







 本文详细介绍了神经网络的基本组成部分,包括输入层、输出层和隐藏层,以及各种激活函数如sigmoid、tanh、ReLU和SoftMax的特点、适用场景和局限性。此外,还探讨了参数初始化的方法,如均匀分布、正态分布和Kaiming、Xavier初始化。最后概述了神经网络的优点和缺点,以及在PyTorch中的实现和训练要点。
本文详细介绍了神经网络的基本组成部分,包括输入层、输出层和隐藏层,以及各种激活函数如sigmoid、tanh、ReLU和SoftMax的特点、适用场景和局限性。此外,还探讨了参数初始化的方法,如均匀分布、正态分布和Kaiming、Xavier初始化。最后概述了神经网络的优点和缺点,以及在PyTorch中的实现和训练要点。
一、神经网络
1、神经网络
人工神经网络(Artificial Neural Network,即ANN)也简称为神经网络(NN)是一种模仿生物神经网络结构 和功能的计算模型。
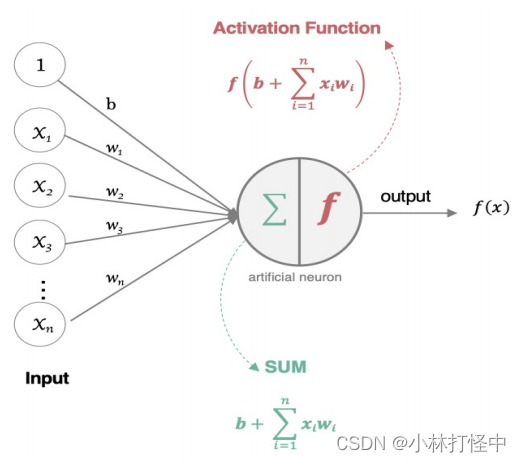
2、基本部分
输入层:输入 x
输出层:输出 y
隐藏层:输入与输出之间所有层
3、特点
同一层的神经元之间没有连接
第 N 层的每个神经元和第 N-1层 的所有神经元相连(full connected),即全连接神经网络
第 N-1层神经元的输出就是第 N 层神经元的输入
每个连接都有一个权重值(w系数和b系数)
二、激活函数
用于对每层的输出数据进行变换,进而为整个网络注入了非线性因素。此时, 神经网络就可以拟合各种曲线
1、sigmoid 激活函数
公式:

求导公式:
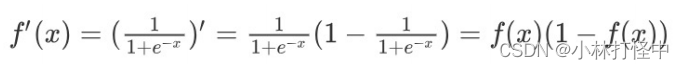
绘制函数图像:
import torch
import matplotlib.pyplot as plt
# 函数图像
x = torch.linspace(-20,20,1000)
# 输入值x 通过 sigmoid函数 转换成 激活值y
y = torch.sigmoid(x)
# 创建画布、坐标轴
plt.plot(x,y)
plt.grid()
plt.show()
# 导数图像
x = torch.linspace(-20,20,1000,requires_grad=True)
# 自动微分
torch.sigmoid(x).sum().backward()
plt.plot(x.detach(),x.grad)
plt.grid()
plt.show()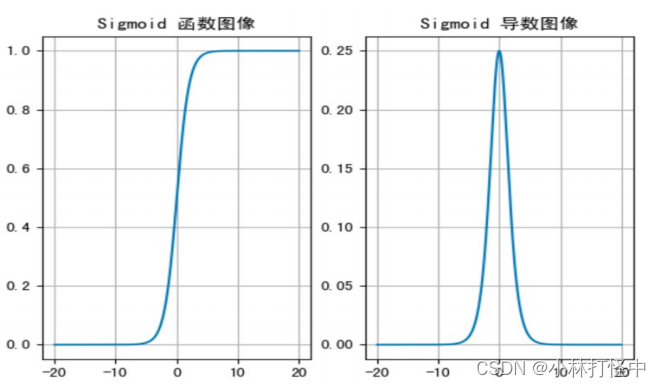
sigmoid 函数可以将任意的输入映射到 (0, 1) 之间,当输入的值大致在 <-6 或者 >6 时,意味着输入任何值 得到的激活值都是差不多的,这样会丢失部分信息。比如:输入 100 和输出 10000 经过 sigmoid 的激活值几乎都是等于 1 的,但是输入的数据之间相差 100 倍的信息就丢失了。
对于 sigmoid 函数而言,输入值在 [-6, 6] 之间输出值才会
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1232
1232

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









