







目录
2.1 起源:从Torch到PyTorch的Python化转型

🎬 攻城狮7号:个人主页
🔥 个人专栏:《AI前沿技术要闻》
⛺️ 君子慎独!
🌈 大家好,欢迎来访我的博客!
⛳️ 此篇文章主要介绍 TensorFlow与PyTorch
📚 本期文章收录在《AI前沿技术要闻》,大家有兴趣可以自行查看!
⛺️ 欢迎各位 ✔️ 点赞 👍 收藏 ⭐留言 📝!
引言:人工智能时代的操作系统之争
在当今人工智能领域,深度学习框架犹如操作系统般重要,承载着算法开发、模型训练与部署的核心任务。其中,TensorFlow与PyTorch堪称双璧,占据了学术圈和工业界的主流市场。据2023年IEEE Spectrum的调查显示,TensorFlow的使用率为48%,PyTorch为42%,两者合计占据近90%的市场份额。本文将深入剖析这两大框架的发展脉络、技术特性及应用生态,揭示它们如何塑造了AI的现在与未来。
一、TensorFlow:工业级AI的基石
1.1 起源:从Google Brain到开源社区
TensorFlow由Google Brain团队于2011年启动研发,最初代号为DistBelief,是Google内部使用的深度学习框架。2015年11月,Google将其开源并更名为TensorFlow,意为"张量在计算图中的流动"。这一命名精准概括了其核心设计理念:通过有向图表示计算过程,张量(多维数组)作为数据载体在图中流动。
早期版本的TensorFlow专注于大规模分布式训练,支持CPU、GPU等异构计算设备,迅速在工业界获得青睐。2017年发布的1.0版本引入了Estimators高级API,简化了模型开发流程,进一步推动了其在企业级应用中的普及。
1.2 发展历程:从静态图到动态图的演进
TensorFlow的发展历程可分为三个阶段:
静态图时代(2015-2019):初期版本以静态计算图为核心,需要先定义计算图再执行,这种设计有利于优化和部署,但调试难度较大。典型代表是TensorFlow 1.x系列,广泛应用于生产环境。
动态图探索(2018-2020):为应对PyTorch动态图的竞争压力,TensorFlow在2.0版本中引入了Eager Execution模式,支持即时执行,大幅提升了调试体验。同时,Keras成为官方推荐的高层API,进一步简化了模型构建。
端到端生态完善(2020至今):TensorFlow Lite(端侧部署)、TensorFlow Extended(TFX,企业级流水线)、TensorFlow Probability(概率编程)等组件的成熟,使其成为支持从研究到生产全流程的综合性平台。
1.3 技术特性:工业级稳定性与部署能力
TensorFlow的核心优势在于其强大的工业级部署能力:
- 分布式训练:支持参数服务器(Parameter Server)和AllReduce等多种分布式训练策略,可扩展至数千个计算节点。Google Brain团队曾使用TensorFlow在16,000个TPU上训练出具有1.6万亿参数的Switch Transformer。
- 多平台支持:除了传统的服务器端部署,TensorFlow还提供了针对移动设备(TensorFlow Lite)、边缘设备(TensorFlow Edge)和Web端(TensorFlow.js)的优化支持。例如,三星Galaxy S23系列手机内置的AI相机就使用TensorFlow Lite运行图像增强模型。
- 模型压缩与量化:通过TensorFlow Model Optimization Toolkit,可将模型大小压缩至原来的1/4甚至更小,同时保持精度损失在可接受范围内。这一技术在自动驾驶领域尤为重要,例如特斯拉的Autopilot系统就依赖压缩后的TensorFlow模型实现实时目标检测。
1.4 应用场景:从搜索广告到自动驾驶
TensorFlow在工业界的应用极为广泛:
- Google自身业务:Google Search、Google Translate、YouTube推荐系统等核心业务均基于TensorFlow构建。例如,Google Translate的神经机器翻译模型在2016年切换至TensorFlow后,翻译质量提升了85%。
- 金融领域:高盛使用TensorFlow构建市场风险预测模型,摩根士丹利利用其进行算法交易,蚂蚁集团则将其应用于反欺诈系统,准确率超过99.9%。
- 自动驾驶:Waymo的激光雷达点云处理、特斯拉的视觉感知系统均采用TensorFlow开发。据特斯拉2023年AI Day披露,其最新的Occupancy Network模型基于TensorFlow训练,能够预测3D空间中的物体分布。
1.5 代表性大模型
- BERT(Bidirectional Encoder Representations from Transformers):由Google于2018年开发,基于TensorFlow实现。BERT在11项NLP任务中刷新了当时的SOTA(State-of-the-Art)成绩,开启了预训练-微调(Pre-train & Fine-tune)的范式革命。
