







之前做过数据平台,对于实时数据采集,使用了Flink。现在想想,在数据开发平台中,Flink的身影几乎无处不在,由于之前是边用边学,总体有点混乱,借此空隙,整理一下Flink的内容,算是一个知识积累,同时也分享给大家。
注意:由于框架不同版本改造会有些使用的不同,因此本次系列中使用基本框架是 Flink-1.19.x,Flink支持多种语言,这里的所有代码都是使用java,JDK版本使用的是19。
代码参考:https://github.com/forever1986/flink-study.git
目录
上一章了解了水位线概念,但是还是有2个问题没有解决,一个是多算子和多并行度水位线如何传递,一个是乱序下迟到的数据如何处理。本章将来深入了解Flink如何实现和解决这些问题
1 水位线的传递
从前面的示例中可知,在某个算子之后使用assignTimestampsAndWatermarks方法进行水位线设置,也就是意味着从该算子开始就会有水位线标识传递。但是前面还没有讨论的就是多并行度问题。下面一张示意图,下面就以这张图来讲解
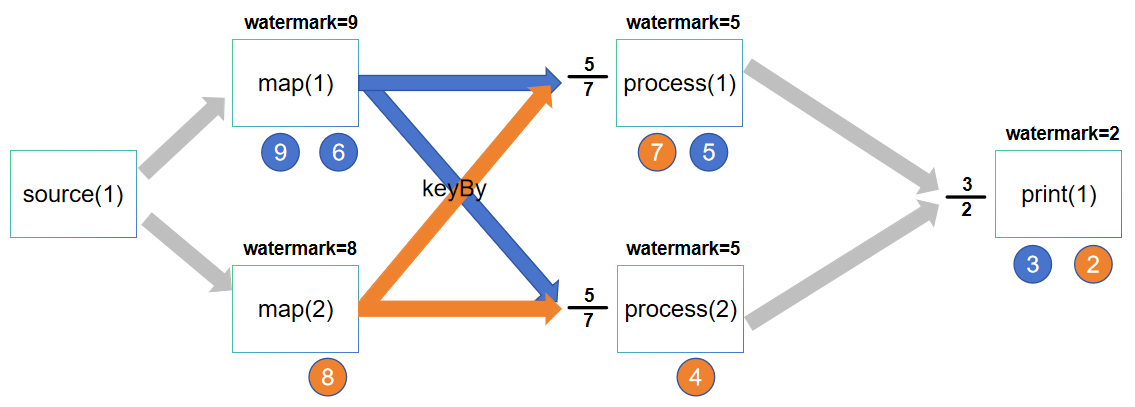
说明一下这张图:
- 这张图是数据从source到map、经过keyBy之后,再到process和print,其中map和process并行度为2,source和print并行度为1。并且在map算子开始就设置了watermark。keyBy主要是做一个奇数偶数分离,奇数数据到process(1)中计算,偶数数据到process(2)中计算。
- 蓝色圆球数据代表从map(1)的并行度发出,总共发出3、5、6、9数据;橙色圆球数据代表从map(2)的并行度发出,总共发出2、4、7、8数据;
- 算子上面的watermark=x代表当前该并行度的watermark水位线。
1.1 算子之间传递
就以上图为例,说一下水位线在不同算子之间的传输规则:
1)当有多个源或者并行度源算子,他们之间的watermark是自己生成的,并不会互相干扰。从上图中,map(1)和map(2)就是各自生成自己的watermark。
2)数据流上面的不同算子,他们同一时刻的水位线(watermark)是不同的。从上图中,map、process和print三个算子之间的水位线在这一时刻都是不同的map水位线分别为9和8,process的水位线为5,print的水位线为2。
3)对于当前算子的下游算子有多个并行度,那么他会广播的将自己的水位线发送到下游的每个并行度。从上图中,process(2)并行度接收到4的数据,但是其watermark是5,这是因为map(1)和map(2)虽然奇数的数据不会发生给process(2),但是其水位线会广播发送给所有下游的process,因此process(2)会接收到5、7的水位线。
4)对于当前算子的上游有多个并行度,那么他会收到多个watermark,他的水位线会取最小的那个watermark。从上图中,可以看到process算子前面有一个分子分母的5/7,上面的5代表从map(2)得到的水位线,7代表从map(1)得到的水位线,两者取最小,因此process的水位线是5。
5)如果上游有一个并行度一直没有来数据,意味着当前算子的水位线会一直不变化,这样导致计算延迟过长。假设map(2)一直不来数据,而map(1)来了很多数据,这时候对于下游process来说,上游map(2)发给他的水位线永远停留在7,这就会导致process的水位线一直是7,可能触发不了计算。因此Flink提供设置空闲等待时间,如果某个上游的一个并行度一直没有来数据,超过该等待时间,会默认它无效,直接取已经到来的数据的最小watermark。
1.2 代码演示
示例说明:利用之前WatermarkBoundedOutOfOrdernessDemo修改一下并行度
WatermarkParallelismDemo 类:
import com.demo.lesson09.util.KeySelectorFunction;
import com.demo.lesson09.util.ServerInfo;
import com.demo.lesson09.util.ServerInfoMapFunction;
import org.apache.commons.lang3.time.DateFormatUtils;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.datastream.WindowedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import java.time.Duration;
import java.util.Iterator;
/**
* 演示多并行度的情况
*/
public class WatermarkParallelismDemo {
public static void main(String[] args) throws Exception {
// 1. 创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置2个并行度演示
env.setParallelism(2);
// 2. 读取数据
DataStreamSource<String> text = env.socketTextStream("127.0.0.1", 9999);
// 3. map做类型转换
SingleOutputStreamOperator<ServerInfo> map = text.map(new ServerInfoMapFunction());
// 4. 定义乱序watermark以及TimestampAssigner
WatermarkStrategy<ServerInfo> watermarkStrategy = WatermarkStrategy
// 设置乱序watermark,需要指定水位线延迟时间,设置2秒
.<ServerInfo>forBoundedOutOfOrderness(Duration.ofSeconds(2))
// 设置事件时间处理器
.withTimestampAssigner((element, recordTimestamp) ->{
System.out.println("event time = "+element.getTime()+ " 初始时间戳" + recordTimestamp);
