






SPDK NVMe-oF transport的实现自19.01正式发布以来,差不多快一年时间。在解决各种软件稳定性问题以及和Linux内核互操作兼容的同时,也在性能优化方面不断进行一些尝试,这些尝试主要包括软件和硬件方向。在这篇文章中会讨论软件方面的一些优化方向及目前SPDK NVMe-oF实现的一些工作。鉴于很多SPDK NVMe-oF TCP的用户经常反馈一些性能的问题以及询问一些性能优化的方向。
一. SPDK NVMe-oF TCP的主要性能瓶颈
如果经常关注SPDK官方网站上文档那栏, 就会看到SPDK社区会经常发布一些性能的报告。那么对于测试NVMe盘就会发现以下性能报告的数据:
- 1)测试本地NVMe盘SPDK单CPU core上的IOPS性能差不多是同样配置情况下Linuxkernel 实现的6-10倍之间(使用perf工具).
- 2)测试远端NVMe盘SPDK NVMe-oFRDMA target单CPU core上的IOPS差不多也是同样配置下Linux kernel 实现的6-7.5倍之间(固定CPU core数目,测试不同连接数目>=16).
- 3)测试远端NVMe盘SPDK NVMe-oF TCPtarget单CPU core上的IOPS数据只有同样配置下Linux kernel实现的2-2.8倍左右(固定CPU core数目,测试不同的连接数目>=16).
我们可以看到使用RDMA传输层,对于单CPU core上的性能损失很小,在某些连接NVMe SSD的测试场景下可以忽略不计(因为rdma的latency是以微妙计算的),因为RDMA全称是Remote Directly MemoryAccess,所以在远程数据获取中,主要是具有RDMA功能的网卡参与操作,CPU额外的负担很小。但是使用TCP/IP栈不一样,我们发现在使用TCP/IP栈的时候,其开销非常大。主要可以分为以下两类:
- 用户态和内核态切换的代价。这个代价包括两类:
1. 系统调用的开销(System calloverhead);
2. SPDK用户态程序和内核之间数据的交互,不能很好的实现zero copy。当然如果使用Linux kernel的NVMe/TCP target实现,是不存在切换问题的。因为NVMe/TCP相关的数据和命令从网卡进来,直接通过内核的网络栈,然后送到NVMe的I/O栈进行处理。所以在这一点来讲,内核是有一定优势的。当然内核的劣势在于本地NVMe I/O栈不高效。 - 内核态TCP/IP栈的开销。熟悉TCP/IP栈实现的网络专家们一定非常清楚一个通过的TCP/IP栈的实现,在内核中的调用路径有多长,然后其中的同步的代价(在不同CPU core之间)切换的代价有多大。相比RDMA传输层来讲,TCP/IP的低效,绝对是影响性能的绝大瓶颈。其实这一点在我们评估SPDK iSCSI target和Linux kernel的iSCSI target(LIO)也发现存在同样的问题。
基于以上的分析,开发人员应该可以意识到有以下的优化方向:
- 硬件方向Offload NVMe TCP中的的数据传输。类似iSCSI中有iSER协议,NVMe TCP如果也有offload协议,那么就可以offload给RDMA, FPGA等。当然仅仅offload到RDMA意义不是很大,我们需要一个更广泛以及通用的offload接口。当然目前没有显示卸载(explicit offloading),那么各大致力于offloading解决方案的公司,可以八仙过海各显神通,采用各种隐式offloading的方法。比如在采用SPDK NVMe-oF TCP解决方案的时候,如果Host和target端都可以控制,则可以使用LD PRELOAD的方式替换Socket的API,然后使用自己提供的socket API.
