







 YOLOv2在YOLO的基础上进行了多方面改进,如批量规范化(Batch Normalization)、高分辨率预训练、GoogLeNet为基础的新网络、Anchor Boxes优化、维度聚类等,提升了目标检测的精度和速度。通过多尺度训练和数据增广,YOLOv2在ImageNet和COCO数据集上表现出色,实现了高效且准确的检测效果。
YOLOv2在YOLO的基础上进行了多方面改进,如批量规范化(Batch Normalization)、高分辨率预训练、GoogLeNet为基础的新网络、Anchor Boxes优化、维度聚类等,提升了目标检测的精度和速度。通过多尺度训练和数据增广,YOLOv2在ImageNet和COCO数据集上表现出色,实现了高效且准确的检测效果。
一. 久违的新版本
YOLO 问世已久,不过风头被SSD盖过不少,原作者自然不甘心,YOLO v2 的提出给我们带来了什么呢?
先看一下其在 v1的基础上做了哪些改进,直接引用作者的实验结果了:
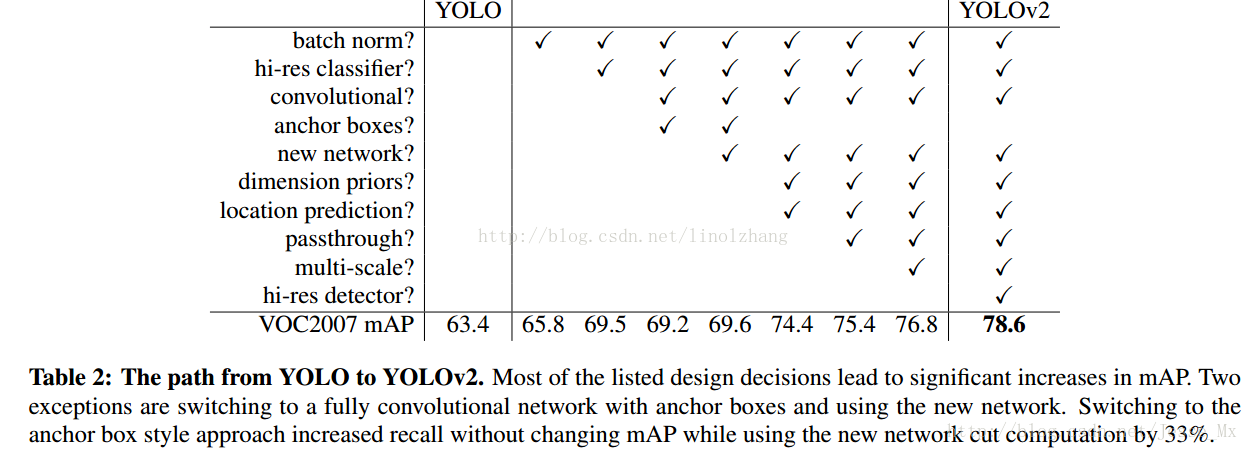
条目不少,好多Trick,我们一个一个来看:
A)Batch Normalization(批量规范化)
先建立这样一个观点: 对数据进行预处理(统一格式、均衡化、去噪等)能够大大提高训练速度,提升训练效果。
批量规范化 正是基于这个假设的实践,对每一层输入的数据进行加工。示意图:
Batch Normalization,简称 BN,由Google提出,是指对数据的 归一化、规范化、正态化。BN 作为近几年最火爆的Trick之一,主流的CNN都已集成。
该方法的提出基于以下背景:

1)神经网络每层输入的分布总是发生变化,通过标准化上层输出,均衡输入数据分布,加快训练速度;
可以设置较大的学习率和衰减,而不用去care初始参数,BN总能快速收敛,调参狗的福音。
2)通过规范化输入,降低激活函数在特定输入区间达到饱和状态的概率,避免 gradient vanishing 问题;
举个例子:0.95^64 ≈ 0.0375 计算累积会产生数据偏离中心,导致误差的放大或缩小。
3)输入规范化对应样本正则化,在一定程度上可以替代 Drop Out;
Drop Out的比例也可以被无视了,全自动的节奏。
BN 的做法是 在卷积池化之后,激活函数之前,对每个数据输出进行规范化(均值为 0,方差为 1)。
公式很简单,第一部分是 Batch内数据归一化(其中 E为Batch均值,Var为方差),Batch数据近似代表了整体训练数据。
第二部分是亮点,即引入 附加参数 γ 和 β(Scale & Shift
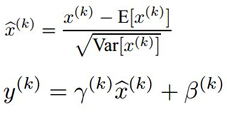
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3806
3806

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









