







题目:重复数据只保留一条id最大的
数据准备:
CREATE TABLE t19 (
id int,
name string
) ;
INSERT INTO t19 VALUES ('1', 'A')
,('2', 'A')
,('3', 'A')
,('4', 'B')
,('5', 'B')
,('6', 'C')
,('7', 'B')
,('8', 'B')
,('9', 'B')
,('10', 'E')
,('11', 'E')
,('12', 'E');1.使用窗口函数
窗口函数可以用来在同一组中为每行分配一个行号,然后对筛选出行号为 1 的行(即 id 最大的行)。
假设你的表名为 t19,并且你要按 name 分组,那么你可以这样写查询:
使用row_number()开窗函数为同一name组的每行分配行号,按照id降序排列,得到的排序顺序是从1开始递增的,这是‘row_number()’自带的固有属性。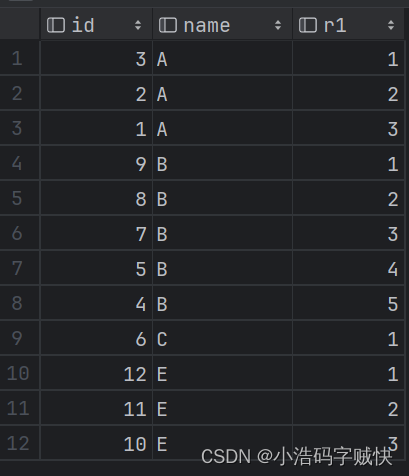
此时因为id是降序排列,id大的name排在前列,则r1=1对应的name就是我们所需要的id最大的name,通过子查询嵌套,按照where条件查询r1=1就可以查询出最大的id。
select id,name
from (select *,row_number() over (partition by name order by id desc ) r1
from t19) t1 where r1=1;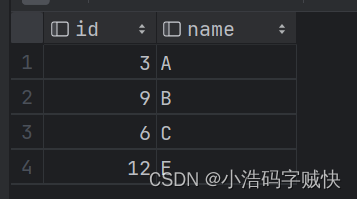















 7363
7363

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