return element.getTime() * 1000L;
})
// 空闲等待时间,如果上游多个并行度,有一个没有过来,超过10秒钟就废弃那个没过来的并行度watermark,直接取已经过来的最小值
// .withIdleness(Duration.ofSeconds(10))
;
SingleOutputStreamOperator<ServerInfo> mapWithWatermark = map.assignTimestampsAndWatermarks(watermarkStrategy);
// 5. 做keyBy
KeyedStream<ServerInfo, String> kyStream = mapWithWatermark.keyBy(new KeySelectorFunction());
// 6. 开窗 - 滚动窗口,必须是TumblingEventTimeWindows,5秒分割一个窗口
WindowedStream<ServerInfo, String, TimeWindow> windowStream = kyStream.window(TumblingEventTimeWindows.of(Duration.ofSeconds(5)));
// 7. 计算
SingleOutputStreamOperator<String> process = windowStream.process(new ProcessWindowFunction<ServerInfo, String, String, TimeWindow>() {
@Override
public void process(String s, ProcessWindowFunction<ServerInfo, String, String, TimeWindow>.Context context, Iterable<ServerInfo> elements, Collector<String> out) throws Exception {
// 打印窗口的开始时间和结束时间
System.out.println("process子任务id=" + getRuntimeContext().getTaskInfo().getIndexOfThisSubtask()+ "该窗口的时间:"+ DateFormatUtils.ISO_8601_EXTENDED_DATETIME_TIME_ZONE_FORMAT.format(context.window().getStart())
+ " - " +DateFormatUtils.ISO_8601_EXTENDED_DATETIME_TIME_ZONE_FORMAT.format(context.window().getEnd())
+" 的条数=" + elements.spliterator().estimateSize() + "水位线=" + context.currentWatermark());
// 平均cpu值
Iterator<ServerInfo> iterator = elements.iterator();
double cpu = 0l;
long num = 0;
while (iterator.hasNext()){
cpu = cpu + iterator.next().getCpu();
num ++;
}
String result = "平均cpu值: "+ (cpu/num);
out.collect(result);
}
});
// 8. 打印
process.print();
// 执行
env.execute();
}
}
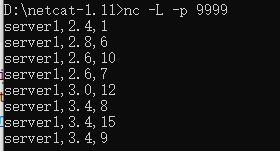
输入:先输入前3条数据,看看控制台,再输入第4条数据
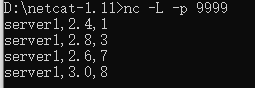
输出:

知识点:总共输入4条数据,process打印1次
1)当输入第3条数据时,process并没有打印,按照之前窗口5秒,水位线延迟时间为2秒,那么第3条数据7秒应该能够输出process,但是实际上并没有,这是因为多并行度原因。输入1、3、7分别轮询地被放到了map(0):1、7和map(1):3。因此process(0)接收到来自map(0)和map(1)的水位线分别是7和3,因此process(0)目前的水位线是3,并未触发process。
2)当输入第4条数据时,被分配到map(1),因此process(0)的watermark会被更新7(7和8选择小的那个)。那么7就能触发process
3)如果map(1)一直不来数据,那么意味着process(0)的watermark永远都是3,就一直不会触发process。这时候可以设置“空闲等待时间”:如果上游多个并行度,有一个没有过来,超过10秒钟就废弃那个没过来的并行度的watermark,直接取其它已经过来的watermark最小值。代码通过:.withIdleness(Duration.ofSeconds(10))设置。
2 水位线的策略
从上一章了解了数据流分为有序和乱序,对于有序数据流,按照事件时间(Event Time)划分窗口之类的都很容易,但是对于无序数据流来说,虽然也是按照事件时间(Event Time)划分窗口,但是由于数据是乱序,可能关闭了窗口之后,又来了一条本属于刚才关闭的窗口的数据,这样就会导致数据丢失。为了解决乱序问题,Flink提供了多种策略来弥补这方面的问题:
2.1 水位线延迟时间
水位线延迟时间:也叫事件时间戳乱序的边界,其实就是延迟水位线的时间。这个在前面乱序的demo中已经看到,设置forBoundedOutOfOrderness时,必须传入一个时间,这个时间就是水位线延迟时间。意味着数据只要在:窗口结束时间+水位线延迟时间 之前到来,还是可以被计算到窗口之内。
这个之前已经演示过了无序的代码,通过创建无序watermark时需要传入一个时间参数,该参数就是水位线延迟时间。
forBoundedOutOfOrderness(Duration.ofSeconds(2))
2.2 迟到时间
前面通过水位线延迟时间可以让水位线延迟一段时间,但是有时候数据确实来得比较晚,比你设置水位线延迟时间还晚时,数据还是会被遗弃,但是又不可以把水位线延迟时间设置过得无限长,因为一旦设置过长,会导致数据计算及时性,本来数据已经到了10秒钟该计算出结果了,但是水位线延迟时间设成2分钟,意味着数据要2分钟后才会被计算。因此为了保持计算的及时性,又不想漏掉数据,那么Flink还提供了另外一个设置:迟到时间
