







最近工作的原因需要学习 kubernetes,公司虽然部署有 kubernetes 的环境,但毕竟没权限随便折腾,所以就打算在自己电脑上搭建一套环境。在搭建的过程中还是遇到了不少的坑,在这里记录下来作为备忘。
虚拟机创建
首先我搭建 kubernetes 的主要目的是想测试其网络和调度能力,所以准备至少搭建双节点的集群才方便后续验证各类情况。刚好我有一台32线程64G内存的 Ubuntu22.04 系统的主机,加之 Linux 内核的 KVM 模块对虚拟化的支持非常到位,所以就打算以这台主机为基础,在它上面开通两台虚拟机,作为本次 kubernetes 的集群环境。目标结果如下:
| 操作系统 | IP | kubernetes角色 | |
|---|---|---|---|
| 宿主机 | Ubuntu22.04 | 192.168.31.182 | |
| 虚拟机1 | Ubuntu22.04 | 192.168.31.29 | Master |
| 虚拟机2 | Ubuntu22.04 | 192.168.31.182 | Worker |
下面是通过 KVM 开通虚机的流程,如果你打算使用 VMWare 或 VirtualBox 等软件开通虚机,也没有问题,可以跳过这部分直接进入下一环节。
安装 virt-manager
virt-manager 是用于管理 KVM 虚机的 GUI 工具,对初学者比较友好,这节我们先安装这个工具。
首先常规操作,更新 Ubuntu22.04 的软件包:
$ sudo apt update
$ sudo apt upgrade
KVM 需要 CPU 支持相关的指令集才能使用,这里检查一下你的 CPU 硬件是否支持:
$ egrep -c '(vmx|svm)' /proc/cpuinfo
如果值大于0,说明 KVM 模块是可用的,如果等于0,就需要去 BIOS 里检查 CPU 有没有开启对 IntelVT 或 AMD-V 等虚拟化能力的支持(一般的 CPU 型号都会支持,并且默认开启)。
如果上述检查没问题,就可以安装 virt-manager 及相关依赖:
$ sudo apt install qemu-kvm libvirt-daemon-system libvirt-clients bridge-utils virt-manager
virt-manager 是 libvirtd 的 GUI 工具,它会调用 libvirtd 的服务来进行虚拟机的管理,所以在上述安装步骤结束后,我们需要查看 libvirtd 的服务有没有正常启动:
$ systemctl status libvirtd
如果 libvirtd 服务状态不正常,可以尝试重启:
$ systemctl restart libvirtd
好,现在创建虚机需要的工具准备好了,我们再来准备下网络。
创建桥接网络
这里我打算使用桥接网络来创建我的虚机,所以我需要先在宿主机创建网桥。我的宿主机一开始的网络非常简单,除了lo环回网卡外,只有一块物理网卡enp6s0。如下:
$ ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: enp6s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 22:50:5c:01:00:13 brd ff:ff:ff:ff:ff:ff
