







训练均方误差与测试均方误差:


导数的解释:https://baijiahao.baidu.com/s?id=1617937787808596810&wfr=spider&for=pc
偏差与方差的学习: https://www.jianshu.com/p/6ede9d45e443
Bias(偏差)
模型在样本上的输出与真实值之间的误差,即模型本身的精准度,反应出算法的拟合能力。
Variance(方差)
模型每一次输出结果与模型输出期望之间的误差,即模型的稳定性,反应出预测的波动情况。
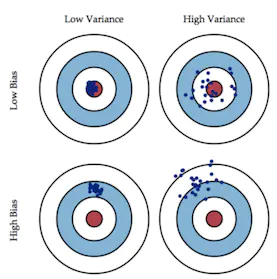
假设你的算法在开发集上有16%的错误率(84%的精度),我们将16%的错误率分为两部分:
1. 偏差:算法在训练集上面的错误率。假设有15%。
2.方差:算法在测试集上的错误率比训练集上差多少。16%-15%=1%
总误差 = 偏差+方差 所以总误差为15%+1%=16%.
减少方差的技术:
1.添加更多的训练数据。
2.加入正则化。
3.加入提前终止。
4.通过特征选择减少输入特征的数量和种类。
5.减小模型规模。
避免欠拟合(拟合太差)
1、增加训练样本数据
2、设计更复杂的神经网络模型
3、增加迭代次数
4、更好的优化函数
5、调整超参数值
避免过拟合(拟合过度,泛化太差)
1、设计更简单的神经网络模型
2、增加训练样本数据
3、正则化。在损失函数后面添加上L2正则项
4、使用dropout。随机性使得网络中的部分神经元失效,效果上类似将模型变得更简单。
5、调整超参数值
6、尝试其他模型
7、提前结束训练(early stopping)。即是提前结束优化损失函数。
简单小结
在实际工程中,通常可以按下面的来操作
贝叶斯(最优)误差-理论上的最小误差值(通常比人类误差小)
可避免偏差-训练误差 与 贝叶斯误差 之间的差值
方差-验证集误差 与 训练误差 的差值
当 可避免偏差 大于 方差 时,发生 欠拟合。
当 方差 大于 可避免偏差 时,发生 过拟合。
在训练模型时对照以上描述,有助于定位问题,更快找到最适合的模型。
一般而言,增加模型的复杂度,会增加模型的方差,但是会减少模型的偏差,我们要找到一个方差--偏差的权衡,使得均方误差最。
特征提取:
在前面的讨论中,我们已经明确一个目标,就是:我们要选择一个测试误差达到最小的模型。但是实际上我们很难对实际的测试误差做精确的计算,因此我们要对测试误差进行估计,估计的方式有两种:训练误差修正与交叉验证。
训练误差修正:
前面的讨论我们已经知道,模型越复杂,训练误差越小,测试误差先减后增。因此,我们先构造一个特征较多的模型使其过拟合,此时训练误差很小而测试误差很大,那这时我们加入关于特征个数的惩罚。因此,当我们的训练误差随着特征个数的增加而减少时,惩罚项因为特征数量的增加而增大,抑制了训练误差随着特征个数的增加而无休止地减小。
交叉验证:
前面讨论的对训练误差修正得到测试误差的估计是间接方法,这种方法的桥梁是训练误差,而交叉验证则是对测试误差的直接估计。交叉验证比训练误差修正的优势在于:能够给出测试误差的一个直接估计。在这里只介绍K折交叉验证:我们把训练样本分成K等分,然后用K-1个样本集当做训练集,剩下的一份样本集为验证集去估计由K-1个样本集得到的模型的精度,这个过程重复K次取平均值得到测试误差的一个估计。
正则化L1、L2区别?
(吴恩达— 正则化https://blog.csdn.net/qq_37717661/article/details/81149108
https://www.cnblogs.com/skyfsm/p/8456968.html)
在机器学习中,我们非常关心模型的预测能力,即模型在新数据上的表现,而不希望过拟合现象的的发生,我们通常使用正则化(regularization)技术来防止过拟合情况。


L2是平方之和,L1是参数绝对值之和
相同点:都用于避免过拟合
不同点:L1可以让一部分特征的系数缩小到0,从而间接实现特征选择。所以L1适用于特征之间有关联的情况。
L2让所有特征的系数都缩小,但是不会减为0,它会使优化求解稳定快速。所以L2适用于特征之间没有关联的情况
L1和L2的优点可以结合起来,这就是Elastic Net
对于稀疏性的解释:L1求导为一个常数,L2求导为一次参数W,0附近时,L1导数比L2大,经过多次梯度下降,L1参数W可以取0值,L2参数W只会趋近于0。
从数学求导的角度看:

从几何空间的角度看:

高维我们无法想象,简化到2维的情形,如上图所示。其中,左边是L1图示,右边是L2图示,左边的方形线上是L1中w1/w2取值区间,右边得圆形线上是L2中w1/w2的取值区间,绿色的圆圈表示w1/w2取不同值时整个正则化项的值的等高线(凸函数),从等高线和w1/w2取值区间的交点可以看到,L1中两个权值倾向于一个较大另一个为0,L2中两个权值倾向于均为非零的较小数。这也就是L1稀疏,L2平滑的效果。















 2035
2035











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









