







AI手机-手机SIM卡通话内容
ASR识别和文字提取-(AI手机通话功能探索)
背景
在前面的篇章中,我们探讨了如何从手机SIM打电话中获取通话的语音数据和响应事件,并且为了扩大使用面、以及提升易用性,我们公开了基于FreeSwitch和Http-Rest的api接口请求和呼叫方式,使电话能被局域网内的任意设备进行呼叫和来电的接听。
本篇章中,我们将对通话中获取到的语音数据做进一步的加工和处理,使语音业务能进行更多增值业务的扩展,并为通话业务实时的语音质检等安全性功能提供可靠的支撑。
近年来移动互联网提出的AI手机的概念,主要在3个方向上给终端设备赋能:
- 图像采集:对摄像头RAW数据的深加工;包括星空、夜景、微距、长焦等处理,使光影更加立体、景深层次更加自然、皮肤细节和肤质更加真实。
- 图像的处理:对拍摄的图片进行智能处理、对录制的视频进行智能加工;包括AI画师、AI消除、AI剪辑、图片视频摘要、以图搜图、一键生成高质量的视频作品等。
- 采集声音的加工和反馈:识别语音和环境声音,并进行实时的响应;包括通话摘要、AI应答、实时翻译、语音搜索、智能客服等。
AI手机通过建立在云端或手机终端的大模型,对用户行为和特征数据进行提取和分析,并反馈到用户的操作结果上,极大的扩充了手机用户的应用能力和体验效果。事实上在“AI手机”这个概念出来之前的好多年,互联网世界一直都在做这些事情,包括天猫精灵/小爱助手/苹果Siri等普及应用都是建立在大模型上的结果。只是AI手机有可能会将大模型迁移到手机设备、提高响应效率而已。
对于语音领域而言,由于早期手机在结构和硬件上不能很好的支持电话通话的语音场景,仅限于普通智能应用场景下进行语音识别和反馈;在AI手机时代,AI手机将全面支持SIM电话通话场景下的实时翻译、通话摘要等业务,这与我们本篇章的内容有一定的重合度。
站在互联网时代前人的肩膀之上,在通话领域,一个AI手机或者说一个具备AI功能的手机,应该具备哪些能力呢?
以飞书视频会议的会议概要,用图示来举例说明在流媒体领域,AI大概是什么效果:
(简单总结下,大致为:会议纪要、章节纪要、文字记录、会议信息、发言人信息、发言人分段语音)


上面的应用,以时间分段的方式列举参会的每一个人,在会议期间的哪几分钟到几分钟说话,说了什么内容;
并按不同角色和发言将会议划分为N个阶段,提取出章节纪要,并为每个章节中留存有的待办事项和问题点进行归类和汇总;
最后基于这个场景和各章节内容,提炼出会议纪要的总结。
回放视频的人通过录音时刻、文字记录、章节纪要等位置可以自由切换跳转到对应位置的视频和语音进行点播观看。这种共享方式可以降低记录人员和回放总结的工作量,对于未参会的人员也可主题明确的进行收看和查阅。
语音识别行业现状
对于智能手机的语音处理,按照时间先后顺序的不同,我们可以简单的把语音类应用,划分为三个维度来观察和分类:
- 从应用的时间维度来看,可以简单分类为普通语音的处理和SIM卡电话语音的处理;
- 从处理节点的角度来看,可以分类为云端处理和手机本地离线处理;
- 从通话内容的处理的实时性来看,可以分为实时交互处理和通话后整理性处理。
在互联网和移动互联网世界,由于运算能力的扩散趋势从云端向终端演进,即“云计算”向“边缘计算”靠拢,越来越多依赖算力的应用app和应用场景会更贴近终端一侧,大模型和基于大模型的应用也同样趋同于这个演进方向。
但是由于时间线的因素,目前智能设备的算力仍旧不是很充足,当前市面上几乎所有的成熟应用,在语音生成文字(ASR)领域,基本都是采用“将手机收到的语音数据传输到服务器,服务器识别后再将ASR识别的结果实时传输到手机app,再进行展示”的模式。常见的微信短语音转文字、天猫精灵/小爱同学的智能硬件、讯飞输入法/百度输入法的长按说话转文字输入等使用较为广泛的应用和设备基本都采用这种模式。
测试上述应用是否离线ASR最简单的方法就是断网后使用,看看脱离服务器后,上述应用的识别功能是否能够继续工作并且识别的准确率是否一致。
在手机展示方面,得益于TTS技术的成熟,目前绝大部分的文字转语音(TTS)的工作基本都放在终端进行,最经典的应该是“剪映”App,它使用内置的语料库,可以将用户输入的文字转换为几十种不同人物的口音输出;手机导航常用的高德和百度地图,其语音导航的人物角色选择也较为完善。
在大部分语音交互的应用场景中,交互的设计人员可以自由的选择以文字、TTS语音、自录制的语料等方式进行反馈。
在语音通话和对话领域,智能客服、通话质检、AI语音助手算是ASR应用较为广泛的场景,参与的厂商很多、应用的成熟度也很高。应用场景对语音数据的加工包括主流程的内容识别、关键字提取、AI检索和应答;以及辅助流程的敏感词预警、语气/情绪分析、内容信息摘要、人物画像等。
全球自动语音识别(ASR)软件市场主要厂商包括Nuance, Voicepoint, Openstream, Total Voice Technologies, Entrada, Brainasoft, NeoSpeech, Protokol, LilySpeech, Crescendo Systems, Lyrix, Smart Action Company, Go Transcribe等。2022年全球自动语音识别(ASR)软件市场规模约为910亿元(人民币)。
国内自动语音识别(ASR)软件消费市场有百度、阿里巴巴、腾讯、搜狗、小米等IT 及互联网厂商,以及科大讯飞、云知声、思必驰等语音技术厂商。国内环境中阿里巴巴、科大讯飞、百度、腾讯均处于高竞争力区间。