迟到时间:窗口的计算和窗口的关闭其实是两个动作,因此水位线延迟时间只是延迟了窗口的计算操作,这时候默认是到达水位线之后就会触发计算和关闭两个动作,但是通过增加一个迟到时间可以延迟窗口的关闭时间,也就是水位线到了,这时会计算一遍数据,但此时窗口并不会关闭,等待迟到时间到了再关闭,而在这段期间来的数据,依旧会被计算。这里列出2条公式让你理解这个概念:
- 统一计算操作 = 窗口时间 + 水位线延迟时间 - 1ms
- 关闭窗口操作 = 窗口时间 + 水位线延迟时间 + 迟到时间 - 1ms
下面通过demo来感受一下这2个设置的区别
示例说明:这里使用前面的WatermarkBoundedOutOfOrdernessDemo示例,修改增加一个allowedLateness(Duration.ofSeconds(3));迟到时间
WatermarkLatenessDemo类:
import com.demo.lesson09.util.KeySelectorFunction;
import com.demo.lesson09.util.ServerInfo;
import com.demo.lesson09.util.ServerInfoMapFunction;
import org.apache.commons.lang3.time.DateFormatUtils;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.datastream.WindowedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.operators.Output;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
import java.time.Duration;
import java.util.Iterator;
/**
* 演示迟到时间的情况
*/
public class WatermarkLatenessDemo {
public static void main(String[] args) throws Exception {
// 1. 创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);// 为了展现方便先设置为1,后续降到多并行度的watermark再开启多并行度
// 2. 读取数据
DataStreamSource<String> text = env.socketTextStream("127.0.0.1", 9999);
// 3. map做类型转换
SingleOutputStreamOperator<ServerInfo> map = text.map(new ServerInfoMapFunction());
// 4. 定义乱序watermark以及TimestampAssigner
WatermarkStrategy<ServerInfo> watermarkStrategy = WatermarkStrategy
// 设置乱序watermark,需要指定水位线延迟时间,设置2秒
.<ServerInfo>forBoundedOutOfOrderness(Duration.ofSeconds(2))
// 设置事件时间处理器
.withTimestampAssigner((element, recordTimestamp) ->{
System.out.println("event time = "+element.getTime()+ " 初始时间戳" + recordTimestamp);
return element.getTime() * 1000L;
})
;
SingleOutputStreamOperator<ServerInfo> mapWithWatermark = map.assignTimestampsAndWatermarks(watermarkStrategy);
// 5. 做keyBy
KeyedStream<ServerInfo, String> kyStream = mapWithWatermark.keyBy(new KeySelectorFunction());
// 6. 开窗 - 滚动窗口,必须是TumblingEventTimeWindows,10秒分割一个窗口
WindowedStream<ServerInfo, String, TimeWindow> windowStream = kyStream.window(TumblingEventTimeWindows.of(Duration.ofSeconds(10)));
SingleOutputStreamOperator<String> process = windowStream
// 7. 允许迟到时间
.allowedLateness(Duration.ofSeconds(3))
// 8. 计算
.process(new ProcessWindowFunction<ServerInfo, String, String, TimeWindow>() {
@Override
public void process(String s, ProcessWindowFunction<ServerInfo, String, String, TimeWindow>.Context context, Iterable<ServerInfo> elements, Collector<String> out) throws Exception {
// 打印窗口的开始时间和结束时间
System.out.println("process子任务id=" + getRuntimeContext().getTaskInfo().getIndexOfThisSubtask()+ "该窗口的时间:"+ DateFormatUtils.ISO_8601_EXTENDED_DATETIME_TIME_ZONE_FORMAT.format(context.window().getStart())
+ " - " +DateFormatUtils.ISO_8601_EXTENDED_DATETIME_TIME_ZONE_FORMAT.format(context.window().getEnd())
