






我们继续介绍 Linux 中常见的网络设备,今天主要讲的是 Linux Bridge 和 Veth Pair,理解清楚这两种设备对后续理解容器化网络会比较有帮助。我们之前也有介绍过其它网络设备,感兴趣可以关联阅读:
veth pair 两端互通
我们先看一下 veth pair,这是成对出现的虚拟网络设备,可以简单想象这是两块网卡,中间有一条网线相连。
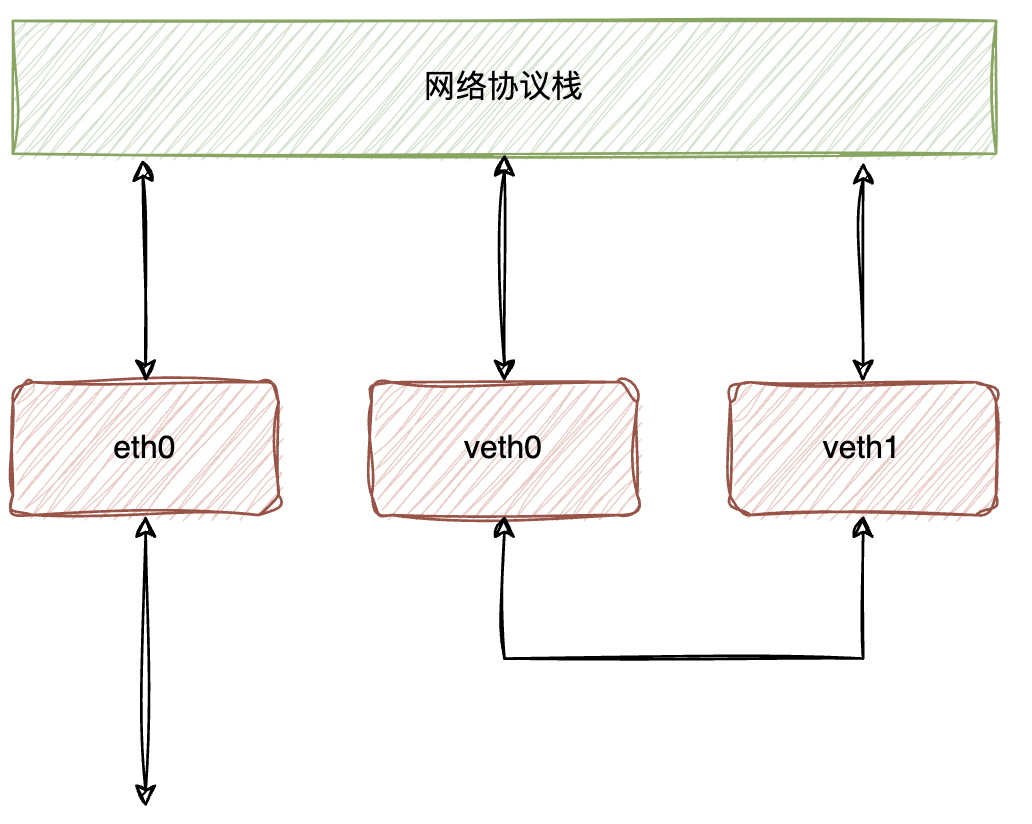
通过 ip 命令,可以创建 veth pair,我们创建veth0和veth1,分别绑定 IP 并置为 UP 状态:
$ ip link add veth0 type veth peer name veth1
$ ip link add veth0 type veth peer name veth1
$ ip addr add 10.1.1.100/24 dev veth0
$ ip addr add 10.1.1.101/24 dev veth1
$ ip link set veth0 up
$ ip link set veth1 up
ip a查看一下网络设备状态,veth0和veth1已经正常创建并绑定 IP:
$ ip a
...
