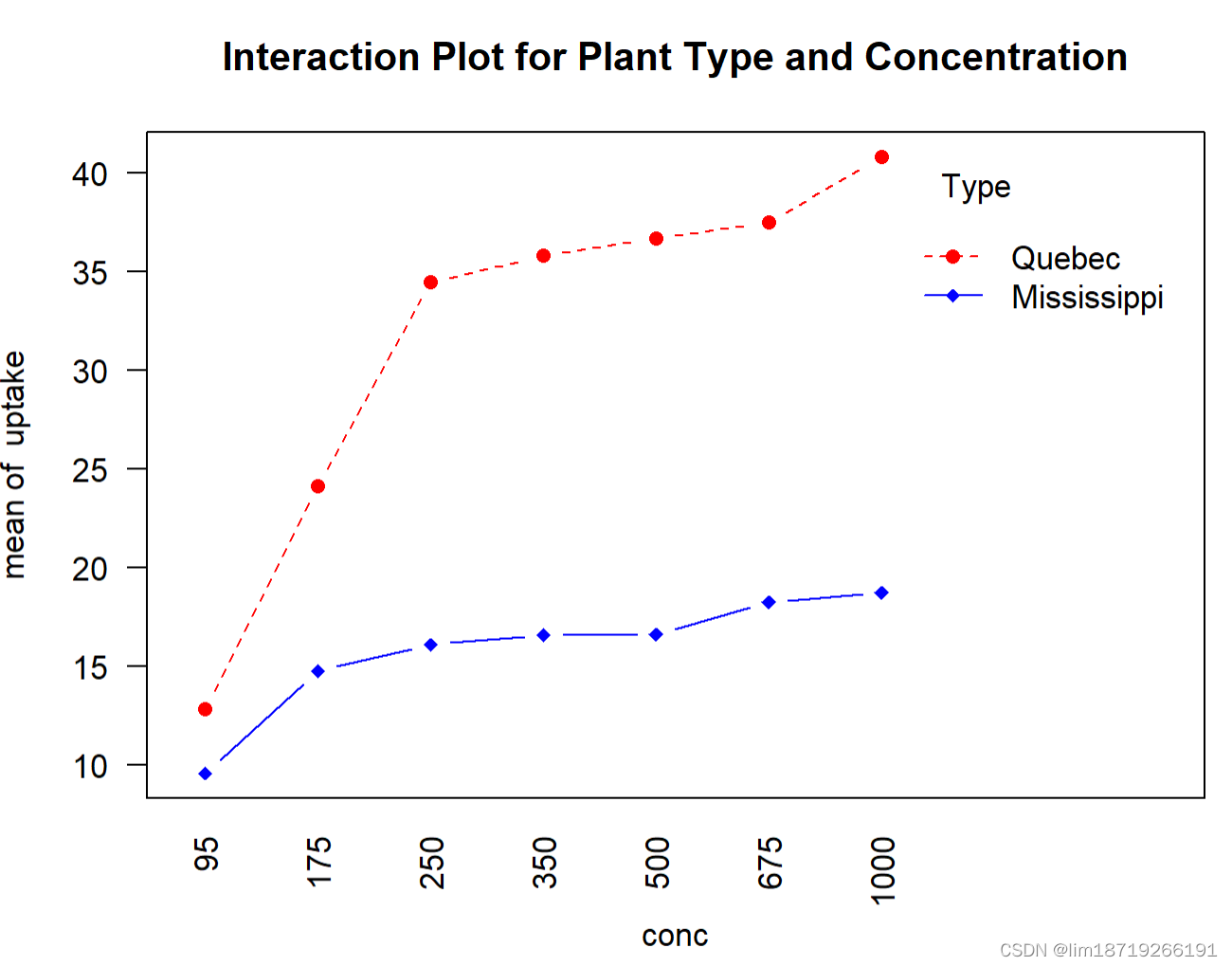
若想展示交互效应其他不同的侧面,可以使用boxplot()函数对相同的数据画图,结果见图