+" 的条数=" + elements.spliterator().estimateSize() + "水位线=" + context.currentWatermark());
// 平均cpu值
Iterator<ServerInfo> iterator = elements.iterator();
double cpu = 0l;
long num = 0;
while (iterator.hasNext()){
cpu = cpu + iterator.next().getCpu();
num ++;
}
String result = "平均cpu值: "+ (cpu/num);
out.collect(result);
}
});
// 9. 打印
process.print();
// 执行
env.execute();
}
}
输入:
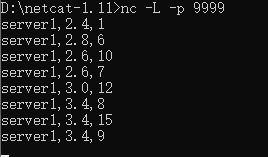
输出:
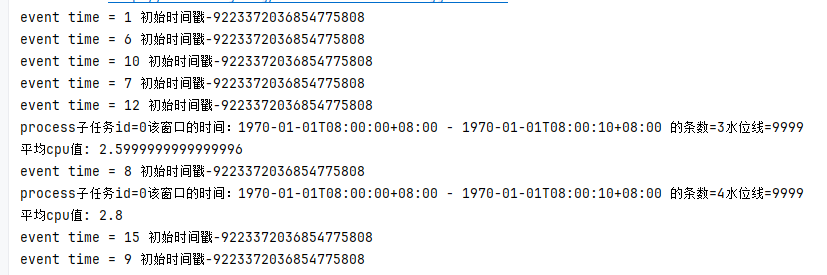
知识点:总共输入8条数据。窗口设置10秒,水位线延迟时间2秒,迟到时间3秒。process输出2次。
1)当输入到event time=10的数据时,process没有输出,这是因为示例中设置了水位线延迟时间2秒,因此需要到12秒的时候才输出
2)当输入到event time=12的数据时,process输出了,显示统计条数3条,就是前面的1、6、7三条数据
3)当输入到event time=8的数据时,process输出了,显示统计条数4条,就是前面的1、6、7、8四条数据。说明event time=8这条数据还是被窗口计算。也就说在迟到时间内来的数据都会调用一次process重新计算窗口的值
4)当输入到event time=15的数据时,此时窗口已经关闭,怎么验证呢?再次输入event time=9的数据,发现process并没有再次被调用,说明event time=9的数据被遗弃掉
2.3 侧输出流
上面演示了增加迟到时间的demo,但是还是可以看到最后一条event time=9的数据被遗弃掉。那只有设置迟到时间更长才能让event time=9的数据还能被计算,但是会有一个问题,就是在实际业务中,你根本不知道最晚的数据什么时候来,因此迟到时间只是一个预估,最终还是会有被遗弃的数据,况且如果迟到时间设置过长,会导致窗口一直不被关闭,占了大量内存空间也是给服务器造成很大压力,那么对于这些数据,是否还有其它处理方式?Flink提供了侧输出流的方式。侧输出流之前在《系列之十一 - Data Stream API的中间算子的底层原理及其自定义》讲process函数时讲过,这里就是利用侧输出流将被遗弃的数据放到侧输出流中,这样可以做线下处理。
示例说明:这里使用前面的WatermarkLatenessDemo 示例,修改增加一个sideOutputLateData(outputTag)侧输出流
WatermarkOutputTagDemo 类:
import com.demo.lesson09.util.KeySelectorFunction;
import com.demo.lesson09.util.ServerInfo;
import com.demo.lesson09.util.ServerInfoMapFunction;
import org.apache.commons.lang3.time.DateFormatUtils;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.datastream.WindowedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
import java.time.Duration;
import java.util.Iterator;
/**
* 演示侧输出流的情况
*/
public class WatermarkOutputTagDemo {
public static void main(String[] args) throws Exception {
// 1. 创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);// 为了展现方便先设置为1,后续降到多并行度的watermark再开启多并行度
// 2. 读取数据
DataStreamSource<String> text = env.socketTextStream("127.0.0.1", 9999);
// 3. map做类型转换
SingleOutputStreamOperator<ServerInfo> map = text.map(new ServerInfoMapFunction());
// 4. 定义乱序watermark以及TimestampAssigner
WatermarkStrategy<ServerInfo> watermarkStrategy = WatermarkStrategy
// 设置乱序watermark,需要指定水位线延迟时间,设置2秒
.<ServerInfo>forBoundedOutOfOrderness(Duration.ofSeconds(2))
// 设置事件时间处理器
.withTimestampAssigner((element, recordTimestamp) ->{
System.out.println("event time = "+element.getTime()+ " 初始时间戳" + recordTimestamp);
return element.getTime() * 1000L;
})
;
SingleOutputStreamOperator<ServerInfo> mapWithWatermark = map.assignTimestampsAndWatermarks(watermarkStrategy);
// 5. 做keyBy
KeyedStream<ServerInfo, String> kyStream = mapWithWatermark.keyBy(new KeySelectorFunction());
// 6. 开窗 - 滚动窗口,必须是TumblingEventTimeWindows,10秒分割一个窗口
