






相关文章及代码下载
Matplotlib
Matplotlib是一个Python库,主要用于创建高质量的静态、动态、交互式和三维图形。它提供了丰富的绘图函数和类,可以满足各种数据可视化需求。Matplotlib与NumPy和Pandas等库一起使用时,能够轻松处理大规模的数据集,并进行详细的数据分析。
以下是一些常用到的函数:
matplotlib.pyplot:这是Matplotlib库的主要模块,提供了各种绘图函数和功能。
figure():这个函数用于创建一个新的图形窗口,可以设置图形大小、背景色等属性。
title()、xlabel() 和 ylabel():这些函数用于设置图形的标题、x轴标签和y轴标签。
plot():这个函数用于绘制折线图。可以设置线条颜色、线型和宽度等属性。
scatter():这个函数用于绘制散点图。可以设置点的大小、颜色和形状等属性。
bar():这个函数用于绘制柱状图。可以设置柱子的颜色、位置和宽度等属性。
pie():这个函数用于绘制饼图。可以设置各部分的比例和标签。
subplot():这个函数用于在一个窗口中创建多个子图。可以设置子图的位置和布局。
legend():这个函数用于添加图例,可以设置图例的位置、标签和样式等属性。
show():这个函数用于显示图形。可以设置显示方式(如静态显示或动态显示)和其他参数。
savefig():这个函数用于将图形保存为文件。可以设置文件格式(如PNG、PDF、SVG等)和其他参数。
以下举例2个做简单数据可视化的例子:
1、从网站https://www.kylc.com/stats/global/yearly_overview/g_gdp.html中选取了中国、美国、英国。获取三个国家的从1960-2022年的GDP值,绘制一幅折线图。(从网页中拷贝数据到csv文件中,再编程从文件中获取数据。)
先声明需要引用的库,并初始化字体为SimHei以便使用中文。
filenames定义一个包含三个国家GDP数据的文件名列表。plt.figure():创建一个新的图形。data定义一个包含63个0的列表,用于存储每个国家的GDP数据。year定义一个包含1960到2022年之间的整数列表,用于表示时间轴上的年份。
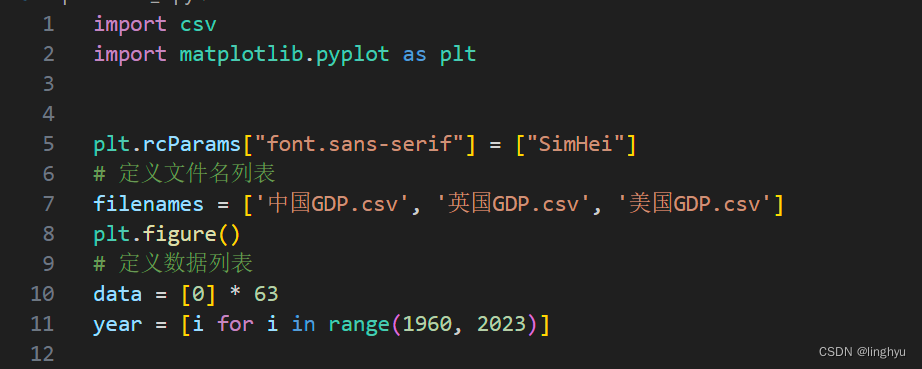
读取三个CSV文件中的GDP数据,进行对csv数据的处理切割,并将其转换为浮点数存储在data列表中,并用plot开始绘制折线图

以下是完整代码:
import csv
import matplotlib.pyplot as plt
plt.rcParams["font.sans-serif"] = ["SimHei"]
# 定义文件名列表
filenames = ['中国GDP.csv', '英国GDP.csv', '美国GDP.csv']
plt.figure()
# 定义数据列表
data = [0] * 63
year = [i for i in range(1960, 2023)]
