






ppt:北师大王宁老师课程ppt
参考资料:R机器学习:分类算法之判别分析LDA,QDA的原理与实现 - 知乎 (zhihu.com)
全称:Linear Discriminant Analysis and Quadratic Discriminant Analysis 线性判别分析和二次判别分析
判别分析有两个作用,一个是降维dimensionality reduction,另一个是分类classifier。就是说这个方法可以将多维数据投射到低维平面,并且还能使得我们的数据类别非常好区分。
方差相等:LDA
不相等:QDA
Optimization for the Boundary of Classes

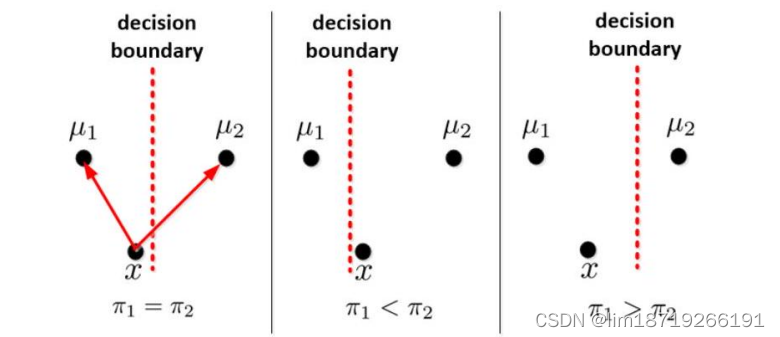
什么是boundary?
x*分到两类里的概率相等, x*就在边界上,具体而言,分类的含义就是:r
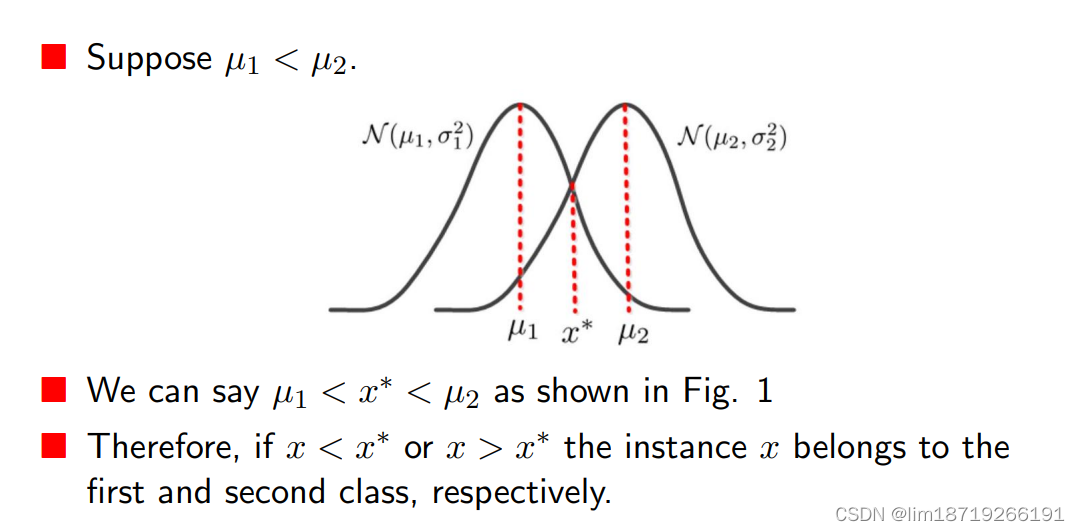
(其实就像是一类错误和二类错误)
分类问题的target:使得一类错误与二类错误之和最小,求微分之后,就会变成:
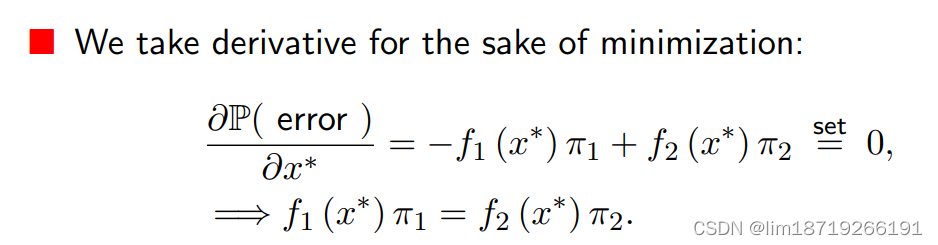
除了1. 先列式子再求偏导的方式得到等式外,还可以通过2. 将后验概率等同于类边界方程来计算
(算出来的结果是一样的)