20: veth1@veth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 36:c9:5b:1a:6d:9b brd ff:ff:ff:ff:ff:ff
inet 10.1.1.101/24 scope global veth1
valid_lft forever preferred_lft forever
inet6 fe80::34c9:5bff:fe1a:6d9b/64 scope link
valid_lft forever preferred_lft forever
21: veth0@veth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether c6:5e:14:55:f5:b1 brd ff:ff:ff:ff:ff:ff
inet 10.1.1.100/24 scope global veth0
valid_lft forever preferred_lft forever
inet6 fe80::c45e:14ff:fe55:f5b1/64 scope link
valid_lft forever preferred_lft forever
我们尝试一下将 vair pair 的一段置为 DOWN,再查看一下网络设备状态,可以看到我只是将
veth0置为 DOWN,但是随之veth1也进入 M-DOWN 的状态。因为 veth pair 的两块网络设备彼此对向,当veth0置为 DOWN 时,意味着它无法接受数据,随之另一端veth1也就不能正常工作,所以内核会将其自动置为 M-DOWN,以保持两端的一致性。$ ip link set veth1 down $ ip a 20: veth1@veth0: <BROADCAST,MULTICAST> mtu 1500 qdisc noqueue state DOWN group default qlen 1000 link/ether 36:c9:5b:1a:6d:9b brd ff:ff:ff:ff:ff:ff inet 10.1.1.101/24 scope global veth1 valid_lft forever preferred_lft forever 21: veth0@veth1: <NO-CARRIER,BROADCAST,MULTICAST,UP,M-DOWN> mtu 1500 qdisc noqueue state LOWERLAYERDOWN group default qlen 1000 link/ether c6:5e:14:55:f5:b1 brd ff:ff:ff:ff:ff:ff inet 10.1.1.100/24 scope global veth0 valid_lft forever preferred_lft forever inet6 fe80::c45e:14ff:fe55:f5b1/64 scope link valid_lft forever preferred_lft forever
我们说veth0和veth1逻辑上有一根网线相连,所以理论上通过veth0 ping veth1是能通的,我们试一下:
ping -c 1 -I veth0 10.1.1.101
PING 10.1.1.101 (10.1.1.101) from 10.1.1.100 veth0: 56(84) bytes of data.
From 10.1.1.100 icmp_seq=1 Destination Host Unreachable
--- 10.1.1.101 ping statistics ---
1 packets transmitted, 0 received, +1 errors, 100% packet loss, time 0ms
可以看到并不能 ping 通,我们在veth0抓包看下:
tcpdump -n -i veth0
14:41:23.473479 ARP, Request who-has 10.1.1.101 tell 10.1.1.100, length 28
14:41:24.496485 ARP, Request who-has 10.1.1.101 tell 10.1.1.100, length 28
14:41:25.520479 ARP, Request who-has 10.1.1.101 tell 10.1.1.100, length 28
原因是veth0和veth1虽然处在同一网段,但由于是第一次通信,所以 ARP 表中并不存在10.1.1.101的 MAC 信息,需要先发送 ARP Request,但是并没有收到响应。这是因为 Ubuntu 内核中一些默认配置限制导致的,我们先放开限制:
$ echo 1 > /proc/sys/net/ipv4/conf/veth0/accept_local
$ echo 1 > /proc/sys/net/ipv4/conf/veth1/accept_local
现在就能 ping 通了:
$ ping -c 1 -I veth0 10.1.1.101
PING 10.1.1.101 (10.1.1.101) from 10.1.1.100 veth0: 56(84) bytes of data.
64 bytes from 10.1.1.101: icmp_seq=1 ttl=64 time=0.140 ms
--- 10.1.1.101 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
我们在veth0和veth1抓包看一下过程:
# shell-0
$ tcpdump -n -i veth0 icmp
14:54:33.638414 IP 10.1.1.100 > 10.1.1.101: ICMP echo request, id 12, seq 1, length 64
# shell-1
$ tcpdump -n -i veth1 icmp
14:54:33.638420 IP 10.1.1.100 > 10.1.1.101: ICMP echo request, id 12, seq 1, length 64
# shell-2
$ ping -c 1 -I veth0 10.1.1.101
PING 10.1.1.101 (10.1.1.101) from 10.1.1.100 veth0: 56(84) bytes of data.