- 软件方向 既然Kernel TCP/IP栈开销这么大。那么我们就这么做:
1)替换掉kernel TCP/IP栈,使用用户态的实现;
2)继续使用kernel TCP/IP栈。在用户态使用的时候,采用一些优化的方法。当然也可以优化kernel TCP/IP 栈,但是这个工作目前不在SPDK工作的范畴中。
二. 软件优化方向
Figure1给出了SPDK NVMe-oF下支持的不同传输层,我们可以看到在TCP西面,目前我们主要支持Posix, VPP 以及还在调研的Seastar实现。总的来讲软件优化可分为用户态和内核态这两类。
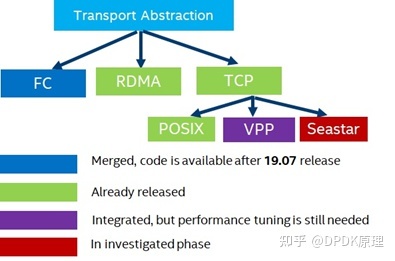
Figure1 SPDK NVMe-oF不同transport的实现
a)用户态TCP/IP软件栈
在SPDK这个项目代码中,我们可以看到在module/sock目录中,我们是有对Socket API的抽象。目前我们官方支持的Socket实现,其实就是不同的TCP/IP栈,包括POSIX(其实就是kernel栈),另外是VPP。
目前来讲,SPDK在和VPP集成的时候,得到的性能优势几乎不明显,在某些测试情况下和使用内核栈的效果差不多,在某些情况下,甚至比Kernel还差。除了绝对性能测试没有占据优势,其实在使用VPP的情况下,还存在以下的问题:我们需要单独启动一个VPP进程。
这么来讲,就会存在这样的开销:
- 1)VPP进程需要使用额外的CPU, 内存等资源;在计算SPDK NVMe-oFTCP单CPU核上IOPS的时候,显然要把VPP占据的CPU资源算入;
- 2)额外的内存copy。在使用kernel TCP/IP的时候,我们知道存在至少一次的内存copy,在我们分析使用VPP的时候,我们发现还存在另外的内存copy。这样即使VPP进程可以使用DPDK PMD driver,也就是典型的用户态TCP/IP DPDK PMD ,性能也没有预想的好。为此在SPDK mailing list上我们特地讨论了这一情况,目前对于VPP和SPDK NVME-oFTCP/IP能带来的好处,存在很大的疑问。
目前SPDK NVMe-oF target端的实现,都采用SPDK的application framework,这个patch其实完全用Seastar 的framework来实现,其实就是嵌入Seastar的框架,然后Seastar也有用户态的TCP/IP DPDK PMD的模式。
这个和VPP集成相比,好处在于不需要另外启动一个进程。当然如果VPP的framework如果也是异步并且能兼容SPDK异步I/O的思想。那么也可以把SPDK NVMe-oF的subsystem实现放入VPP的框架,那么也不用额外启动一个进程。当然这个工作方式,目前未在计划中。此外,使用Seastar的优化还在进行中。
此外不同客户也可以集成自己的TCP/IP栈到SPDK的Socket框架中,代码在SPDK lib/sock以及module/sock目录中。用户可以参照VPP集成的例子,进行自己TCP/IP栈的集成。
b)对于使用kernel TCP/IP软件栈的优化
SPDK项目中,没有一个官方的用户态TCP/IP栈的实现,虽然SPDK project的前身WAIKIKIBEACH有一个libuns栈,但是这个libuns不是开源的,目前也处于停滞状态。虽然目前社区中有很多活跃的栈,比如mTCP,fstack,VPP, Seastar等。SPDK选择集成VPP和试图集成Seastar,但是目前这些工作还没有取得理想的效果。为此SPDK社区决定更好的利用kernel的TCP/IP栈,做了以下的5项左右的工作,其中下面的1-4目前已经在住SPDK主分支中。
I. 非阻塞网络I/O (Non-blockingI/O)
由于SPDK Application framework的架构,我们都采用异步I/O的方式,那么阻塞类型的I/O 编程在SPDK 是不适用,将会极大的影响SPDK性能,并且有可能使得应用hang。为此对于网络我们也采用No- blocking I/O的方式。这个代码其实很早已经存在于SPDK项目中,包括在iSCSI和NVMe-oF TCP中的使用。
II. Batched READ (批处理读)
在读系统调用和内存copy之间做平衡(针对recv/READV这类系统调用)。这个思路主要是考虑是系统调用的开销大,还是内存copy的开销大。我们重新拿出下面的图:
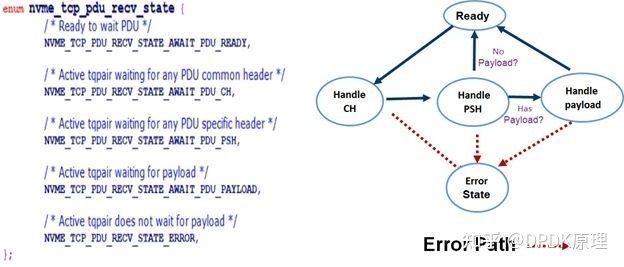
Figure2 NVMe/TCP PDU 生命周期管理
我们可以在Figure2中看到一个NVMe/TCP PDU的包头,分为common header,specificheader等。只有解析了common header,我们才知道PSH要读多少。也就是在用户态获取包的时候,我们发送一个recv的系统调用,获取8bytes,然后解析内容后,再继续发送系统调用(recv)进行内容读取。这个逻辑很正确,但是有很多系统调用的开销。那么要减少读的系统调用,我们可以一次性告诉内核我们要读更多数据,诸如8192bytes,当然。如果内核中没有更多的数据,会直接返回能读出的数据。这个坏处就在于,会导致在用户态的内存copy。因为原来进行读系统调用的时候,每次我们都知道要读到哪些内存地址中,这个内存的地址可以作为参数直接传入。使用这种方式之后,我们一次性传入同一个内存空间地址。那么读入到用户态的时候,我们还需要把相应内存copy到特性的buffer中,进行实际后端的I/O读写。那么这里就存在一个平衡点,到底用多大的内存才合适。
目前这个特性在SPDK NVMe-oF TCP target中开始于19.07之后,并且在19.10中已经集成。主要很好的降低了使用系统调用的频率,虽然带来了一些额外的内存copy开销(不过这一开销,也可以在使用SPDK中集成的IOAT 驱动,然后把CPU进行内存copy的一些工作移交给用户态IOAT驱动管理的CBDMA进行操作)。对于使用内核TCP/IP栈有性能的提升。但是这个特性是现在lib/nvmf/tcp.c的文件中。所以会损害使用用户态TCP/IP栈的性能,所以这个特性在将来20.01的发布版中,会下沉到posix的实现中,即module/sock/posix.c中,这样就不会影响其他SOCK的实现。