inet 192.168.31.182/24 brd 192.168.31.255 scope global dynamic noprefixroute enp6s0
valid_lft 43153sec preferred_lft 43153sec
inet6 fe80::6325:e6a:8c14:8b90/64 scope link noprefixroute
valid_lft forever preferred_lft forever
同时也可以看下现在的路由表:
$ route -n
目标 网关 子网掩码 标志 跃点 引用 使用 接口
0.0.0.0 192.168.31.1 0.0.0.0 UG 100 0 0 enp6s0
169.254.0.0 0.0.0.0 255.255.0.0 U 1000 0 0 enp6s0
192.168.31.0 0.0.0.0 255.255.255.0 U 100 0 0 enp6s0
修改宿主机网络,创建网桥br0,并且将物理网卡enp6s0插入网桥(后续虚拟机的网卡也会插入br0网桥),这里注意将物理网卡名enp6s0、IP地址192.168.31.182/24和网关地址192.168.31.1修改为自己的信息:
$ cat /etc/netplan/01-network-manager-all.yaml
network:
version: 2
renderer: NetworkManager
ethernets:
enp6s0:
dhcp4: no
bridges:
br0:
addresses: [192.168.31.182/24]
dhcp4: false
interfaces:
- enp6s0
routes:
- to: default
via: 192.168.31.1
nameservers:
addresses: [8.8.8.8,114.114.114.114]
更新网络状态,使配置生效:
$ netplan apply
修改生效后,可以再次查看下修改后的网络,新增了 br0 网桥,并且 IP 已经从物理网卡 enp6s0 转移到 br0 上:
$ ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: enp6s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel master br0 state UP group default qlen 1000
link/ether 22:50:5c:01:00:13 brd ff:ff:ff:ff:ff:ff
7: br0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default qlen 1000
link/ether 5a:c2:c6:e1:07:0c brd ff:ff:ff:ff:ff:ff
inet 192.168.31.182/24 brd 192.168.31.255 scope global noprefixroute br0
valid_lft forever preferred_lft forever
对应的路由表也略有变化,默认网关调整为 br0:
route -n
目标 网关 子网掩码 标志 跃点 引用 使用 接口
0.0.0.0 192.168.31.1 0.0.0.0 UG 20425 0 0 br0
169.254.0.0 0.0.0.0 255.255.0.0 U 1000 0 0 enp6s0
192.168.31.0 0.0.0.0 255.255.255.0 U 425 0 0 br0
后续虚拟机也会配置为桥接网络,虚拟网卡(如下的vnet0和vnet1)也会插入br0,虚机启动后的网络如下所示(现在没有,后面虚机启动后可以观察下):
$ ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: enp6s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel master br0 state UP group default qlen 1000
link/ether 22:50:5c:01:00:13 brd ff:ff:ff:ff:ff:ff
3: virbr0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default qlen 1000
link/ether 52:54:00:76:e8:9b brd ff:ff:ff:ff:ff:ff
inet 192.168.122.1/24 brd 192.168.122.255 scope global virbr0
valid_lft forever preferred_lft forever
4: br0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 5a:c2:c6:e1:07:0c brd ff:ff:ff:ff:ff:ff
inet 192.168.31.182/24 brd 192.168.31.255 scope global noprefixroute br0
valid_lft forever preferred_lft forever
inet6 fe80::58c2:c6ff:fee1:70c/64 scope link
valid_lft forever preferred_lft forever
5: vnet0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master br0 state UNKNOWN group default qlen 1000
link/ether fe:54:00:7d:ff:1c brd ff:ff:ff:ff:ff:ff
inet6 fe80::fc54:ff:fe7d:ff1c/64 scope link
valid_lft forever preferred_lft forever
6: vnet1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master br0 state UNKNOWN group default qlen 1000
link/ether fe:54:00:2e:e3:bb brd ff:ff:ff:ff:ff:ff
