






概要
在开发过程中,几乎每个需求都需要写一些最基础的crud操作,这在mapper和xml文件中会产生大量重复的代码,引入mybatis-plus可以解决最简单的crud以有效缓解,但大部分人在一些比较复杂的查询操作以及考虑sql优化的场景下依旧选择手写xml文件,但是mybatis-plus并不是无法解决这个问题。这篇文章就记录我对于mybatis-plus中的lambdaQueryWrapper和QueryWarpper的认识
Wrapper的基本使用
String username="chris";
LambdaQueryWrapper<UmsAdmin> queryWrapper= Wrappers.<UmsAdmin>lambdaQuery().eq(UmsAdmin::getUsername,username);
LambdaQueryWrapper<UmsAdmin> queryWrapper1 = new LambdaQueryWrapper<>();
queryWrapper1.eq(UmsAdmin::getUsername,username);
QueryWrapper<UmsAdmin> umsResourceQueryWrapper = new QueryWrapper<UmsAdmin>().eq("username",username);
QueryWrapper<UmsAdmin> umsResourceQueryWrapper1 =Wrappers.<UmsAdmin>query().eq("username",username);两种方式都是可以正常使用的,在lambdaQueryWrapper中使用new的形式会多一行代码,看个人喜好。两个参数中前者是表中的列名,后者是查询的条件
lambdaQueryWrapper在使用eq,like等查询条件时。是会使用lambda表达式的方式,同时提示表中的列名,简化了开发,不需要去特意查看表中列名,以及有效降低了列名不正确导致的sql注入的风险。而QueryWrapper则需要提供正确的列名,同时编译的时候无法检查出错误
如果只是使用一个表的情况下,使用LambdaQueryWrapper会提高开发效率,如果是多个表的情况下,使用QueryWrapper可以实现更为复杂的sql语句。具体使用会在下文提及
QueryWrapper常用函数
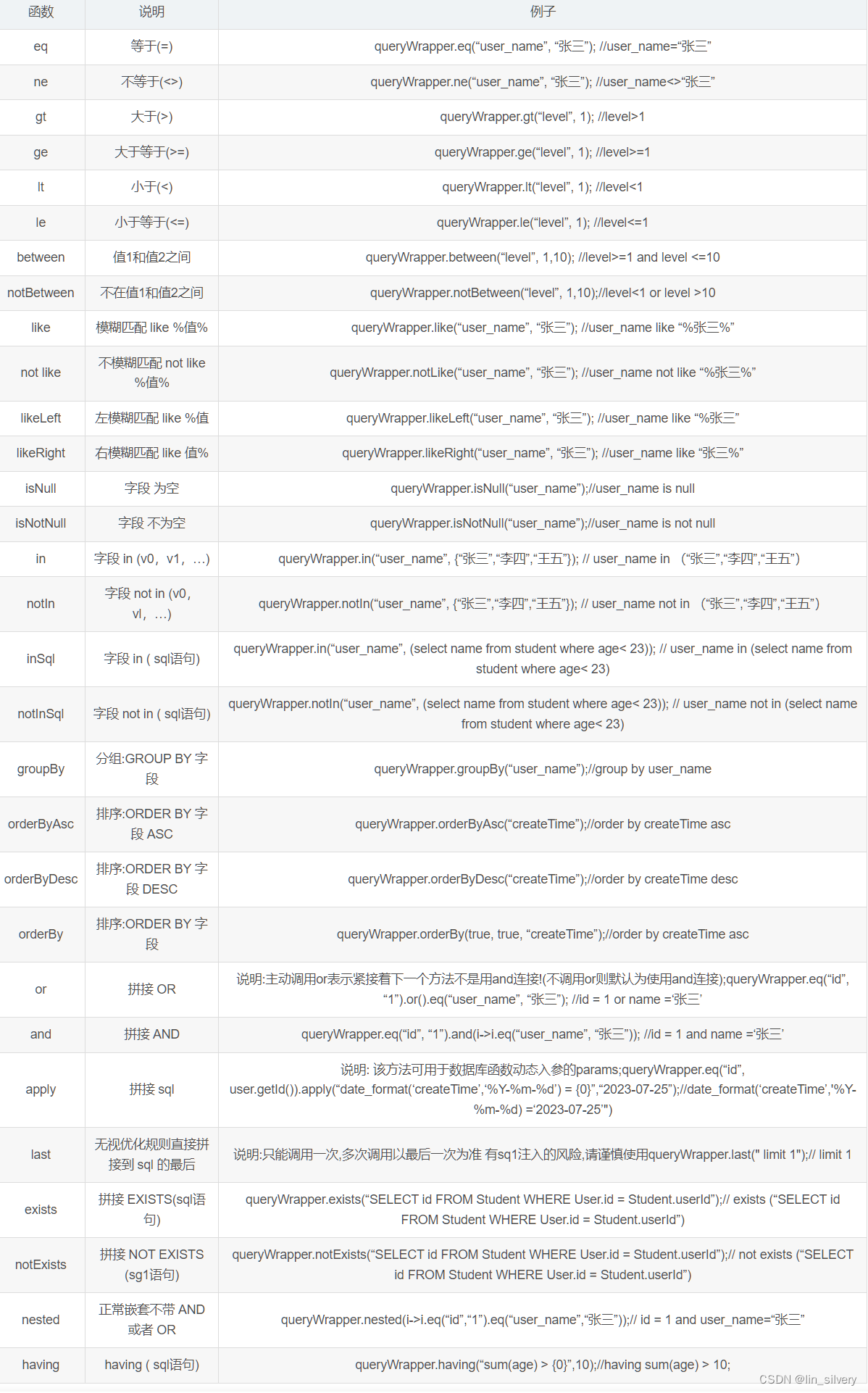
QueryWrapper动态sql以及联表查询
动态sql
UmsAdmin是一个用户实体类,可以通过判断传入参数是否存在等逻辑进行sql的动态拼接
LambdaQueryWrapper<UmsAdmin> queryWrapper =Wrappers.lambdaQuery();
queryWrapper.select(UmsAdmin::getUsername,UmsAdmin::getStatus,UmsAdmin::getEmail).eq(UmsAdm in::getId,umsAdmin.getId());
if(!umsAdmin.getStatus().equals(1)){
queryWrapper.eq(UmsAdmin::getStatus,0);
}
if(umsAdmin.getUsername()!=null){
queryWrapper.eq(UmsAdmin::getUsername,umsAdmin.getUsername());
}
return umsAdminMapper.selectList(queryWrapper);
QueryWrapper联表查询
QueryWrapper的联表查询如果想要使用join连接来优化查询速度的话需要引入mybatis-plus-join
maven项目引入如下依赖
<dependency>
<groupId>com.github.yulichang</groupId>
<artifactId>mybatis-plus-join-boot-starter</artifactId>
<version>1.4.12</version>
</dependency>想使用leftjoin等连接查询需要在mapper文件中继承MPJBaseMapper<>,泛型需要使用查询的主表
public interface UmsResourceDao extends MPJBaseMapper<UmsResource> {
}service代码如下
MPJLambdaWrapper<UmsResource> wrapper = JoinWrappers.lambda(UmsResource.class);
wrapper.selectAll(UmsResource.class)
.leftJoin(UmsRoleResourceRelation.class,UmsRoleResourceRelation::getResourceId,UmsResource::getId)