64 bytes from 10.1.1.101: icmp_seq=1 ttl=64 time=0.043 ms
--- 10.1.1.101 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
从shell-0和shell-1的微小的时间戳上的差异,我们可以看到当执行 ping 命令时,veth0先接收到 ICMP Request,随即立刻发送给对端的veth1,但是在两个设备上都没有看到 ICMP Reply,可 ping 命令确实显示 1 packets transmitted。
其实原因很简单,ICMP Reply 是走的 loopback 的口。
$ tcpdump -n -i lo icmp
14:54:33.638441 IP 10.1.1.101 > 10.1.1.100: ICMP echo reply, id 12, seq 1, length 64
我们来看一下数据包的流转过程:
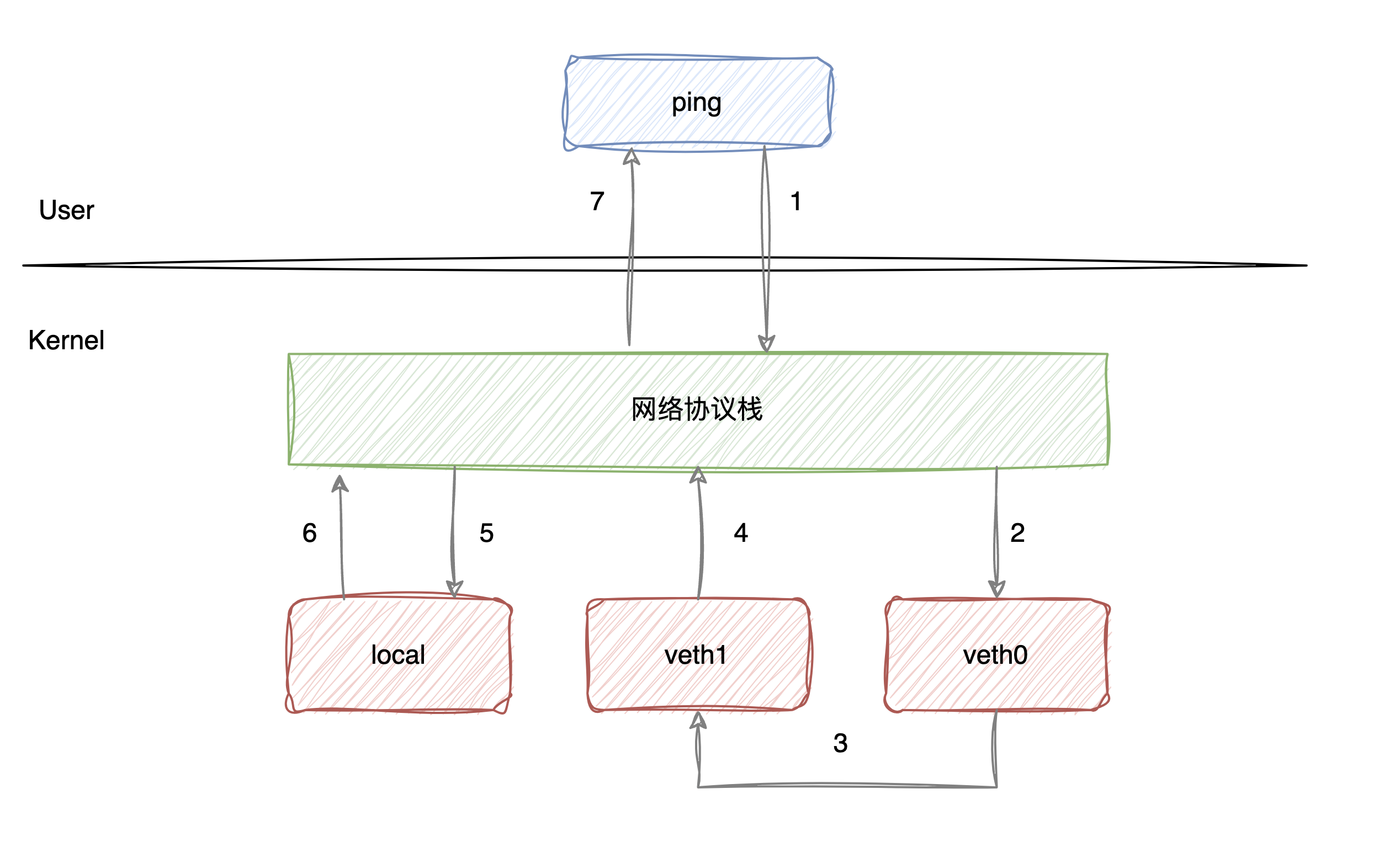
流程大致如下:
- 首先 ping 程序构造 ICMP Request,通过 Socket API 发送给内核的网络协议栈;
- 在 ping 中我们通过
-I veth0指定走veth0网卡,所以协议栈会将数据包交给veth0; - 由于
veth0和veth1间有逻辑上存在的网线,数据包会直接交到veth1; veth1接收到数据包后也不做处理,转手交给内核协议栈;- 内核协议栈在接收到数据包后,发现
10.1.1.101是本地的 IP,所以会构造 ICMP Reply的包,查看路由表之后发现10.1.1.101应该走 loopback 的口(ip route show table local); - loopback 接收到 ICMP Reply 后,转发给内核协议栈;
- 最终协议栈将数据包交给 ping 进程,ping 成功收到 ICMP Reply包;
当给
veth0和veth1配置 IP 时,内核会自动在local表中添加路由:$ ip route show table local local 10.1.1.100 dev veth0 proto kernel scope host src 10.1.1.100 local 10.1.1.101 dev veth1 proto kernel scope host src 10.1.1.101 broadcast 10.1.1.255 dev veth1 proto kernel scope link src 10.1.1.101 broadcast 10.1.1.255 dev veth0 proto kernel scope link src 10.1.1.100 ...