III. Batched Async Write(批处理异步写)
目前批批处理写的实现在SPDK NVMe-oF TCP target在19.01公布以后,就一直存在。这个机制和SPDK iSCSI target中是一致的。就是在PDU在写出的时候,我们可以merge一些PDU组成更大的io vector array的方式,然后一次性写入。当然在SPDK 19.10之前的实现,我们在target端采用了针对每一个TCP connection, 有一个write pdu的timer poller (flush_poller, 函数是spdk_nvmf_tcp_qpair_flush_pdus),默认时间大概是50us刷新一次。在19.10之后,即20.01-pre中(也就是我们目前讨论的这个master版本),我们删除了这个timer poller,转而在Posix socket API实现中加入了异步批处理写的的方式(函数是调用名是spdk_sock_writev_async)。这样能提高单核的IOPS,尤其是对NVMe-oF Read workload的IOPS提高特别明显。当然这个机制对iSCSI同样适用。
IV. Message zero copy
这个属于比较小的改进。就是在对网络IO进行读写的时候,尽量不采用readv/writev 的方式, 而是需要首先采用sendmsg或者recvmsg 的方式。另外要使用setsockopt 函数对这个TCP socket connection设定 zero copy的特性, 比如以下的伪代码:
int flag = 1, rc;
rc = setsockopt(sock->fd, SOL_SOCKET,SO_ZEROCOPY, &flag, sizeof(flag));
if (rc == 0) {
printf(“zero copy is successfully set\n”);
}设定了zero copy的属性后,如果我们对于这个socket采用异步写操作, 那么对于写操作的完成确认会有一些代码上的改变。另外这个优化的效果,可能对不同CPU平台效果不一样。
V. 试图采用libaio/liburing 的方式操作网络
我们知道在Linux kernel 5.1的时候, 引入了新的异步I/O的方式,liburing。相对于libaio,这个I/O引擎更加高效。为此在网络中我们也引入使用libaio或者liburing的异步网络I/O的方式。这个目的是进一步降低系统调用的开销。这个在target端特别有意义,因为在target端,我们有一个sock polling group的概念,代码主要位于 lib/sock/sock.c中。每个SPDK thread上可以有一socket group,然后可以集中处理上千上万的TCP连接,那么如果每个connection的系统调用(诸如writev或者sendmsg)能够通过libaio/liburing的方式一次性发送,那么可以进一步减少系统调用。比如一个socket poling group中有4个连接,原来有需要4个写调用(假设每个connection都活跃),那么使用libaio/liburing 这样的方式再理论上可以减少3个系统调用
当然网络I/O和存储中的block I/O不同,网络I/O是FIFO。对于存储的I/O我们可以异步写不同的LBA, 每个I/O的成功和失败不影响其他,只要这些I/O没有overlap。但是网络I/O不一样。比如在同一个TCP连接上写两个I/O:
第一个write:写入4096 bytes;
第二个write:写入4096 bytes;假设我们直接通过libaio或者liburing异步的方式,直接发送两个I/O下去,就会存在partial write(部分写)的问题。使用non-blocking I/O的模式,前一个write返回失败或者部分写成功的时候,我们不能直接写后面的I/O。在网络连接没有问题的情况下,我们要继续写前一个I/O, 只有完全成功以后,才能写后面的I/O。否则根据TCP的特性,对端就会收到错误的数据。所以在同一个TCP连接中,采用异步I/O即采用libaio/liburing的方式去并发多个I/O,似乎不太高效。但是对于同一个polling group多个连接,我们可以调用一个systemcall进行并发。即使有I/O存在部分写的情况,让每一个连接自己去处理就可以了。
目前这项工作正在继续进行中,预计在最终打tag的SPDK 20.01版本中作为实验性质的特性(experimental feature)合入,(或者在更晚的版本中合入。因为要使用liburing异步操作网络,需要更新linux内核(> 5.4.3)。
另外在20.01发布以后,SPDK也会继续发布在20.01版本中SPDK NVMe-oF TCPtarget的性能数据。特别在使用kernel TCP/IP 栈的时候会有显著性能提升,尤其是单核的IOPS(针对读的工作负载)。
三. 结语
NVMe-oF TCP传输层作为NVMe-oF中一个部署方式,在将来一定会在存储领域中广泛部署。SPDKNVMe-oF用户态TCP解决方案目前也在被很多客户进行评估,为此SPDK社区也在不遗余力的进行性能优化(从19.01 正式版本发布以来)。
学习地址:http://ke.qq.com/course/5066203?flowToken=1043717
更多DPDK学习资料有需要的可以自行添加进入学习交流君 羊 793599096 免费获取,或自行报名学习,免费订阅,永久学习,关注我持续更新哦!!!
原文链接:https://blog.csdn.net/weixin_37097605/article/details/103790383

















 2530
2530

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