WindowedStream<ServerInfo, String, TimeWindow> windowStream = kyStream.window(TumblingEventTimeWindows.of(Duration.ofSeconds(10)));
OutputTag<ServerInfo> outputTag = new OutputTag<>("outputTag", Types.POJO(ServerInfo.class)); // 侧输出流
// 8. 计算
SingleOutputStreamOperator<String> process = windowStream
// 7. 允许迟到时间
.allowedLateness(Duration.ofSeconds(3))
// 8. 侧输出流
.sideOutputLateData(outputTag)
// 9. 计算
.process(new ProcessWindowFunction<ServerInfo, String, String, TimeWindow>() {
@Override
public void process(String s, ProcessWindowFunction<ServerInfo, String, String, TimeWindow>.Context context, Iterable<ServerInfo> elements, Collector<String> out) throws Exception {
// 打印窗口的开始时间和结束时间
System.out.println("process子任务id=" + getRuntimeContext().getTaskInfo().getIndexOfThisSubtask()+ "该窗口的时间:"+ DateFormatUtils.ISO_8601_EXTENDED_DATETIME_TIME_ZONE_FORMAT.format(context.window().getStart())
+ " - " +DateFormatUtils.ISO_8601_EXTENDED_DATETIME_TIME_ZONE_FORMAT.format(context.window().getEnd())
+" 的条数=" + elements.spliterator().estimateSize() + "水位线=" + context.currentWatermark());
// 平均cpu值
Iterator<ServerInfo> iterator = elements.iterator();
double cpu = 0l;
long num = 0;
while (iterator.hasNext()){
cpu = cpu + iterator.next().getCpu();
num ++;
}
String result = "平均cpu值: "+ (cpu/num);
out.collect(result);
}
});
// 10. 打印
process.print();
// 11. 侧输出流打印
process.getSideOutput(outputTag).print("侧输出流:");
// 执行
env.execute();
}
}
输入:
输出:
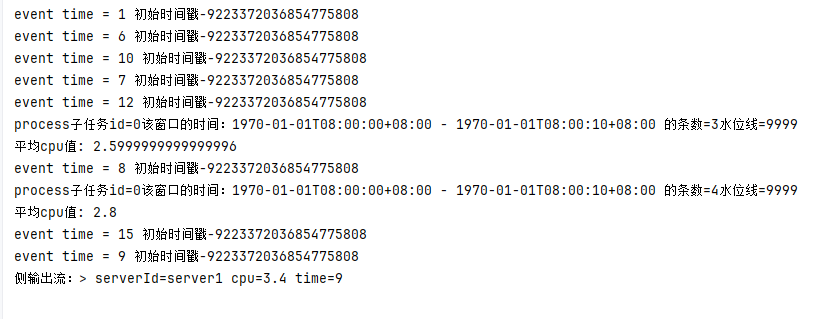
知识点:这个示例还是按照之前WatermarkLatenessDemo示例输入一样的数据,发现与WatermarkLatenessDemo 唯一不同的就是在最后有一个侧输出流,把event time=9的数据输出流。这样就可以针对该输出流做下线处理,保证数据准确性。
2.4 总结与实践
从上面3种策略,都是为了让Flink计算最终达到正确性,但这时候有人就会提出来为什么要设置3种策略,真实业务场景中如何设置这些策略的时间?下面给出一些总结和实践:
1)水位线延迟时间:这个数据决定第一次计算的时间,如果该时间变长的话,那么意味着你要得到的结果会有延迟;但如果设置过短可能导致数据计算不正确(漏掉一些数据)。所以这个时间在结果的时效性和正确性之间有矛盾。因此如果你希望计算结果时效性,那么一般都是设置很低的秒级和毫秒级,甚至为0。如果你希望能够保持一定的准确性,那么你应该涵盖大部分数据,可以设置你的数据大部分最晚延迟多久到而设置。
2)迟到时间:这个数据决定窗口关闭时间,也就是在它之后来的数据都会被遗弃。如果该时间变长的话,那么意味着你Flink需要保留很多窗口;但如果设置过短可能导致数据计算不正确(漏掉一些数据)。所以这个时间在性能上和准确性之间有矛盾。因此如果你希望计算结果准确性,那么也是尽量涵盖大部分正确数据,但是要有一定限制,不能过长,比如小时级别即可。如果你希望Flink的性能更好些,不想保留太多窗口,则将该时间设置短一点。
3)侧输出流:这是一个类似最终一致性的弥补方案,虽然Flink计算的结果可能存在不正确(漏掉一些数据),但是可以将漏掉的数据放到侧输出流,然后在侧输出流重新计算数据落盘,这样保证最终数据的正确性。
3 补充join和intervalJoin
在《系列之十 - Data Stream API的中间算子:合流和分流》中讲过2个流的合并,当时提到了join和intervalJoin方法也可以合并流。因为其涉及到窗口和水位线,当时没有细讲。因此在这里补充一下。
3.1 join
先回顾一下《系列之十 - Data Stream API的中间算子:合流和分流》中的模拟关联表示例,是将2个流分别是cpu流和内存流,如果服务器id和采集时间一致,就将它们合并在一起,但是操作很麻烦,还要自己管理缓存数据,而且还有一个问题,如果数据采集的时间并不是很精确的匹配,可能是5分钟采集一次,cpu的采集时间与内存的采集时间不可能百分之百一致,可能就在一个范围内一致。那么这时候就可以利用窗口和水位线的概念,将在一个窗口的数据合并在一起,这样就能达到一定范围内一致。而Flink的join就给提供了这种方便。
join从《官方文档》上来说,就是使用公共key,将将两个流的元素连接在一起,而这个连接必须是在同一个窗口内。如下图
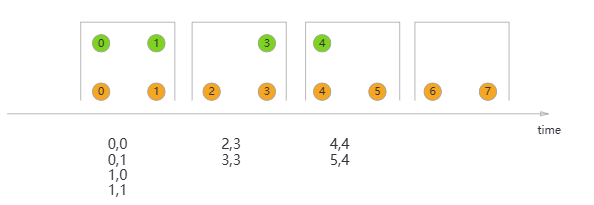
上图中,绿色和橙色两个数据流,它们在时间窗口一致的地方,进行数据合并。join提供apply方法自动将key和时间匹配的数据放到一起让用户可以进一步处理两个流匹配的数据。下面就利用原先connect的类似数据表的join操作示例给大家演示一下使用join如何实现