.leftJoin(UmsAdminRoleRelation.class,UmsAdminRoleRelation::getRoleId,UmsRoleResourceRelation::getRoleId)
.eq(UmsAdminRoleRelation::getAdminId,umsAdmin.getId());对应sql:
select *//此处字段用*代替全部字段
from UmsResource t1
leftjoin UmsRoleResourceRelation t2 on t1.id=t2.resource_id
leftjoin UmsAdminRoleRelation t3 on t3.role_id=t2.role_id
where t3.admin_id=${id}UmsResource是用户所拥有权限资源路径表,连接了角色资源关系表RoleResourceRelation,连接了用户角色关系表UmsAdminRoleRelation,最后的eq是在UmsAdminRoleRelation表中查询与传入参数相同id的用户所对应的角色。这三张表中,数据量最小的是UmsAdminRoleRelation,这一点与接下来的sql优化有关系。
需要注意的是,leftjoin中第一个lambda表达式一定是连表的字段,与第二个lambda表达式的字段不能互换。
若需要多字段比较连表,则可以
.leftJoin(UserAddressDO.class, on -> on
.eq(UserAddressDO::getUserId,UserDO::getId)
.eq(UserAddressDO::getId,UserDO::getId))leftjoin中每一个表或者字段都可以自由设置别名,条件构造器中例如eq,则在字段前加入一个字符串参数代表别名,而leftjoin中则在.class后加入字符串参数代表别名
更多mybatis-plus-join的使用方法,包括子查询,union等用法请移步到官方文档中查看
MyBatis-Plus-Join (yulichang.github.io)
sql性能优化
关于连表查询,我能想到的就是sql中使用数据量小的表来连接数据量大的表,以减少索引扫描循环的次数,以及想使用or连接条件时,需要前后字段都存在索引;不能让索引有范围查找;使用函数运算(该问题可在mysql8版本后使用函数索引优化),否则会出现索引失效问题。而此文章就用我的代码来试验一下使用小表驱动大表的优化效果,依旧是上文的查询
MPJLambdaWrapper<UmsAdminRoleRelation> wrapper1 = JoinWrappers.lambda(UmsAdminRoleRelation.class);
wrapper1.leftJoin(UmsRoleResourceRelation.class,UmsRoleResourceRelation::getRoleId,UmsAdminRoleRelation::getRoleId)
.leftJoin(UmsResource.class,UmsResource::getId,UmsRoleResourceRelation::getResourceId)
.selectAll(UmsResource.class)
.eq(UmsAdminRoleRelation::getAdminId,umsAdmin.getId());对应sql如下:
SELECT t2.id,t2.create_time,t2.name,t2.url,t2.description,t2.category_id
FROM ums_admin_role_relation t
LEFT JOIN ums_role_resource_relation t1 ON (t1.role_id = t.role_id)
LEFT JOIN ums_resource t2 ON (t2.id = t1.resource_id)
WHERE (t.admin_id = ${id})使用explain分析执行计划可以看到两者的执行计划
优化前

优化后

记录两种sql循环1000次后的执行时间
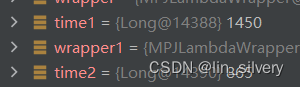
看出有明显的优化
小结
mybatis-plus及其增强件mybatis-plus-join确实是可以实现大部分sql语句,包括一些复杂sql的实现,但是个人认为如果需要修改维护的sql,写在xml语句中的可读性会更强一些。比如在sql优化中,在xml可以直接拿到最终于数据库执行的sql去explain查看执行计划,而mybatis-plus-join则需要跑一次得到其执行的sql。而一些不怎么可能会去修改的复杂sql则可以用其在service中解决,以保证xml文件中保留的都是一些可能需要优化的sql语句

















 1802
1802

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