- GPT系列早期版本:OpenAI的GPT-1和GPT-2模型最初基于TensorFlow开发。虽然GPT-3及后续版本转向了自研框架,但TensorFlow在GPT的早期研发中起到了关键作用。
- AlphaFold:DeepMind开发的蛋白质结构预测模型,在CASP14竞赛中以92.4分(满分100分)的成绩击败所有对手。AlphaFold 2.0版本基于TensorFlow构建,其预测精度达到了与实验方法相媲美的水平。
二、PyTorch:科研创新的首选
2.1 起源:从Torch到PyTorch的Python化转型
PyTorch的前身是Torch,一个使用Lua语言的机器学习框架,由纽约大学的Yoshua Bengio团队于2002年开发。由于Lua语言的普及度较低,Torch在学术界的影响力有限。2016年,Facebook AI Research(FAIR)团队基于Torch重新设计,推出了Python接口的PyTorch,一举解决了语言门槛问题。
2.2 发展历程:动态图驱动的快速迭代
PyTorch的发展呈现出明显的动态图驱动特征:
初创期(2016-2018):凭借动态计算图的天然优势(即时执行、直观调试),PyTorch迅速在学术界获得青睐。2017年,FAIR团队使用PyTorch实现了ImageNet图像分类冠军模型ResNet,进一步巩固了其地位。
成长期(2018-2020):随着PyTorch 1.0版本的发布,其稳定性和性能得到大幅提升。TorchScript的引入允许将PyTorch模型转换为静态图,兼顾了部署效率。这一时期,PyTorch在自然语言处理领域的应用快速增长,Transformer架构的流行进一步推动了其普及。
生态扩张期(2020至今):PyTorch Lightning、Hugging Face Transformers等高层库的出现,极大简化了模型开发流程。Meta(原Facebook)推出的PyTorch Mobile则加强了其在移动端的部署能力,与TensorFlow Lite形成竞争。
2.3 技术特性:科研友好与灵活创新
PyTorch的核心优势在于其科研友好性和灵活性:
- 动态计算图:PyTorch采用动态图机制,代码执行流程与Python语法完全一致,调试时可直接使用print语句或断点,极大降低了开发门槛。这种特性尤其适合快速原型开发和创新算法探索。
- 丰富的高层库支持:PyTorch Lightning提供了训练循环的模板代码,Hugging Face Transformers封装了大量预训练模型(如BERT、GPT、T5等),TorchVision则提供了图像领域的数据集和预训练模型。这些工具链使得研究人员能够快速实现想法。
- 社区驱动的创新:PyTorch社区以学术研究为导向,新算法往往优先在PyTorch上实现。例如,AlphaFold的初始版本基于PyTorch开发,随后才移植到TensorFlow;OpenAI的GPT系列模型也逐渐转向PyTorch生态。
2.4 应用场景:从学术研究到快速落地
PyTorch在学术界占据绝对主导地位,据2023年NeurIPS会议统计,82%的论文使用PyTorch实现。同时,其在工业界的应用也快速增长:
- 学术研究:计算机视觉领域的Mask R-CNN、DETR,自然语言处理领域的BERT、GPT,语音识别领域的Wav2Vec 2.0等标志性成果均基于PyTorch开发。
- 互联网公司:Meta的Instagram推荐系统、Twitter的情感分析模型、Netflix的视频内容理解均采用PyTorch。2023年,Meta推出的LLaMA系列大模型基于PyTorch开发,参数量从7B到65B不等,开源后引发了社区的广泛研究。
- 医疗领域:DeepMind的AlphaFold、斯坦福大学的癌症检测模型、英伟达的医学图像分割工具Clara Train均基于PyTorch构建。例如,AlphaFold 2.0预测了人类蛋白质组中98.5%的结构,为药物研发提供了革命性工具。
2.5 代表性大模型
- GPT系列:OpenAI的GPT-3、GPT-4,以及开源社区的LLaMA、Alpaca、Vicuna等模型均基于PyTorch开发。GPT-4拥有1.8万亿参数,在多个领域的表现接近人类专家水平。
- Stable Diffusion:开源的文本到图像生成模型,基于PyTorch实现。Stable Diffusion 2.0版本在图像生成质量和多样性方面取得了显著突破,引发了AI绘画的热潮。
- Segment Anything Model (SAM):Meta于2023年发布的图像分割模型,基于PyTorch开发。SAM能够从图像中自动分割出任何物体,被称为"图像分割的GPT时刻"。
三、技术对比:静态图与动态图的哲学之争
3.1 计算图模型
