







表情包爬取
今天还是入门学习的一篇记录,爬取表情包,斗图再也不怕了!
爬取网址:https://fabiaoqing.com/bqb/index.html
分析url
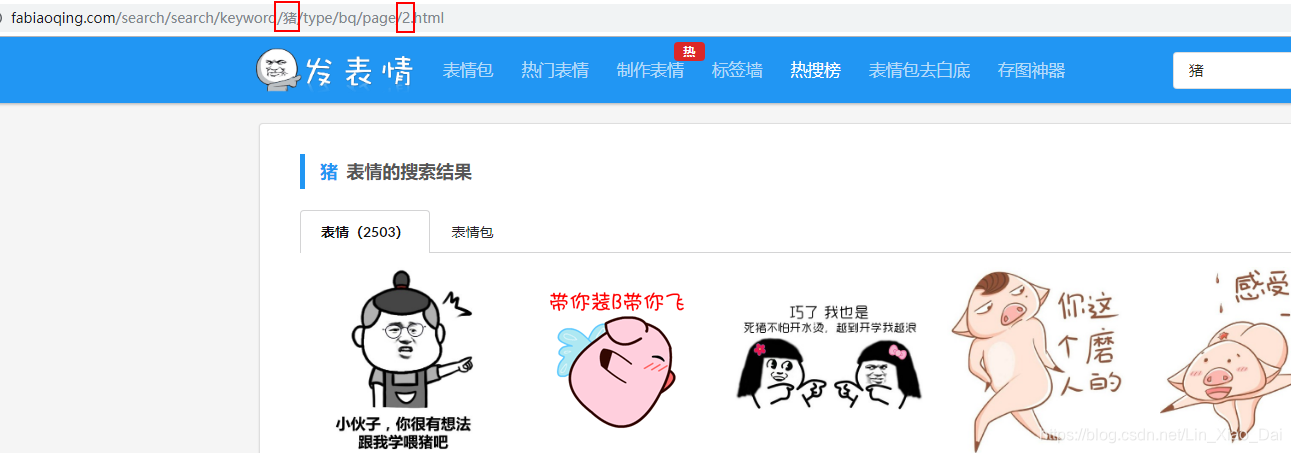
- 进入爬取网址,然后输入关键词翻到第二页,从url的变化上来看主要就是上图红框处有所变化。所以url就很好写了。这里就先先写个basic_url,因为要根据输入的关键词和爬取页数来修改路径。
basic_url = f"https://fabiaoqing.com/search/search/keyword/{keyword}/type/bq/page/{page}.html"
分析源码
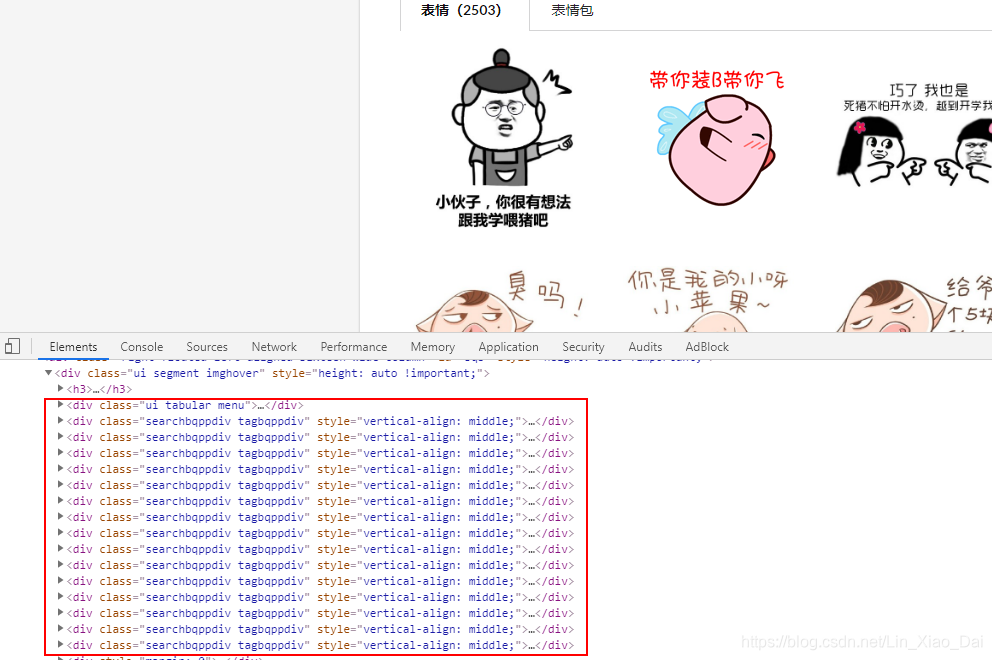
- 每页都有45张表情,而且都是放在一个div里面的。

- 打开一个
<div>看,我红框画出了两个url,我们要爬取的是data-original而不是src,因为src又要跳到别的网址上去,不是真正的图片下载路径。这一次我选用了re模块来进行解析html。
完整代码
"""
下载表情包,每页45张
"""
import datetime
import os
import re
from threading import RLock
import requests
from gevent.threadpool import ThreadPoolExecutor
class Emoji(object):
def __init__(self, key_word, pages):
self.path = f"./{key_word}" # 这里我选择的是当前路径下新建一个文件夹,名字就是搜索关键词
self.threadpool = ThreadPoolExecutor(max_workers=100)
self.lock = RLock()
if not os.path.exists(self.path): # 如果当前路径没有文件夹就先创建一个关键字为名的文件夹
os.mkdir(self.path)
self.count = 1 # 计数爬取了多少表情,也作为表情的文件名
self.basic_url = "https://fabiaoqing.com/search/search/keyword/" + key_word + "/type/bq/page/{}.html"
self.pages = pages
def start(self):
"""
程序启动
:return:
"""
self._get_url_list()
def _get_url_list(self):
"""
这是获取列表页的所有图片的url,然后线程池调用方法
"""
for i in range(1, int(self.pages) + 1):
url = self.basic_url.format(i)
res = requests.get(url=url)
url_list = re.findall(r'<img class="ui image bqppsearch lazy" data-original="(.*?)"', res.text)
self.threadpool.map(self._get_emoji, url_list)
self.threadpool.shutdown()
def _get_emoji(self, url):
res = requests.get(url=url)
# 这里加个互斥锁,不加锁的话计数乱计,文件名都不对
self.lock.acquire()
self._save_emoji(res.content)
self.lock.release()
def _save_emoji(self, data):
with open(self.path + "/{}.gif".format(self.count), "wb") as img:
img.write(data)
print(f"\r以保存{self.count}张表情", end="")
self.count += 1
def main():
key = input('请输入表情关键字:')
pages = input('请输入需要爬取的页数:')
start_time = datetime.datetime.now()
Emoji(key, pages).start()
print("共耗时{}".format(datetime.datetime.now() - start_time))
if __name__ == '__main__':
main()
总结
- 作为一个斗图爱好者,学会爬取表情包就是增加战斗力的必备技能。
- 这次爬取没有使用代理ip,也没有存放在数据库,毕竟斗图还是直接从文件夹里面找比较方便。
- 相比较上一章爬虫学习日记3_猫眼TOP100,这次使用线程池极大地提高了爬取速度。
- 写的不好还请各位海涵,欢迎各位在底下留言或私信,谢谢。














 690
690











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