示例说明:现在有2个数据来源,一个是采集服务器的cpu,一个是采集服务器的内存和磁盘。希望最后输出在一个窗口内的cpu、内存和磁盘数据。窗口设置5秒钟,意味着两条流在同一个窗口内则属于一条数据。这次使用join方法来实现,你会发现容易很多。
JoinDemo 类
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.JoinFunction;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.api.java.tuple.Tuple4;
import org.apache.flink.api.java.tuple.Tuple5;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import java.time.Duration;
public class JoinDemo {
public static void main(String[] args) throws Exception {
// 1. 创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(2);
// 2. 读取数据--这里为了演示方便,就不监听端口,直接使用集合数据
KeyedStream<Tuple3<String, Double, Long>, String> server1Source = env.fromData(
new Tuple3<>("server1", 2.3, 1L), // 服务器id,cpu,时间
new Tuple3<>("server2", 45.3, 1L),
new Tuple3<>("server1", 32.1, 11L),
new Tuple3<>("server2", 23.8, 5L)
)
.assignTimestampsAndWatermarks(WatermarkStrategy
.<Tuple3<String, Double, Long>>forMonotonousTimestamps()
.withTimestampAssigner((element, recordTimestamp) ->{
System.out.println("event time = "+element.f2+ " 初始时间戳" + recordTimestamp);
return element.f2 * 1000L;
}))
.keyBy(value -> value.f0);
KeyedStream<Tuple4<String, Double, Double, Long>, String> server2Source = env.fromData(
new Tuple4<>("server1", 50.9, 70.3, 5L), // 服务器id,内存,磁盘,时间
new Tuple4<>("server2", 70.5, 48.9, 2L),
new Tuple4<>("server1", 55.9, 70.5, 14L),
new Tuple4<>("server2", 65.5, 49.5, 8L))
.assignTimestampsAndWatermarks(WatermarkStrategy
.<Tuple4<String, Double, Double, Long>>forMonotonousTimestamps()
.withTimestampAssigner((element, recordTimestamp) ->{
System.out.println("event time = "+element.f3+ " 初始时间戳" + recordTimestamp);
return element.f3 * 1000L;
}))
.keyBy(value -> value.f0);
// 3. 通过join合并流
DataStream<Tuple5<String, Double, Double, Double, Long>> apply = server1Source.join(server2Source)
// cpu数据量的key 等于 内存数据流的key
.where(value -> value.f0)
.equalTo(value -> value.f0)
// 开窗,使用滚动窗口,5s
.window(TumblingEventTimeWindows.of(Duration.ofSeconds(5)))
// apply当数据匹配上(窗口一直,且key一致的数据会到apply方法中)
.apply(new JoinFunction<>() {
@Override
public Tuple5<String, Double, Double, Double, Long> join(Tuple3<String, Double, Long> first, Tuple4<String, Double, Double, Long> second) throws Exception {
System.out.println("first=" + first + " -> second=" + second);
return new Tuple5<>(first.f0, first.f1, second.f1, second.f2, first.f2);
}
});
// 4. 输出
apply.print();
// 执行
env.execute();
}
}
输出:
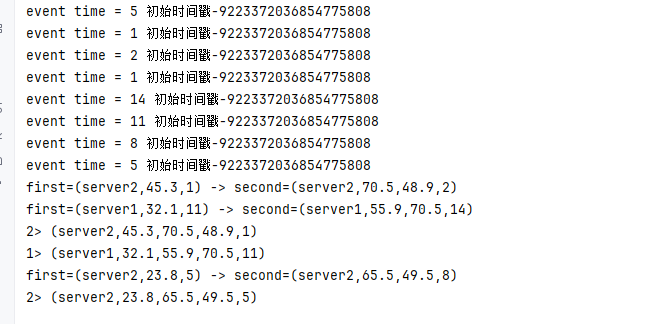
知识点:从控制台可以看到cpu流的server1的11L时刻匹配到了内存流的server1的14L,但是cpu流的server1的1L时刻并没有匹配到,因为0-5秒窗口,内存流并没有数据;同样的内存流的server1的14L时刻也没有匹配到数据。而server2的都各自找到匹配。
这段代码比之前使用connect实现的方式简便很多,且用户不需要管理中间值,Flink自动将匹配数据放到apply方法让用户处理。
3.2 intervalJoin
前面了解了join方法,但是还是有一个问题,就是有时候用户希望匹配不是按照固定的窗口,而是动态的窗口,比如会话窗口就不是固定的,那么使用join就无法实现,同时如果数据是迟到的,可能也会丢失。这时候Flink提供了intervalJoin方法。
参考《官方文档》中的图来说明一下
