







 本文介绍了随机森林的基础知识,包括其作为集成学习方法的Bagging策略,以及如何建立和使用随机森林模型。讨论了随机森林的优缺点,如对特征多的数据表现良好、不易过拟合等,并通过Kaggle泰坦尼克号生存预测实例展示了如何应用随机森林。文章还涵盖了模型参数调整,尤其是通过网格搜索寻找最佳超参数。
本文介绍了随机森林的基础知识,包括其作为集成学习方法的Bagging策略,以及如何建立和使用随机森林模型。讨论了随机森林的优缺点,如对特征多的数据表现良好、不易过拟合等,并通过Kaggle泰坦尼克号生存预测实例展示了如何应用随机森林。文章还涵盖了模型参数调整,尤其是通过网格搜索寻找最佳超参数。
目录
一、基础介绍
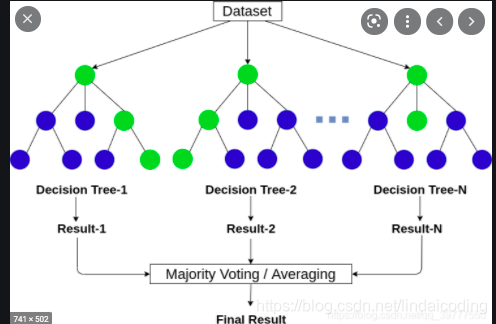
们将探索决策树,并且拓展它到随机森林。这种类型的模型,和我们之前见过的线性和逻辑回归不同,他们没有权重但是有很好的可解释性。随机森林属于 集成学习 中的 Bagging方法。由多个随机树构成,然后通过投票共同学习特征。
因为生长很深的树容易学习到高度不规则的模式,即overfit,在训练集上具有低bias和高variance的特点。随机森林是平均多个深决策树以降低variance的一种方法,其中,决策树是在一个数据集上的不同子集进行训练的,在最终的模型中通常会大大提高性能。
这有些像解决一道预测何时世界末日的难题,你给一个大学生解决,又给了一个在家里自学的人解决。两个人的解法很大概率是不一样的,你提取两个人解法的优势合起来就可以提高解答率。如果给100个人解答这道题目,如果有一些特征预测目标值的能力很强,那么这些特征就会被许多人所选择,这样就会导致树的强相关性。
二、优缺点分析
优点
- 特征很多的数据表现很好,无需做特征选择
- 它可以判断特征的重要程度
- 可以判断出不同特征之间的相互影响
- 不容易过拟合
- 训练速度比较快,容易做成并行方法
- 实现起来比较简单
- 对于不平衡的数据集来说,它可以平衡误差。
- 仅需比较少的数据预处理
缺点
- 随机森林已经被证明在某些噪音较大的分类或回归问题上会过拟合。
- 对于有不同取值的属性的数据,取值划分较多的属性会对随机森林产生更大的影响。
- 当训练数据少于分类类别的时候表现很差。
三 . 如何建立随机森林?
1)用N表示训练集的样本个数,M表示特征数目。
2)输入特征数目m,用于确定决策树上一个节点的决策结果;其中m應远小於M。
3)又放回的抽取随机N次,每次抽取一个,就形成了最终的N个样本。形成一个训练集(也称为bootstrap取樣),並用未抽到的用例样本(out of bag)作預測,評估其誤差。
4)对于每一个节点,随机选择m个特征,决策树上每个节点的决定都是基于这些特征决定的。根据这m个特征,选取最佳的分裂方式。
5)按照步骤1-5建立大量的决策树,就形成随机森林了。
按照上面的步骤,我们用代码跑一遍,会有更清晰的理解了
举一个例子,我们有一群人的是否工作,年龄和是否结婚的数据,做一个模型,用来预测某一个人时高收入还是低收入:
data = pandas.DataFrame([
[0,4,20,0],
[0,4,60,2],
[0,5,40,1],
[1,4,25,1],
[1,5,35,2],
[1,5,55,1]
])
data.columns = ["high_income", "employment", "age", "marital_status"] 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