# 读取CSV文件
for filename in filenames:
with open(filename, 'r' ,encoding='utf-8', errors='ignore') as csvfile:
csvreader = csv.reader(csvfile)
header = next(csvreader) # 跳过标题行
index = 0
for row in csvreader:
line = row[1].split("亿")[0]
if line.find("万") != -1:
line = float(line.replace("万", "")) * 10000
else:
line = float(line)
# print(line)
data[index] = line # 将第二列转换为浮点数并添加到数据列表中
index += 1
data.reverse()
plt.plot(year, data)
data = [0] * 63
# 创建折线图
plt.xlabel('年份')
plt.ylabel('GDP(美元)')
plt.xticks(range(1960,2022,10))
plt.yticks(range(500,300000,15000))
plt.legend(['中国GDP', '英国GDP', '美国GDP'])
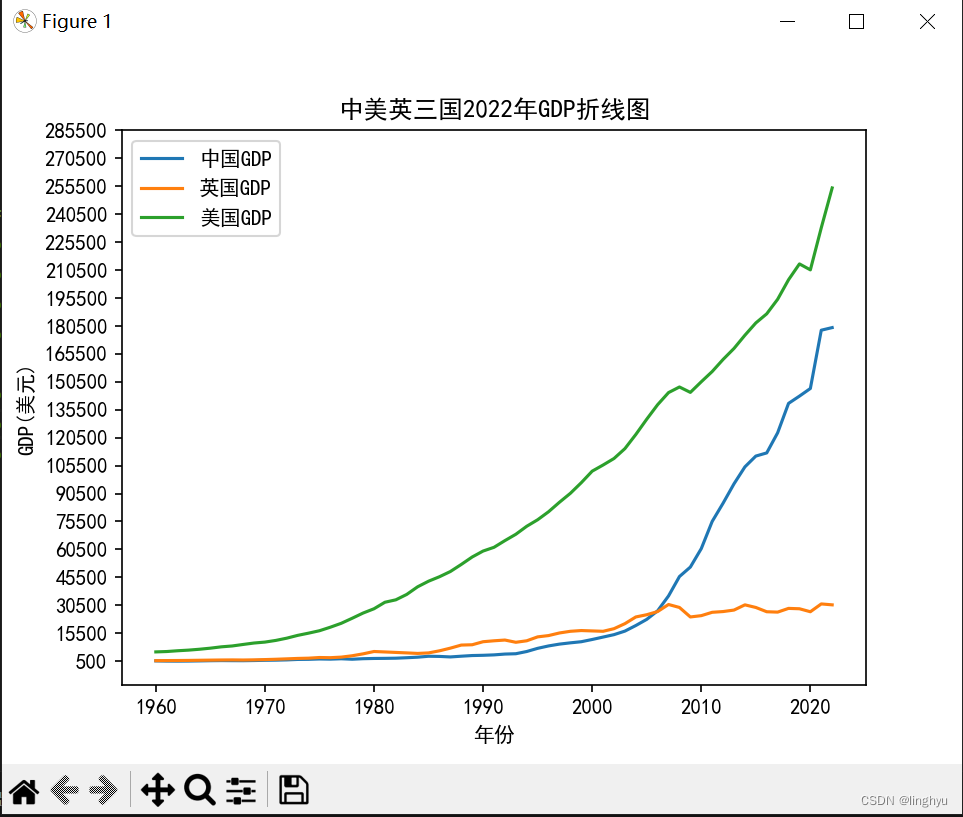
plt.show()以下是代码执行结果:
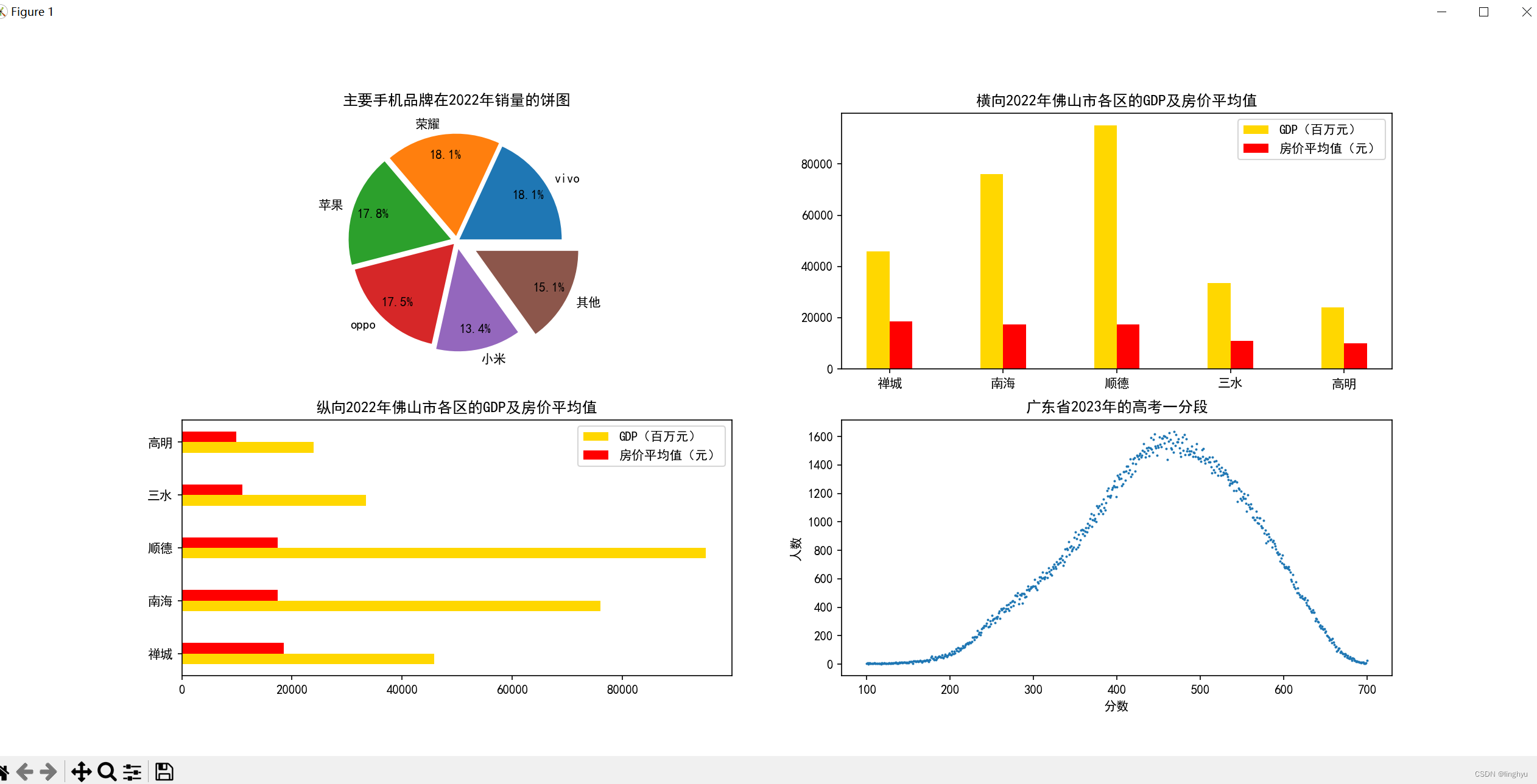
2、在一幅图中绘制四幅子图,其中包括,反映国内或者国际上主要手机品牌在某年或者某季度的销量的饼图。反映广东省各市或者佛山市各区的GDP,以及房价平均值的柱状图(横向和纵向各一幅)。绘制某省2023年的高考一分段的散点图。
先申明应用的库,初始化字体及大小,设置字体为SimHei,以便于中文显示;设置绘图的宽度和高度。其中,25.0表示宽度,8.0表示高度。可以根据需要调整这两个值,以获得更合适的图形大小优化图的展示,并plt.subplots(2, 2)划分为四个子图
第一个子图为饼图,是使用.pie()函数进行绘制。labels定义饼图的标签,即每个扇形的名称。sizes定义饼图每个扇形的尺寸,即每个品牌在2022年销量的百分比。ex定义饼图某些部分的突出显示。这里使用元组的形式指定每个扇形的突出显示程度,值越大,扇形越突出。
使用axs[0, 0].pie()函数绘制饼图,其中sizes参数表示扇形的尺寸,labels参数表示扇形的标签,autopct参数表示饼图中显示的百分比值,explode参数表示饼图中的突出显示部分,labeldistance参数表示标签与扇形的距离,pctdistance参数表示百分比与扇形的距离。
.set_title()函数设置子图的标题。

第二、三个子图为横向纵向的柱状图
areas定义一个包含佛山市各区的名称的列表。gdps定义一个包含佛山市各区的GDP(百万元)的列表。house_prices定义一个包含佛山市各区的房价平均值的列表。