常用ASR算法和模型
ASR做为大模型的具体应用,训练样本数和算法效率是识别的关键。在模型库中一般输出为“Tensorflow训练版本”、“PyTorch训练版本”、“onnx量化导出版本”等的区别。(当然本篇章不是讲解如何做深度学习框架选型的,类似于PaddlePaddle、CNTK、Caffe这种我们就先略过,只需要知道它们或多或少都能有方法转换成上述三种模型即可)
方案选择时,训练样本数量级会直接影响到模型库的大小。在ASR中反馈的表现就是60000分钟的语料,输出的模型是300M/800M/1.3G大小的差异。由于各国家不同语言之间特征差异极大,一般不同语言的模型库会独立出来,识别之前需要选择是属于哪一种语言的语料,然后再加载对应的模型文件,然后才会对语料进行ASR解析和识别。
通过以上信息,我们可以推测出一个现状:模型的不同算法,具体到某种语言的识别效果,最好是采用本土化方案较高的模型,且模型库越大(训练的语料越多)则识别就越准确。
很明显,如果识别越南话、柬埔寨语,最好是采用它本国的ASR识别整体解决方案(如果有的话)。同理,如果要识别四川话、粤语、河南话,最好还是采用它们本土的、能提供充足语料数量的模型来进行ASR识别。
ASR方案列表中常见有AWS、Miscrosoft、Skype、Facebook等,以及开源的cmusphinx、pocketsphinx-android、vosk-android等;国内常用的有腾讯、阿里、百度、小米、搜狗、科大讯飞等、以及开源的百度飞浆PaddleSpeech、阿里云FunASR等ASR算法和模型。
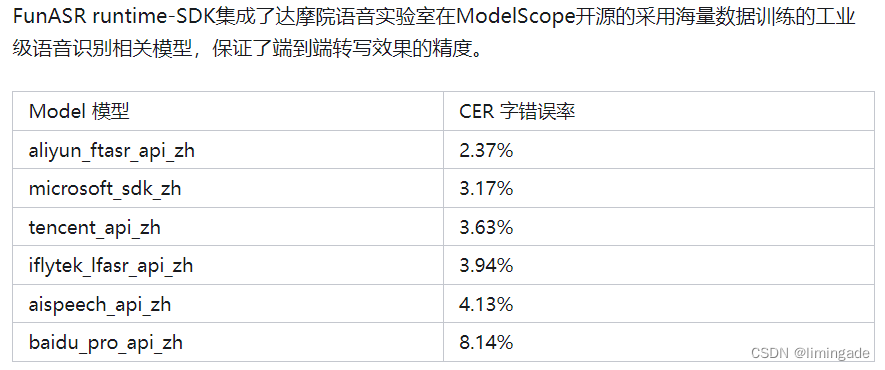
按照从知乎FunASR中搜索的描述,不同模型和算法之间,在识别精度、推理效率、对长音频的支持,以及断句、标点符号标注等方面会存在一些差异,仅供参考。
引用地址:阿里达摩院发布超好用的ASR离线转写SDK - 知乎
小结
本篇章的目的是梳理思路,也顺便理清一下通话语音做文字识别方向后续需要如何做、有哪些功能和能力,要如何架构分阶段去实施。同时在互联网中搜寻了下ASR的行业现状,看看市面上有哪些成熟方案,筛选出用户量够大、实现方式灵活可靠、识别率较高的方案用于后续针对性的选型。
我们自己最直接的需求肯定是免费的、识别率准确的、识别效率高的,最好模型库不大的,并且可以直接装在手机上,来语音了直接就识别的那种。
由于蓝牙电话依赖局域网或互联网进行数据分流,因此语音识别的数据是单机版还是网络传输版其实并没有特殊要求,但从数据安全性的角度来看,做为拥有数据的业务方自然不希望自己的业务数据到处传输到其它平台,所以最好在手机本身就直接能够识别。















 96
96











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