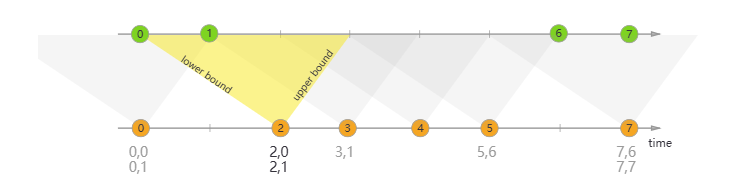
上图中,两条线代表两条数据流,上面的圆圈代表数据,圆圈里面的数字代表事件时间event time。intervalJoin提供一个时间范围的匹配,比如上图中下面那条线的2数据,设置了上界1和下界-2,那么意味着它能匹配到0-3之间的数据,这样通过控制上界和下界,就能够灵活控制匹配的时间访问,同时intervalJoin还提供了侧输出流对关闭窗口之后的数据进行处理。
注意:下面的示例,还实现了ProcessJoinFunction方法,这个是《系列之十一 - Data Stream API的中间算子的底层原理及其自定义》中讲到自定义Process函数,有8大类,当时说有些Process函数后续遇到再讲,这里就涉及其中的ProcessJoinFunction类。加上《系列之十五 - Data Stream API的高级概念 - 窗口》中讲到了ProcessWindowFunction和ProcessAllWindowFunction,到这里已经讲了6类底层的Process函数,这里让你顺便回忆一下。
示例说明:假设有2个数据来源,一个是采集服务器的cpu,一个是采集服务器的内存和磁盘。希望最后输出在一个窗口内的cpu、内存和磁盘数据。窗口5秒钟内属于一条数据。这次使用intervalJoin方法来实现,不仅演示如何使用intervalJoin,同时还演示关闭窗口之后的数据从侧输出流。
IntervalJoinDemo 类:
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.api.java.tuple.Tuple4;
import org.apache.flink.api.java.tuple.Tuple5;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.ProcessJoinFunction;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
import java.time.Duration;
public class IntervalJoinDemo {
public static void main(String[] args) throws Exception {
// 1. 创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 2. 读取数据--这里为了演示方便,就不监听端口,直接使用集合数据
KeyedStream<Tuple3<String, Double, Long>, String> server1Source = env
.socketTextStream("localhost", 8888)
.map(new Tuple3MapFunction())
.assignTimestampsAndWatermarks(WatermarkStrategy
.<Tuple3<String, Double, Long>>forMonotonousTimestamps()
.withTimestampAssigner((element, recordTimestamp) ->{
System.out.println("event time = "+element.f2+ " 初始时间戳" + recordTimestamp);
return element.f2 * 1000L;
}))
.keyBy(value -> value.f0);
KeyedStream<Tuple4<String, Double, Double, Long>, String> server2Source = env
.socketTextStream("localhost", 9999)
.map(new Tuple4MapFunction())
.assignTimestampsAndWatermarks(WatermarkStrategy
.<Tuple4<String, Double, Double, Long>>forMonotonousTimestamps()
.withTimestampAssigner((element, recordTimestamp) ->{
System.out.println("event time = "+element.f3+ " 初始时间戳" + recordTimestamp);
return element.f3 * 1000L;
}))
.keyBy(value -> value.f0);
OutputTag<Tuple3<String,Double,Long>> leftOutputTag = new OutputTag<>("leftOutputTag", Types.TUPLE(Types.STRING,Types.DOUBLE,Types.LONG)); // cpu流关闭窗口之后的数据
OutputTag<Tuple4<String,Double,Double,Long>> rightOutputTag = new OutputTag<>("rightOutputTag", Types.TUPLE(Types.STRING,Types.DOUBLE,Types.DOUBLE,Types.LONG)); // 内存流关闭窗口之后的数据
// 3. 通过join合并流
SingleOutputStreamOperator<Tuple5<String, Double, Double, Double, Long>> process = server1Source.intervalJoin(server2Source)
// 设置intervalJoin的上下界,分别是-2和2,意味着如果事件时间为3,则可以匹配到1-5的数据
.between(Duration.ofSeconds(-2), Duration.ofSeconds(2))
// 设置左流-cpu流关闭窗口之后的数据
.sideOutputLeftLateData(leftOutputTag)
// 设置右流-内存流关闭窗口之后的数据
.sideOutputRightLateData(rightOutputTag)
// 当两条流数据匹配了,且窗口还未关闭时,会调用process方法
.process(new ProcessJoinFunction<>() {
@Override