TensorFlow采用静态计算图,需要先定义图结构再执行,这种方式有利于优化和部署,但调试困难。PyTorch采用动态计算图,代码执行时即时构建计算图,调试直观但部署时需要额外转换。
3.2 API设计
TensorFlow提供多层次API,包括底层的TensorFlow Core、中层的Keras和高层的Estimators,适合不同水平的开发者。PyTorch的API设计更贴近Python原生风格,代码简洁易读。
例如:
import torch
import torch.nn as nn
class Net(nn.Module):
def __init__(self):
super().__init__() # Python 3简写
self.flatten = nn.Flatten() # 增加展平层
self.fc1 = nn.Linear(784, 256)
self.relu = nn.ReLU() # 规范激活函数定义
self.fc2 = nn.Linear(256, 10)
# self.softmax = nn.Softmax(dim=1) # 根据需求决定是否添加
def forward(self, x):
x = self.flatten(x) # 展平输入:例如从(N,1,28,28)到(N,784)
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
# x = self.softmax(x) # 若使用CrossEntropyLoss则不需要
return x3.3 部署生态
TensorFlow在部署生态方面更为成熟,支持从云端到边缘的全场景覆盖,提供了TensorFlow Serving、TensorFlow Lite、TensorFlow.js等专用工具。PyTorch的部署工具相对较少,但PyTorch Mobile和TorchServe正在快速追赶。
3.4 社区与资源
TensorFlow社区以工业应用为导向,拥有大量企业级案例和教程。PyTorch社区则以学术研究为核心,新算法和论文复现代码更多使用PyTorch。Hugging Face的Transformers库对两者均提供支持,进一步促进了技术融合。
四、大模型时代的框架选择
在大模型训练与部署的场景下,框架选择需要综合考虑以下因素:
4.1 研究与创新
如果需要快速验证新算法或进行学术研究,PyTorch是更优选择。其动态图特性和丰富的高层库支持,能够显著提升研发效率。例如,OpenAI在开发GPT系列模型时,从TensorFlow转向PyTorch,主要原因是PyTorch更适合快速迭代和创新。
4.2 工业级部署
对于需要大规模部署的生产环境,TensorFlow更为成熟。其完善的部署工具链和对异构设备的支持,能够满足企业级应用的稳定性和性能要求。例如,Google的搜索引擎和自动驾驶系统均基于TensorFlow构建。
4.3 混合架构趋势
越来越多的项目采用"PyTorch研发,TensorFlow部署"的混合架构。例如,Meta在研发LLaMA模型时使用PyTorch,部署时则转换为TensorFlow格式以获得更好的性能。Hugging Face的Transformers库提供了两者之间的转换工具,进一步推动了这种混合使用模式。
五、算法模型和深度学习框架的区别
一句话总结:MoE、GNN、VAE、ANN、CNN、GAN、RNN等是AI算法模型/架构,定义“做什么”;TensorFlow、PyTorch是深度学习框架,提供“怎么做”的工具库。前者是食谱,后者是厨房。
核心区别:
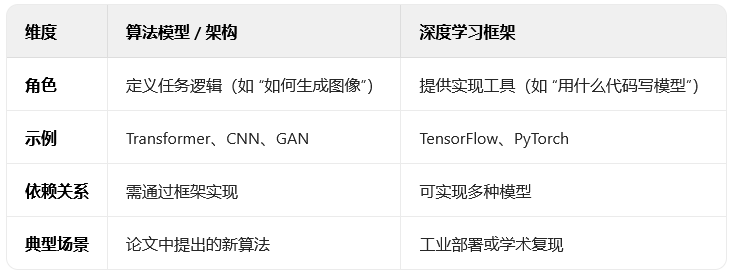
联系:
- 同一模型(如BERT)可基于不同框架实现(如Hugging Face同时支持PyTorch和TensorFlow)。
- 框架提供优化工具(如分布式训练、量化),帮助模型落地(如用TensorFlow Lite部署CNN到手机)。
模型是“要盖的楼”(如别墅、摩天大楼),框架是“施工队”(用PyTorch的灵活脚手架,或TensorFlow的标准化模板)。
六、结论:双雄并立,共同塑造AI未来
TensorFlow和PyTorch的竞争与共生,推动了深度学习技术的快速发展。TensorFlow凭借其工业级部署能力,成为企业应用的首选;PyTorch则以科研友好性,引领学术创新的潮流。在大模型时代,两者的差异逐渐缩小,而专业化和硬件协同将成为未来竞争的关键。无论是研究者还是开发者,掌握这两大框架的核心技术,都将在AI领域占据先机。工具的选择取决于问题的本质,而TensorFlow和PyTorch共同构成了我们探索AI边界的工具箱。
看到这里了还不给博主点一个:
⛳️ 点赞☀️收藏 ⭐️ 关注!
💛 💙 💜 ❤️ 💚💓 💗 💕 💞 💘 💖
再次感谢大家的支持!
你们的点赞就是博主更新最大的动力!



















 5174
5174

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