LDA for Binary Classification

判别式:通过上面的黄色式子>0 or <0来判断分类
第一项是x的项,第二项与x无关,常数项,所以就是分类边界线性。

QDA for Binary Classification
- relax the assumption:∑不相等,导致出现二次项

LDA and QDA for Multi-class Classification
- multiple classes

Estimation for LDA and QDA(与贝叶斯一样,还是MLE)
LDA:assume covariance matrices are equal
1. 所以目标表达式会优化为:
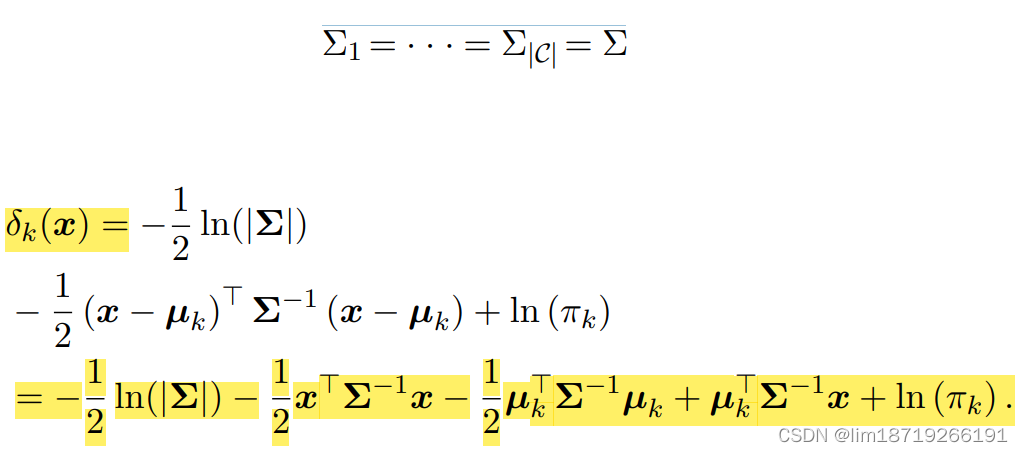
此时的Σ:
使用估计协方差矩阵的加权平均值作为LDA中的公共协方差矩阵:其中权重是类的基数。
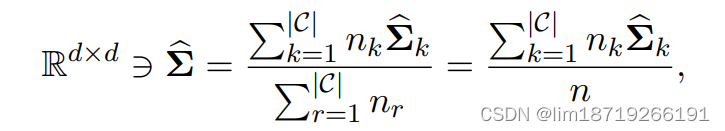
2. 第 k 类的先验是根据第 k 类的样本量估计的:
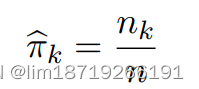 :其中 nk 和 n 分别是第 k 个类和总数中的训练实例数
:其中 nk 和 n 分别是第 k 个类和总数中的训练实例数
3. 均值:对于高斯分布的均值,可以使用最大似然估计 (MLE) 或矩量法 (MOM) 来估计第 k 类的均值:
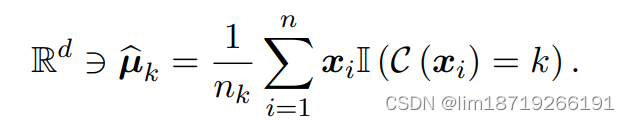
QDA:
1. 第 k 个类的协方差矩阵使用 MLE 进行估计:
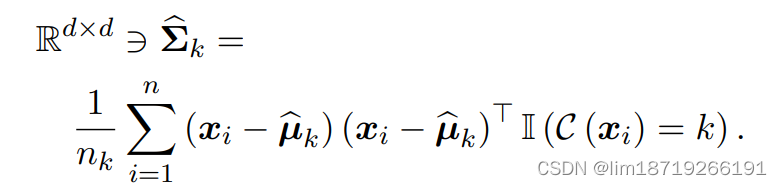
或者用无偏估计
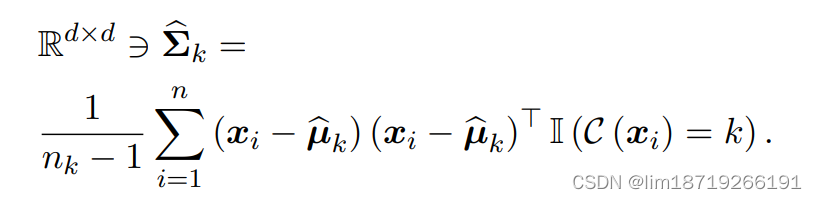
LDA与QDA有个问题:看决策边界,∑-1需要估计,并且估计不好对结果效果影响很大(所以仅限于低维有用):
解决:高维算不出来,加上一项使其可逆,但是会影响效果。
如何把LDA与QDA拓展到高维?
LDA and QDA are Metric Learning!
- 假设:LDA+协方差矩阵是单位阵
- 可计算距离如下:

Thus, the QDA or LDA reduce to simple Euclidean distance from the means of classes if the covariance matrices are all identity matrix and the priors are equal.
因此,如果协方差矩阵都是单位矩阵并且先验相等,则 QDA 或 LDA 会减少到与类均值的简单欧几里得距离。
协方差矩阵非单位阵——马氏距离
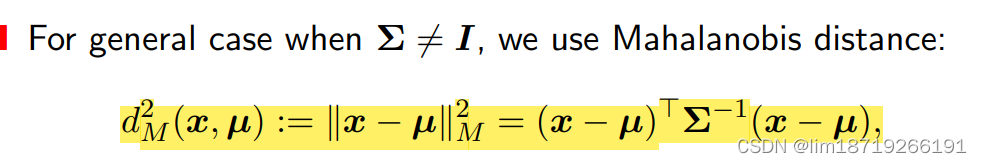
Relationship with Naive Bayes classifier
- 一维时:Gaussian naive Bayes and QDA are equivalent
- 多维时:QDA is more powerful
- Gaussian naive Bayes is equivalent to QDA where the covariance matrices are di agonal(对角阵时两者相同,意味着贝叶斯其实是QDA的简化), i.e., the off-diagonal of the covariance matrices are ignored.
experiments
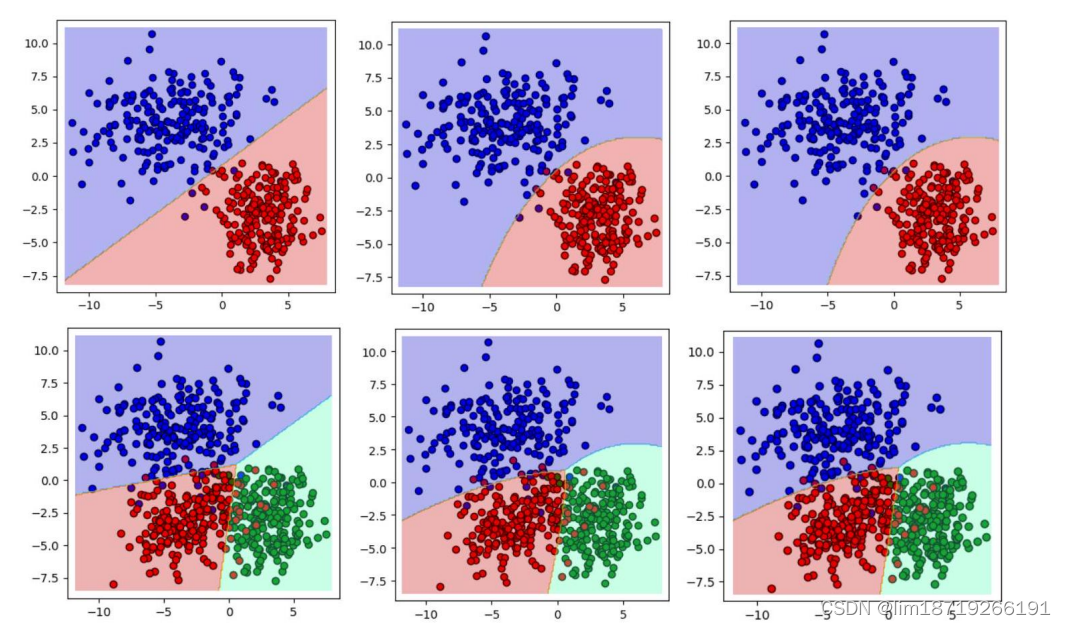