x = np.arange(len(areas))、 y = np.arange(len(areas)):定义一个包含各区名称的索引值的列表。width = 0.2:定义每个柱状图的宽度。
使用axs[0, 1].bar()函数绘制GDP横向柱状图,使用axs[0, 1].bar()函数绘制GDP纵向柱状图,width参数表示柱状图的宽度,color参数表示柱状图
使用axs[0, 1].set_title()函数设置子图的标题。使用axs[0, 1].legend()函数设置图例,其中['GDP(百万元)', '房价平均值(元)']参数表示图例的标签列表。

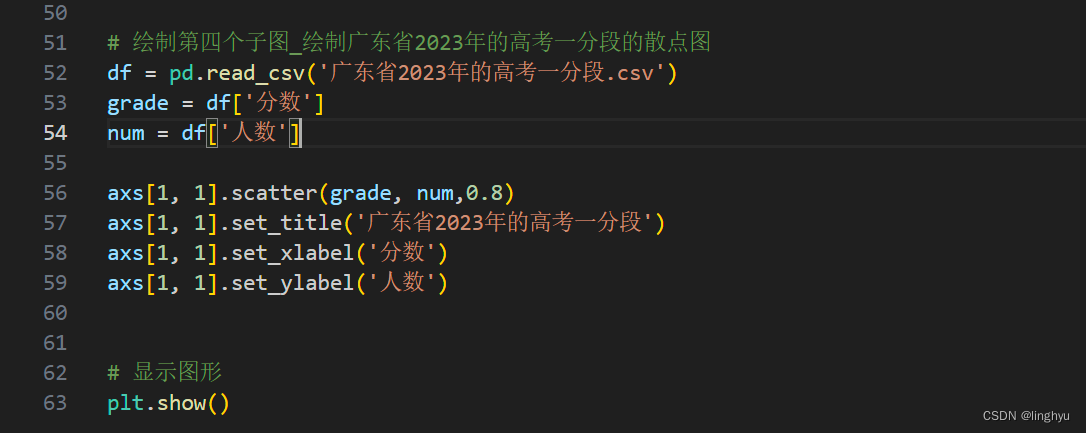
绘制第四个子图为散点图。定义 grade 和 num 列表,分别用于存储分数段和对应考生数量。使用with语句打开csv文件,并使用csv.reader读取文件内容。
跳过标题行,因为分数段和考生数量已经在文件的第一行。遍历csv文件的每一行,将分数段和考生数量分别添加到grade和num列表中。
使用scatter函数绘制散点图,其中x轴为分数段,y轴为考生数量,marker为散点的形状,s为散点的大小。
以下是完整代码:
import matplotlib.pyplot as plt
import numpy as np
import csv
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams['figure.figsize'] = (25.0, 8.0)
# 创建一个新的图形和坐标轴
fig, axs = plt.subplots(2, 2)
# 绘制第一个子图_主要手机品牌在2022年销量的饼图
labels = ['vivo', '荣耀', '苹果', 'oppo', '小米', '其他']
sizes = [5220, 5220, 5130, 5040, 3860, 4350]
ex= (0.03,0.05,0.06,0.04,0.08,0.21) # 指定饼图某些部分的突出显示
axs[0, 0].pie(sizes, labels=labels, autopct='%1.1f%%',explode=ex,labeldistance = 1.1, pctdistance = 0.8)
axs[0, 0].set_title('主要手机品牌在2022年销量的饼图')
# 绘制第二个子图_反映广东省各市或者佛山市各区的GDP(百万元),以及房价平均值(元)的柱状图(横向和纵向各一幅)
areas = ['禅城', '南海', '顺德', '三水', '高明']
gdps = [45841, 75945, 95055, 33430, 23942]
house_prices = [18478, 17404, 17448, 10991, 9890]
x = np.arange(len(areas))
width = 0.2