inet6 fe80::fc54:ff:fe2e:e3bb/64 scope link
valid_lft forever preferred_lft forever
虚拟机开通
首先启动 virt-manager:
$ virt-manager
点击新建虚机:
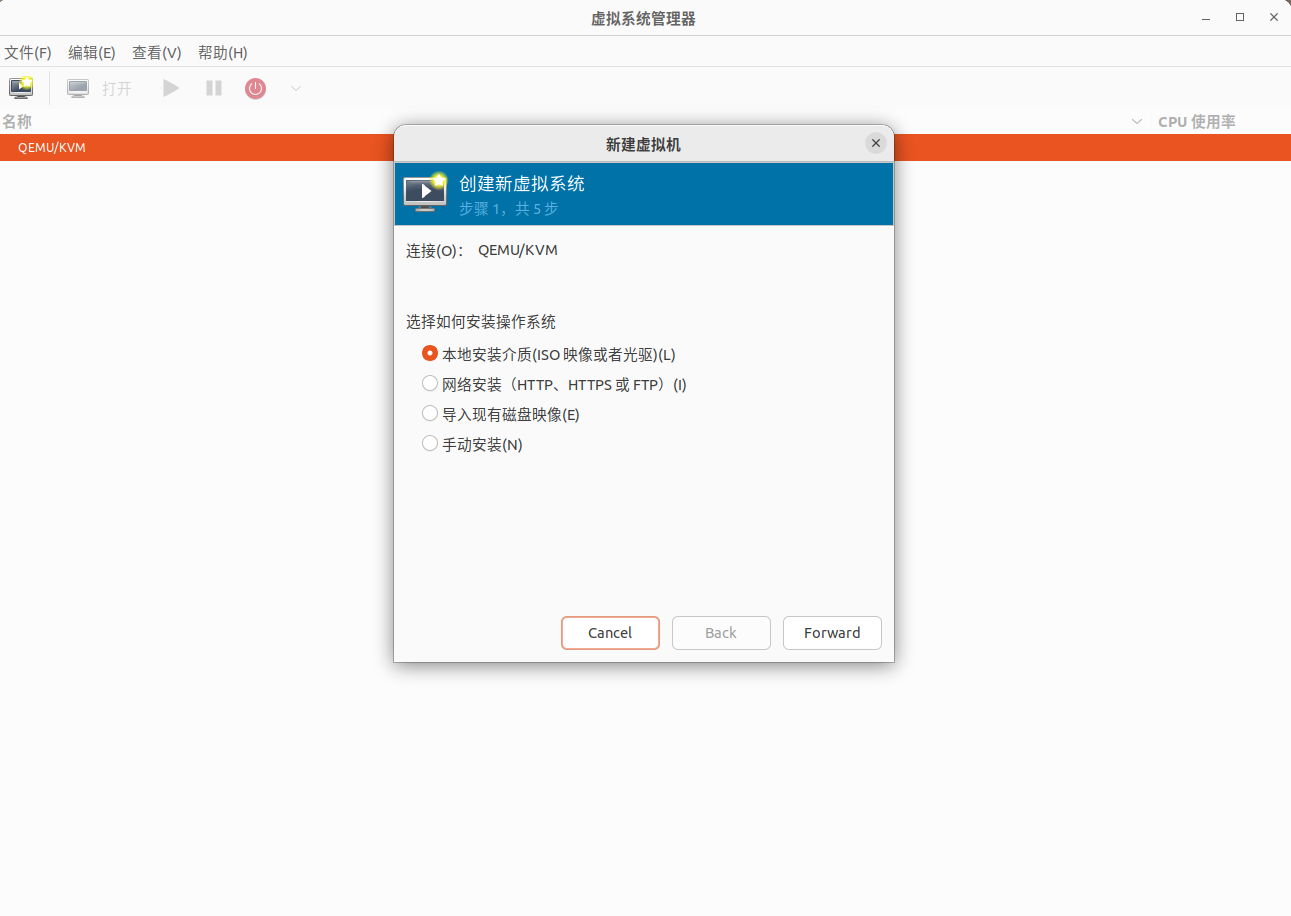
我们虚拟机使用 ubuntu22.04 ,镜像从官网下载即可:
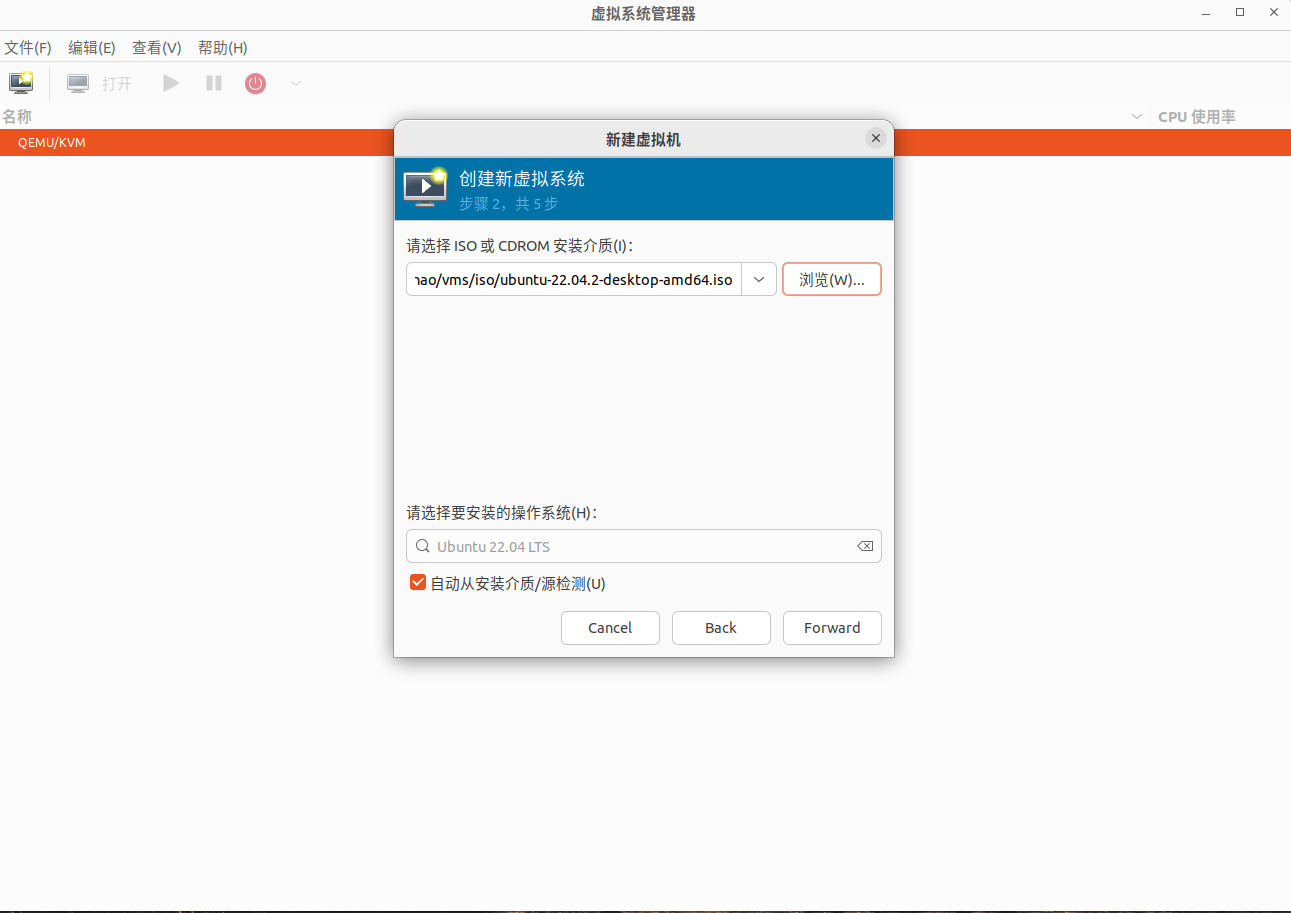
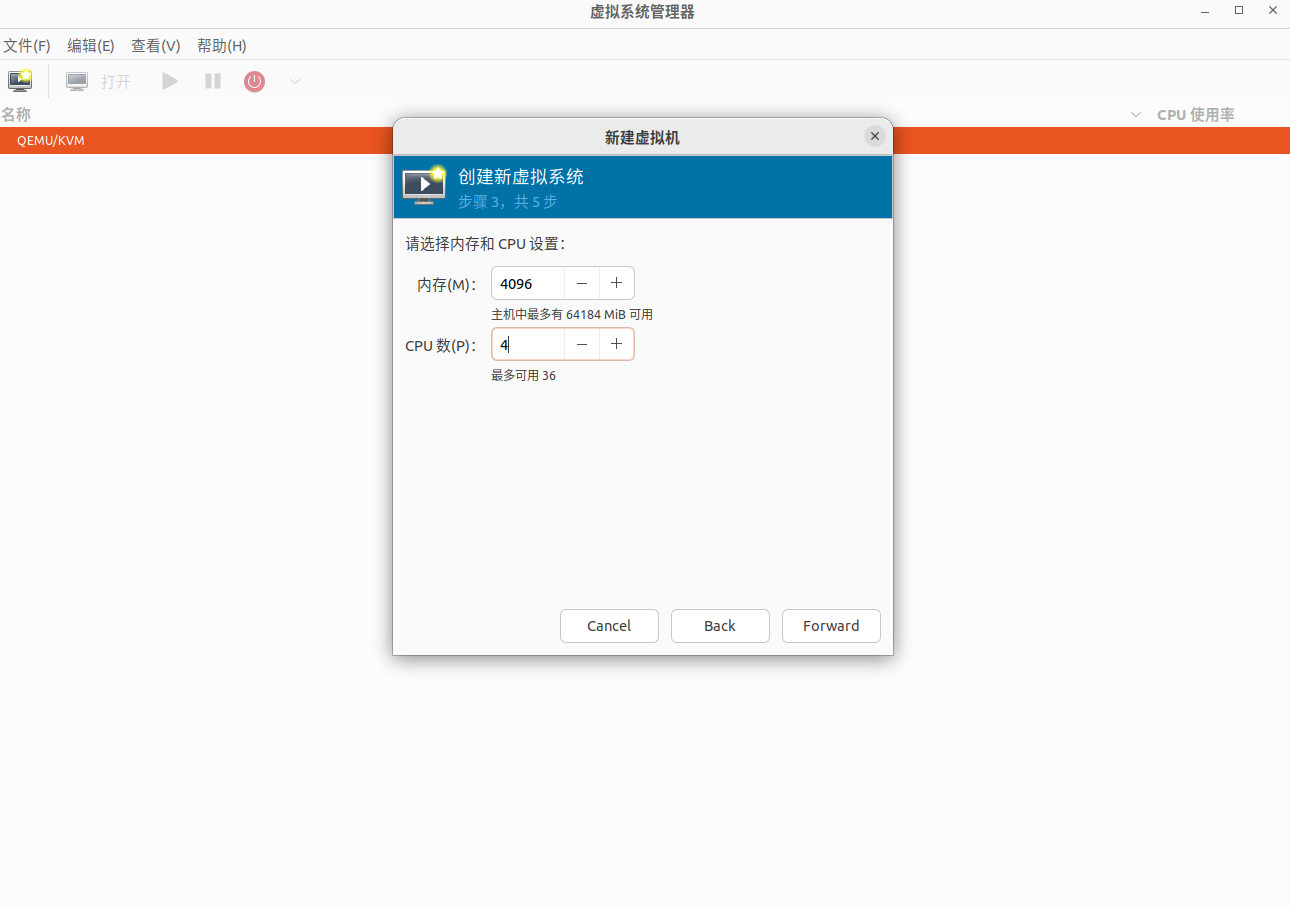
选择 CPU 和内存设置,这里我配的是 4C4G,大家可以根据自己宿主机的情况而定:
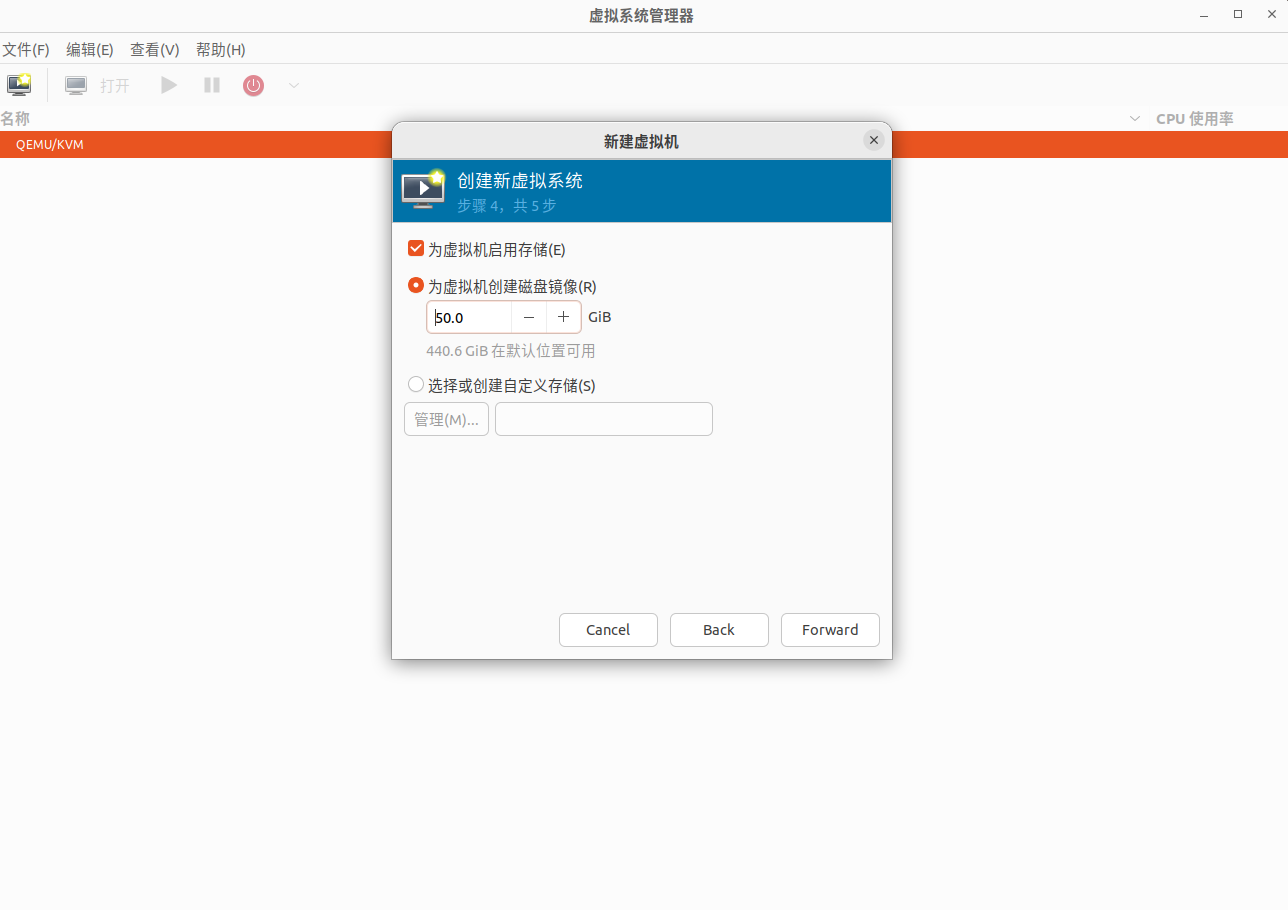
选择磁盘大小,我这里配置的 50G ,因为我主要验证网络功能,所以对磁盘没有太多要求:
这里比较关键的是网络设置,要选择桥接网络,填写我们上一节创建的 br0 网桥。另外需要勾选在安装前自定义配置:
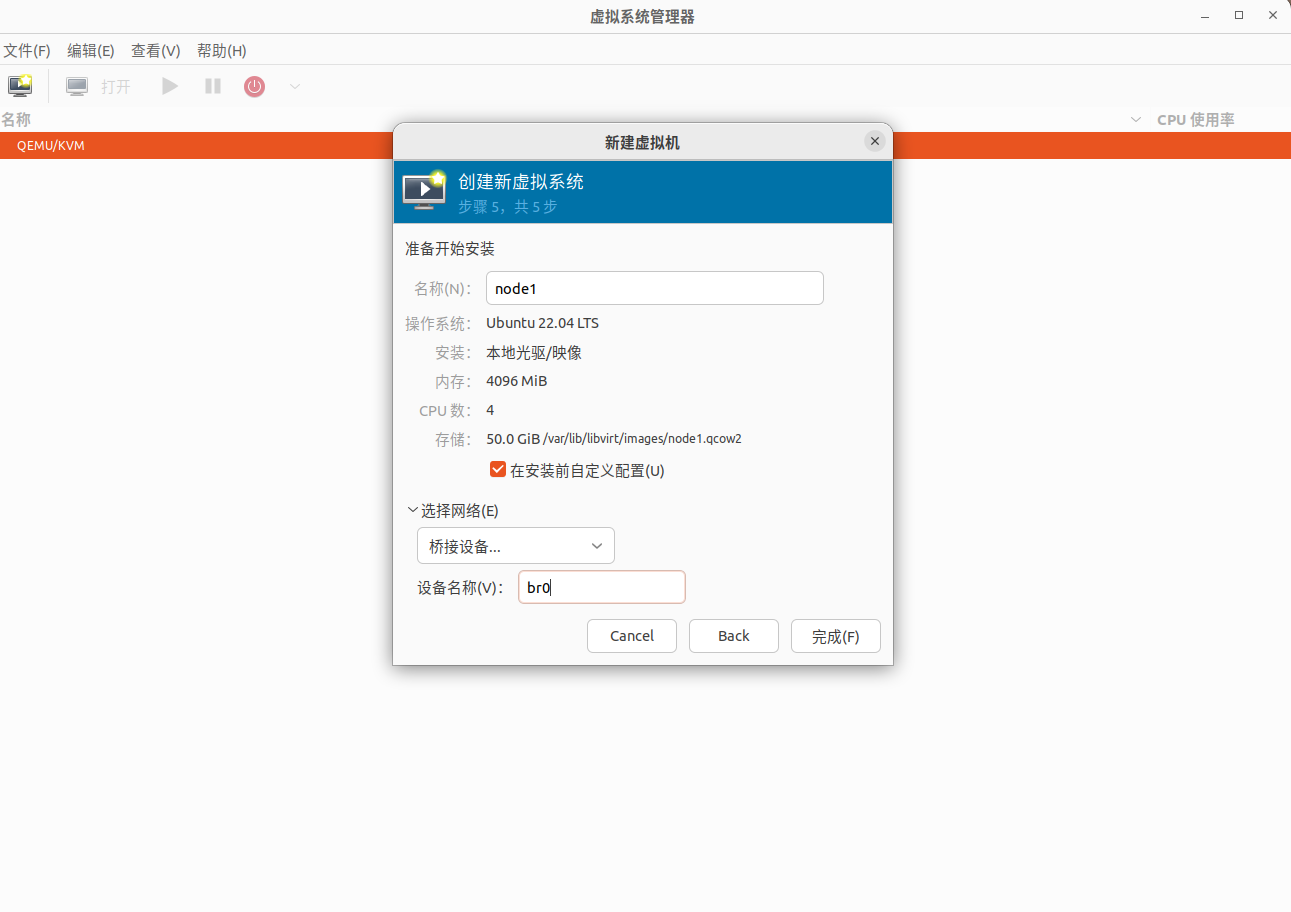
勾选在安装前自定义配置后会进入这个配置页,这里将引导选项的SATA CDROM 1勾选上并移到第一位,表明优先从CDROM引导启动,也就是我们之前选择的 ubuntu22.04 镜像:
上面配置完成后点击安装即可,之后就会进入 Ubuntu 的标准安装流程,大家按照提示安装即可。
我们需要两台 Ubuntu 虚拟机来完成 kubernetes 环境搭建,所以上述的虚拟机开通动作要执行两次。
虚拟机开通成功后,我们可以通过 virt-manager 的 VNC 直接进入到虚拟机内部,然后通过 ip a 命令,观察虚拟机分配的 IP 是否符合预期,正常为虚拟机分配的 IP 应该是跟你的物理网络网段保持一致。比如在我的场景下,两台虚拟机的 IP 分别是 192.168.31.29 和 192.168.31.68。
虚拟机环境配置
为了搭建 kubernetes 集群,我们需要对虚拟机进行一些初始的配置,两台虚机都要执行如下操作。
关闭 swap 分区
首先通过swapoff -a来禁用交换分区。
另外我们需要永久关闭 swap ,避免虚拟机重启后 swap 又重新开启。所以需要编辑/etc/fstab,注释掉类似swapfile的行。
转发 IPv4 并让 iptables 看到桥接流量
执行下述命令:
$ cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf
overlay
br_netfilter
EOF
$ sudo modprobe overlay
$ sudo modprobe br_netfilter
$ cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.ipv4.ip_forward = 1
EOF
$ sudo sysctl --system
安装 kubeadm
现在我们已经有两台可用的虚拟机,可以开始搭建 kubernetes 集群了。在本教程里我们使用 kubeadm 来创建 kubernetes 集群,这些安装的动作在两台虚拟机中都需要执行。
安装相关依赖:
$ sudo apt-get install -y apt-transport-https ca-certificates curl
下载用于 kubernetes 软件包仓库的公共签名密钥:
$ curl -fsSL https://pkgs.k8s.io/core:/stable:/v1.28/deb/Release.key | sudo gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg
添加 kubernetes apt 仓库:
$ echo 'deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/v1.28/deb/ /' | sudo tee /etc/apt/sources.list.d/kubernetes.list
更新 apt 包索引,安装 kubelet、kubeadm 和 kubectl,并锁定其版本:
$ sudo apt-get update
$ sudo apt-get install -y kubelet kubeadm kubectl
$ sudo apt-mark hold kubelet kubeadm kubectl
安装 containerd
在最新的 kubernetes 中已经使用 containerd 作为默认的容器运行时,所以我们需要安装 containerd 。先安装依赖:
$ sudo apt-get install ca-certificates curl gnupg
下载用于 docker 软件包仓库的公共签名密钥:
$ sudo install -m 0755 -d /etc/apt/keyrings
$curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
$ sudo chmod a+r /etc/apt/keyrings/docker.gpg
添加 docker 仓库:
$ echo \
"deb [arch="$(dpkg --print-architecture)" signed-by=/etc/apt/keyrings/docker.gpg] https://download.docker.com/linux/ubuntu \
"$(. /etc/os-release && echo "$VERSION_CODENAME")" stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
更新 apt 包索引,并安装 containerd:
$ sudo apt-get update
$ sudo apt-get install containerd.io
创建 containerd的默认配置文件,保存到 /etc/containerd/config.toml:
$ containerd config default > /etc/containerd/config.toml
由于一些众所周知的原因,部分容器镜像很难拉取到,所以这里我们需要修改默认配置:
# sandbox_image修改为aliyun源
sandbox_image = "registry.aliyuncs.com/k8sxio/pause:3.8"
# 启动 systemd cgroup 驱动
SystemdCgroup = true