High-dimensional consideration

- 传统方法:分开估计两个参数,μ和∑
- 高维方法(比如lasso):先assume 两者是稀疏化的sparse,然后再估计,从而达到①降低估计误差;②使得∑-1可预测的情况
- but:A sparse estimation for µk is easy to construct; sparse estimation for Σ−1 is more difficult and computationally expensive.
- What if we direct assume that βk = Σ−1µk is sparse?(直接一块估计分类系数是稀疏化的,设为β,即只有少数x(x的一些分量)起到作用
参考文献:
Mai Q, Yang Y, Zou H. Multiclass sparse discriminant analysis[J]. Statistica Sinica, 2019, 29(1): 97-111.
case1:还是没有办法解决高维问题:


case2:换了个表达方法,可行,增加了惩罚项(一些矩阵运算)

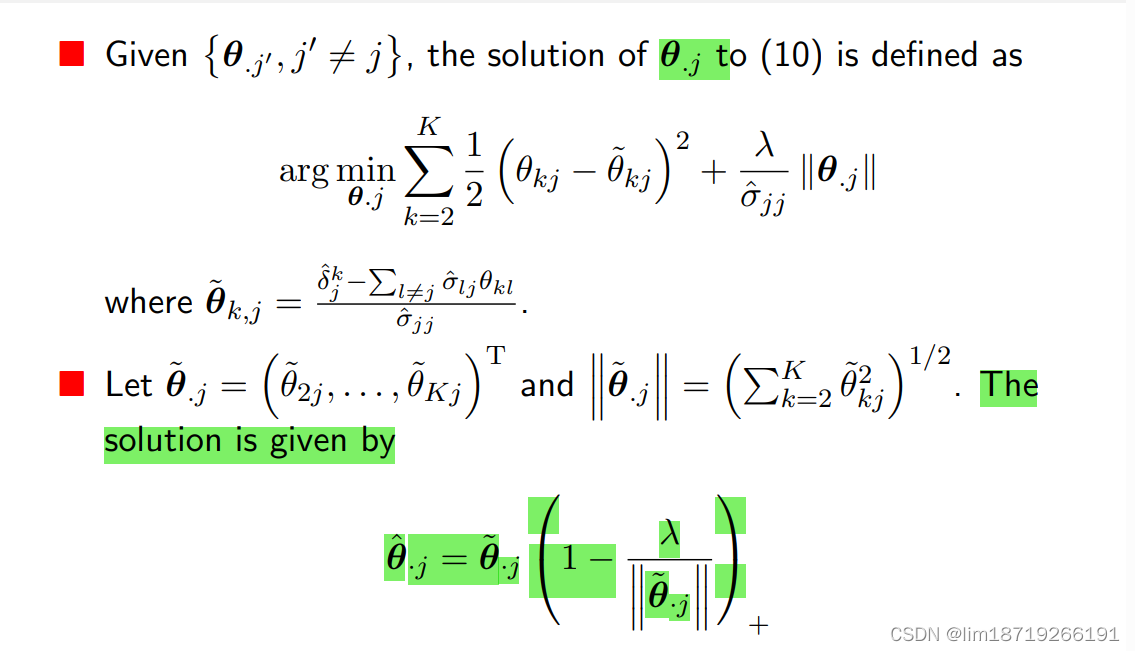
计算机运算:

第二节上课一点点:
存在最低错误率Bayes error

Q:high-dimensional QDA?
■ It is more technically involved since we need to give a sparse estimation for ![]() 由于我们需要对 Σ −1 k − Σ −1 1 给出一个稀疏估计,因此在技术上涉及更多。
由于我们需要对 Σ −1 k − Σ −1 1 给出一个稀疏估计,因此在技术上涉及更多。
参考论文:
■ Cai T T, Zhang L. A convex optimization approach to high-dimensional sparse quadratic discriminant analysis[J]. The Annals of Statistics, 2021, 49(3): 1537-1568.
■ Jiang B, Wang X, Leng C. A direct approach for sparse quadratic discriminant analysis[J]. The Journal of Machine Learning Research, 2018, 19(1): 1098-1134















 3159
3159











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