gold_x = x + width/2
red_x = x + width/2*3
axs[0, 1].bar(gold_x, gdps,width=width , color="gold")
axs[0, 1].bar(red_x, house_prices,width=width , color="red")
axs[0, 1].set_xticks(x+width, labels=areas )
axs[0, 1].set_title('横向2022年佛山市各区的GDP及房价平均值')
axs[0, 1].legend(['GDP(百万元)', '房价平均值(元)'])
# 绘制第三个子图
y = np.arange(len(areas))
height = 0.2
gold_y = y + width/2
red_y = y + width/2*3
axs[1, 0].barh(gold_y, gdps,height=height , color="gold")
axs[1, 0].barh(red_y, house_prices,height=height , color="red")
axs[1, 0].set_yticks(y + height, labels=areas )
axs[1, 0].legend(['GDP(百万元)', '房价平均值(元)'])
axs[1, 0].set_title('纵向2022年佛山市各区的GDP及房价平均值')
# 绘制第四个子图_绘制广东省2023年的高考一分段的散点图
df = pd.read_csv('广东省2023年的高考一分段.csv')
grade = df['分数']
num = df['人数']
'''
index = 0
with open('广东省2023年的高考一分段.csv', 'r' ,encoding='utf-8', errors='ignore') as csvfile:
csvreader = csv.reader(csvfile)
header = next(csvreader) # 跳过标题行
for row in csvreader:
if index % 25 == 0: # 太多数据,筛选让画面好看些,如果需要所有数据删除即可
grade.append(row[0])
num.append(int(row[1]))
index += 1
grade.reverse()
num.sort()
'''
axs[1, 1].scatter(grade, num,0.8)
axs[1, 1].set_title('广东省2023年的高考一分段')
axs[1, 1].set_xlabel('分数')
axs[1, 1].set_ylabel('人数')
# 显示图形
plt.show()
以下是代码的执行结果:
以下是实验代码结构:
















 1490
1490

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