使配置生效:
systemctl daemon-reload
systemctl restart containerd.service
搭建 kubernetes 集群
到这里终于开始正式搭建 kubernetes 集群了,我们需要在 master 节点执行 kubeadm init命令,该命令执行完成后会输入 kubeadm join的命令(携带 Token ),然后我们将该命令拷贝到 worker 执行。
master
这里我们需要提供 --image-repository的参数,让 kubeadm 去指定的镜像仓库拉取镜像,一般这一步执行失败的原因,都是无法拉取镜像。
这里的镜像仓库只会影响
api-server、coredns等镜像的拉取,像pause容器的镜像由于是与容器运行时强关联的,所以必须是在 containerd 的配置里调整,具体可以参考刚才的对 containerd.toml的修改。
$ sudo kubeadm init --image-repository='registry.cn-hangzhou.aliyuncs.com/google_containers'
安装完毕后,根据提示,执行如下命令。这样 kubectl 才有权限访问该 kubernetes 集群:
$ mkdir -p $HOME/.kube
$ sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
$ sudo chown $(id -u):$(id -g) $HOME/.kube/config
worker
master 的 kubeadm 安装结束后,会输出一条 kubeadm join 的命令,直接拷贝后在 worker 执行即可:
kubeadm join 192.168.31.29:6443 --token 8ne0da.ookb5unh530axtpj \
--discovery-token-ca-cert-hash sha256:c0063d0f593676199edb6e5db47c2f08120bc8090f2f8ed302
在 master 和 worker 都执行完 kubeadm 命令后,我们在 master 上就可以查看 node 的信息,可以看到目前 node1 & node2 都已经加入 kubernetes 集群,STATUS 都是 NotReady 的状态:
kubectl get no -A -owide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
node1 NotReady control-plane 93s v1.28.2 192.168.31.29 <none> Ubuntu 22.04.2 LTS 6.2.0-33-generic containerd://1.6.24
node2 NotReady <none> 17s v1.28.2 192.168.31.68 <none> Ubuntu 22.04.2 LTS 6.2.0-33-generic containerd://1.6.24
同时我们可以看到 pod 的信息,kubernetes 的核心组件都已经在 Running 状态。其中 coredns 仍然处在 Pending 状态, 这是正常的:
kubectl get po -A -owide
NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
kube-system coredns-6554b8b87f-59p6w 0/1 Pending 0 4m19s <none> <none> <none> <none>
kube-system coredns-6554b8b87f-kwkw8 0/1 Pending 0 4m19s <none> <none> <none> <none>
kube-system etcd-node1 1/1 Running 0 4m24s 192.168.31.29 node1 <none> <none>
kube-system kube-apiserver-node1 1/1 Running 0 4m24s 192.168.31.29 node1 <none> <none>
kube-system kube-controller-manager-node1 1/1 Running 0 4m24s 192.168.31.29 node1 <none> <none>
kube-system kube-proxy-q2td8 1/1 Running 0 3m12s 192.168.31.68 node2 <none> <none>
kube-system kube-proxy-w72hz 1/1 Running 0 4m19s 192.168.31.29 node1 <none> <none>
kube-system kube-scheduler-node1 1/1 Running 0 4m24s 192.168.31.29 node1 <none> <none>
为了解决节点 NotReady 和 coredns Pending的问题,我们需要安装网络插件,这里我们使用的是 kube-ovn 插件。
安装 kube-ovn插件
我们到官网下载 kube-ovn 的安装脚本:
$ wget https://raw.githubusercontent.com/kubeovn/kube-ovn/release-1.12/dist/images/install.sh
执行安装即可(如果执行失败,可以从官网下载 cleanup.sh 的脚本执行回退,再重复安装几次,一般失败都是因为镜像拉取的问题。):
$ bash install.sh
执行成功后可以看到 kube-ovn 的 logo,之后就可以重新查看节点和 pod 的信息:
$ kubectl get node
NAME STATUS ROLES AGE VERSION
node1 Ready control-plane 4h v1.28.2
node2 Ready <none> 3h59m v1.28.2
$ kubectl get po -A -owide
NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
kube-system coredns-6554b8b87f-xx59w 1/1 Running 0 88s 10.16.0.5 node2 <none> <none>
kube-system coredns-6554b8b87f-zzdsb 1/1 Running 0 88s 10.16.0.4 node2 <none> <none>
