







概述
最近一直在为系统的稳定性努力着,但凡线上有一些问题,都不轻易放过。尤其是在2023年,大环境不好的情况下,如果it团队系统稳定性都做的不好的话,很容易提桶走人的。
事情是这样的,在2023年3月8日的晚上七点左右,调用B服务RPC接口的其他服务,都陆续开始报【接口调用超时异常】,B服务已经有一个多月没有上线过了,而出故障的时间当天,流量也没陡增。
这种突然出问题,但跟流量和发版又没有关系的,一般就是先重启,因为大概率是触发某个隐藏的bug导致服务慢慢不可用了。注意,当时是没让运维dump pod的运行信息的,因为线上报错的信息比较多了,也影响到了用户,只能先止损。果然重启后,错误信息立马消失了,一直到当天凌晨,都没有再报错了。
但是单单看一堆超时的错误信息,一时之间,是很难找出根因的。那天我一直看到了晚上11点,只是得到一个粗浅的结论:
错误信息,集中在B服务的某些pod上,有蛮多线程block住了。
隔天早上回到办公室后,就申请让B服务开通arms(阿里的应用实时监控服务),坐等错误再次发生。阿里的arms还是很强大的,但是是付费的且不便宜,一般平时不开的。
一直等到了3月9号的下午五点多,B服务的接口又开始超时了,这次我赶紧到arms的事件中心大盘里,看看有无异常的事件发生,猜我看到了啥?

居然有死锁,生平第一次在线上遇到过。查看了arms打印出来的详细日志,发现是两个线程,在两个ConcurrentHashMap对象之间,相互等待了。
[ARMS] Found deadlock:
"thread_14" Id=xxxx BLOCKED on java.util.concurrent.ConcurrentHashMap$Node@687bfd0d owned by "Dubbo-thread-499" Id=1044
at java.util.concurrent.ConcurrentHashMap.putVal(ConcurrentHashMap.java:1027)
- blocked on java.util.concurrent.ConcurrentHashMap$Node@687bfd0d
at java.util.concurrent.ConcurrentHashMap.putIfAbsent(ConcurrentHashMap.java:1535)
"Dubbo-thread-499" Id=cccc BLOCKED on java.util.concurrent.ConcurrentHashMap$ReservationNode@2205946f owned by "thread_14" Id=yyy
at java.util.concurrent.ConcurrentHashMap.putVal(ConcurrentHashMap.java:1027)
- blocked on java.util.concurrent.ConcurrentHashMap$ReservationNode@2205946f
at java.util.concurrent.ConcurrentHashMap.putIfAbsent(ConcurrentHashMap.java:1535)
也就是说:
- 线程thread_14在已获得某种资源后,还想继续获取687bfd0d对象的锁,而这把锁整被线程Dubbo-thread-499拿在手上;
- 线程Dubbo-thread-499在已获得某种资源后,还想继续获取2205946f对象的锁,而这把锁整被线程thread_14拿在手上;
但是出自Doug Lea大神的ConcurrentHashMap怎么可能出现死锁呢? 于是就在本地简单写了一段程序验证了一下:
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
public class TestConcurrentMapDeadlock {
public static void main(String[] args) {
Map<String, Integer> concurrentHashMap1 = new ConcurrentHashMap<>(16);
Map<String, Integer> concurrentHashMap2 = new ConcurrentHashMap<>(16);
new Thread(() -> concurrentHashMap1.computeIfAbsent("a", key -> {
concurrentHashMap2.computeIfAbsent("b", key2 -> 2);
return 1;
})).start();
new Thread(() -> concurrentHashMap2.computeIfAbsent("b", key -> {
concurrentHashMap1.computeIfAbsent("a", key2 -> 2);
return 1;
})).start();
}
}
在Intellij idea上运行上面的代码,并使用idea自带的Dump Threads功能,会发现真的触发死锁了。