public void processElement(
Tuple3<String, Double, Long> left,
Tuple4<String, Double, Double, Long> right,
ProcessJoinFunction<Tuple3<String, Double, Long>, Tuple4<String, Double, Double, Long>, Tuple5<String, Double, Double, Double, Long>>.Context ctx,
Collector<Tuple5<String, Double, Double, Double, Long>> out) throws Exception {
System.out.println("left=" + left + " -> right=" + right);
out.collect(new Tuple5<>(left.f0, left.f1, right.f1, right.f2, left.f2));
}
});
// 4. 输出
process.print("主流");
process.getSideOutput(leftOutputTag).print("左流关闭窗口之后的数据:");
process.getSideOutput(rightOutputTag).print("右流关闭窗口之后的数据:");
// 执行
env.execute();
}
public static class Tuple3MapFunction implements MapFunction<String, Tuple3<String,Double,Long>> {
@Override
public Tuple3<String, Double, Long> map(String value) throws Exception {
String[] values = value.split(",");
String value1 = values[0];
double value2 = Double.parseDouble("0");
long value3 = 0;
if(values.length >= 2){
try {
value2 = Double.parseDouble(values[1]);
}catch (Exception e){
value2 = Double.parseDouble("0");
}
}
if(values.length >= 3){
try {
value3 = Long.parseLong(values[2]);
}catch (Exception ignored){
}
}
return new Tuple3<>(value1,value2,value3);
}
}
public static class Tuple4MapFunction implements MapFunction<String, Tuple4<String,Double,Double,Long>> {
@Override
public Tuple4<String,Double,Double,Long> map(String value) throws Exception {
String[] values = value.split(",");
String value1 = values[0];
double value2 = Double.parseDouble("0");
double value3 = Double.parseDouble("0");
long value4 = 0;
if(values.length >= 2){
try {
value2 = Double.parseDouble(values[1]);
}catch (Exception e){
value2 = Double.parseDouble("0");
}
}
if(values.length >= 2){
try {
value3 = Double.parseDouble(values[2]);
}catch (Exception e){
value3 = Double.parseDouble("0");
}
}
if(values.length >= 3){
try {
value4 = Long.parseLong(values[3]);
}catch (Exception ignored){
}
}
return new Tuple4<>(value1,value2,value3,value4);
}
}
}
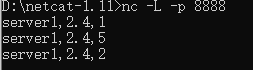
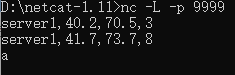
输入:这里输入需要按照一定顺序,先在8888端口输入第1条数据,再从9999端口输入第1条数据;在8888端口输入第2条数据,再从9999端口输入第2条数据;在8888端口输入第3条数据。
输出:

知识点:
1)在8888端口输入第1条数据(server1,2.4,1)时,事件时间=1的上下界为-2和2,则会匹配-1~3的数据,但是9999端口的流还没数据,因此不会调用process方法
2)在9999端口输入第1条数据(server1,40.2,70.5,3)时,它与8888端口的第1条数据匹配,因为事件时间=1的上下界为-2和2,则会匹配-1~3的数据
3)在8888端口输入第2条数据(server1,2.4,5)时,会与9999端口的第1条数据匹配,因为事件时间=5的上下界为-2和2,则会匹配3~7的数据
4)在9999端口输入第2条数据(server1,41.7,73.7,8)时,它与8888端口的数据都不匹配,因为事件时间=8的上下界为-2和2,则会匹配6~10的数据
5)在8888端口输入第3条数据(server1,2.4,2)时,虽然事件时间=2的上下界为-2和2,则会匹配0~4的数据,但是由于窗口已经关闭,因此被侧输出流捕获。
结语:本章对水位线的传递和策略做了详细的讲解,相信通过本章学习,对水位线有了更深的了解。了解水位线对业务处理有很关键的作用。下一章,将继续讲解Data Stream API的高级概念-定时器。



















 1267
1267

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