kube-system etcd-node1 1/1 Running 0 4h1m 192.168.31.29 node1 <none> <none>
kube-system kube-apiserver-node1 1/1 Running 0 4h1m 192.168.31.29 node1 <none> <none>
kube-system kube-controller-manager-node1 1/1 Running 0 4h1m 192.168.31.29 node1 <none> <none>
kube-system kube-ovn-cni-bvj4b 1/1 Running 0 96s 192.168.31.29 node1 <none> <none>
kube-system kube-ovn-cni-hqqvn 1/1 Running 0 96s 192.168.31.68 node2 <none> <none>
kube-system kube-ovn-controller-65f6f75847-xjkgv 1/1 Running 0 96s 192.168.31.68 node2 <none> <none>
kube-system kube-ovn-monitor-bd6bdf97-nmlbl 1/1 Running 0 96s 192.168.31.29 node1 <none> <none>
kube-system kube-ovn-pinger-8cmjp 1/1 Running 0 86s 10.16.0.6 node2 <none> <none>
kube-system kube-proxy-q2td8 1/1 Running 0 4h 192.168.31.68 node2 <none> <none>
kube-system kube-proxy-w72hz 1/1 Running 0 4h1m 192.168.31.29 node1 <none> <none>
kube-system kube-scheduler-node1 1/1 Running 0 4h1m 192.168.31.29 node1 <none> <none>
kube-system ovn-central-745ff54dc-kzptf 1/1 Running 0 2m28s 192.168.31.29 node1 <none> <none>
kube-system ovs-ovn-5gw99 1/1 Running 0 2m28s 192.168.31.29 node1 <none> <none>
kube-system ovs-ovn-qcxr8 1/1 Running 0 2m27s 192.168.31.68 node2 <none> <none>
可以看到这里节点都已经 Ready,并且所有核心组件都处在 Running状态。到此位置 Kubernetes 集群就已经搭建完成,后续我们会基于这个集群进行实验。
如果觉得有帮助,请关注我的微信公众号


















 519
519

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