后来看了一下jdk 1.8的ConcurrentHashMap的computeIfAbsent源代码,在并发的情况下,确实有概率性会触发死锁。
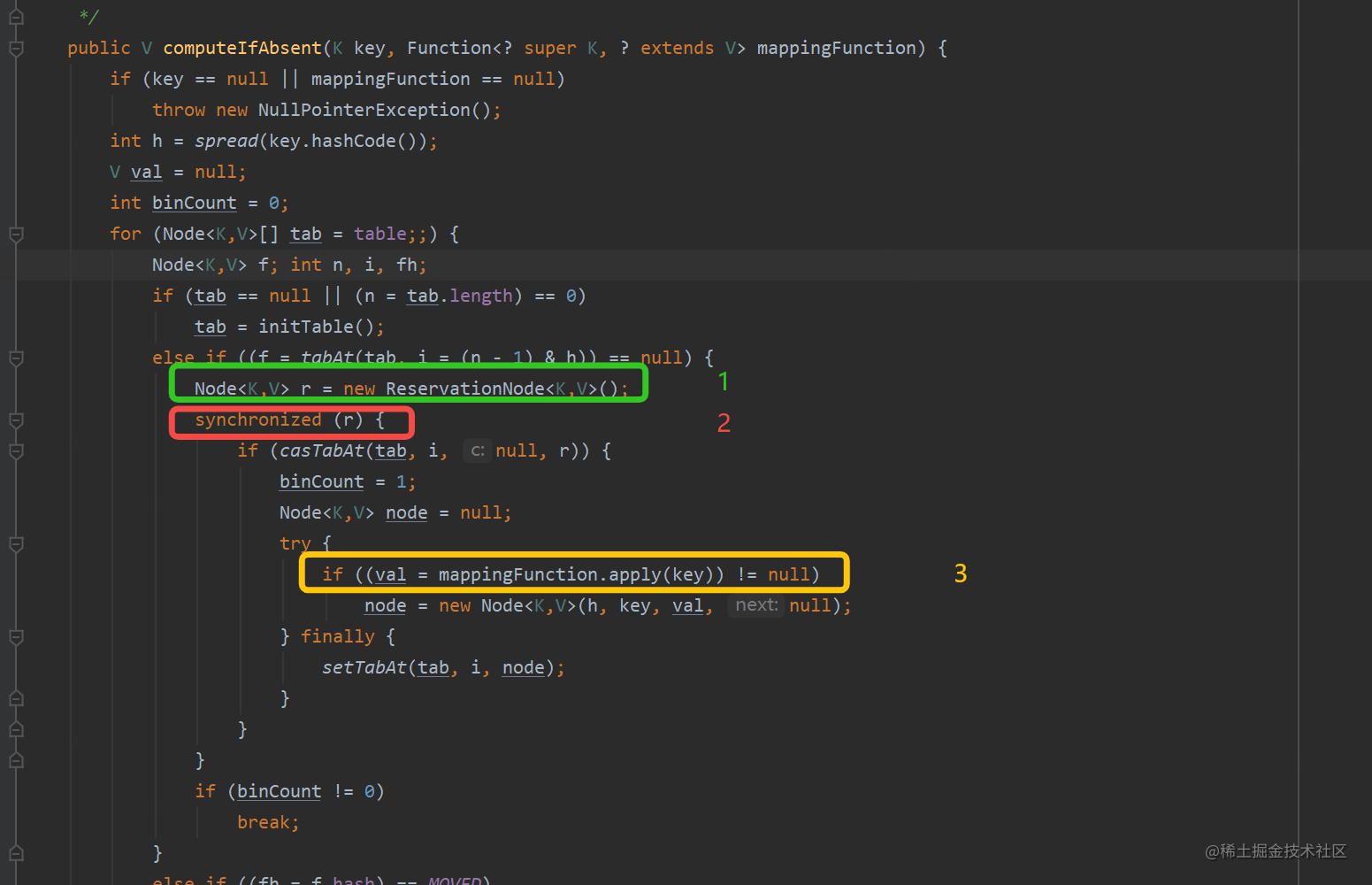
大概的执行序列是:
- 1、生成ReservationNode预占节点;
- 2、对该节点进行加锁(这里是重点),然后将该节点放入指定key的槽位中;
- 3、执行我们传入的计算逻辑,当我们计算逻辑中包含有computeIfAbsent时,此时代码会重复上面的1~3步骤
到这里就大概明白了,当执行一次computeIfAbsent的嵌套逻辑时,会有两个ReservationNode对象会被加锁,那在并发的情况下,是可能会产生死锁的。
那具体是哪行代码触发的呢? 其实阿里的arms是有完整打印出来的,由于有敏感信息,这里不能贴出来。但是触发的诱因可以说一下:
线程thread_14,是想更新一个用户的手机号信息,对应的代码逻辑会操作两个ConcurrentHashMap,先操作map1,再操作map2,这个两个map是作为本地缓存使用的,都会对其进行computeIfAbsent操作。而Dubbo-thread-499也是一样,也会操作这两个map,先操作map2,再操作map1。当有并发的情况下,处理的又是同一个手机号的时候,就可能触发死锁。
至于thread_14操作完map1这个本地缓存后,为啥还要去操作map2这个本地缓存? 我看了业务逻辑实现后,发现是没有必要的,因为这两份本地缓存的数据,都有对应的业务逻辑代码去保证它的准确性。后来问了一下开发这块的老同事,得到的回复是:
顺便更新一下另外一个map,提升一些性能。
好吧,这个就真的是好心做坏事了。
解决这次的死锁的方案也很简单,就是断掉其中一条路,避免死锁就可以了。正如刚才上面分析的,两份本地缓存都有各自的业务逻辑去确保它的准确性,没必要顺手去更新别人家的缓存。
在2023年3月16日发版后,直到今天,2023年3月20日,暂时没有死锁的告警了。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