从以上任意一幅图都可以看出,魁北克省的植物比密西西比州的植物二氧化碳吸收率高,而 且随着CO2浓度的升高,差异越来越明显。
- 通常处理的数据集是宽格式(wide format),即列是变量,行是观测值,而且一行一个受 试对象。
- 9.4节中的litter数据框就是一个很好的例子。不过在处理重复测量设计时,需 要有长格式(long format)数据才能拟合模型。
- 在长格式中,因变量的每次测量都要放到 它独有的行中,CO2数据集即该种形式。幸运的是,5.6.3节的reshape包可方便地将数据 转换为相应的格式。
混合模型设计的各种方法 在分析本节关于CO2的例子时,我们使用了传统的重复测量方差分析。
该方法假设任意组 内因子的协方差矩阵为球形,并且任意组内因子两水平间的方差之差都相等。
但在现实中这种 假设不可能满足,于是衍生了一系列备选方法:
- 使用lme4包中的lmer()函数拟合线性混合模型(Bates,2005);
- 使用car包中的Anova()函数调整传统检验统计量以弥补球形假设的不满足(例如 Geisser-Greenhouse校正);
- 使用nlme包中的gls()函数拟合给定方差-协方差结构的广义最小二乘模型(UCLA
- 用多元方差分析对重复测量数据进行建模(Hand,1987)。
9.7 多元方差分析:当因变量(结果变量)不止一个时
单因素多元方差分析
library(MASS)
attach(UScereal)
shelf <- factor(shelf) # 将shelf变量转换为因子变量,从而使它在后续分析中能作为分组变量。
y <- cbind(calories, fat, sugars) # 将三个因变量(卡路里、脂肪和糖)合并成一个矩阵
aggregate(y, by=list(shelf), FUN=mean) # aggregate()函数可获取货架的各个均值,
cov(y) # cov()则输出各谷物间的方差和协方差。
fit <- manova(y ~ shelf) #manova()函数能对组间差异进行多元检验。上面F值显著,说明三个组的营养成分测量值不同。注意shelf变量已经转成了因子变量,因此它可以代表一个分组变量。
summary(fit)
summary.aov(fit) #由于多元检验是显著的,可以使用summary.aov()函数对每一个变量做单因素方差分析
从上述结果可以看到,三组中每种营养成分的测量值都是不同的。另外,还可以用均值比较步骤
(比如TukeyHSD)来判断对于每个因变量,哪种货架与其他货架都是不同的
9.7.1 评估假设检验
单因素多元方差分析有两个前提假设,一个是多元正态性,一个是方差-协方差矩阵同质性。 第一个假设即指因变量组合成的向量服从一个多元正态分布。可以用Q-Q图来检验该假设条件。

检验多元正态性
center<-colMeans(y)
n <- nrow(y)
p <- ncol(y)
cov <- cov(y)
d <- mahalanobis(y,center,cov)
coord <- qqplot(qchisq(ppoints(n),df=p),
d, main="Q-Q Plot Assessing Multivariate Normality",
ylab="Mahalanobis D2")
abline(a=0,b=1)
identify(coord$x, coord$y, labels=row.names(UScereal))

若数据服从多元正态分布,那么点将落在直线上。
你能通过identify()函数(参见16.4节) 交互性地对图中的点进行鉴别。
从图形上看,观测点“Wheaties Honey Gold”和“Wheaties”异 常,数据集似乎违反了多元正态性。可以删除这两个点再重新分析。
最后,还可以使用mvoutlier包中的ap.plot()函数来检验多元离群点。代码如下:
library(mvoutlier)
outliers <- aq.plot(y)
outliers 

9.7.2 稳健多元方差分析
- 如果多元正态性或者方差-协方差均值假设都不满足,或者你担心多元离群点,那么可以考 虑用稳健或非参数版本的 MANOVA 检验。
- 稳健单因素 MANOVA 可通过 rrcov 包中的 Wilks.test()函数实现。
- vegan包中的adonis()函数则提供了非参数MANOVA的等同形式。
稳健单因素MANOVA
library(rrcov)
wilks.test(y,shelf,method="mcd") 从结果来看,稳健检验对离群点和违反MANOVA假设的情况不敏感,而且再一次验证了存 储在货架顶部、中部和底部的谷物营养成分含量不同















 771
771











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