宿主机与容器间的网络
我们知道在容器里大量用到 namespace 来实现容器间的隔离性,对容器网络也是一样的,我们先看一下在宿主机默认的 namespace 下的网络设备:
$ ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: enp1s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 52:54:00:cb:f0:b3 brd ff:ff:ff:ff:ff:ff
inet 192.168.31.92/24 brd 192.168.31.255 scope global dynamic noprefixroute enp1s0
valid_lft 42114sec preferred_lft 42114sec
inet6 fe80::b5fc:b1f8:2b4:a62d/64 scope link noprefixroute
valid_lft forever preferred_lft forever
然后我们创建一个 netns ns1,再查看下ns1中的网络设备:
$ ip netns add ns1
$ ip netns exec ns1 ip a
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
root@bridge1:~#
可以看到在ns1中,只有一个默认创建lo设备,除此之外,所有的路由规则、防火墙规则等也与默认 namespace 是完全隔离的。
这时候我们想将ns1的网络与宿主机打通,就可以考虑使用 veth pair:
# 创建 namespace `ns1`
$ ip netns add ns1
# 创建 veth pair
$ ip link add veth0 type veth peer name veth1
# 将`veth1`的 netns 设置为`ns1`
$ ip link set veth1 netns ns1
# 分别初始化`veth0`和`veth1`的设置
$ ip addr add 10.1.1.100/24 dev veth0
$ ip link set veth0 up
$ ip netns exec ns1 ip addr add 10.1.1.101/24 dev veth1
$ ip netns exec ns1 ip link set veth1 up
这时候查看默认 namespace 和ns1的网络设备,可以看到veth0和veth1设备配置正常:
$ ip a
...
2: enp1s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 52:54:00:cb:f0:b3 brd ff:ff:ff:ff:ff:ff
inet 192.168.31.92/24 brd 192.168.31.255 scope global dynamic noprefixroute enp1s0
valid_lft 41661sec preferred_lft 41661sec
inet6 fe80::b5fc:b1f8:2b4:a62d/64 scope link noprefixroute
valid_lft forever preferred_lft forever
10: veth0@if9: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether c6:5e:14:55:f5:b1 brd ff:ff:ff:ff:ff:ff link-netns ns1
inet 10.1.1.100/24 scope global veth0
valid_lft forever preferred_lft forever
inet6 fe80::c45e:14ff:fe55:f5b1/64 scope link
valid_lft forever preferred_lft forever
$ ip netns exec ns1 ip a
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
9: veth1@if10: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 36:c9:5b:1a:6d:9b brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.1.1.101/24 scope global veth1
valid_lft forever preferred_lft forever
inet6 fe80::34c9:5bff:fe1a:6d9b/64 scope link
valid_lft forever preferred_lft forever
然后尝试下通过ns1的veth1接口来 ping 默认 namespace 下的veth0,并在veth0上抓包:
# shell-0
$ ip netns exec ns1 ping -c 1 10.1.1.100
PING 10.1.1.100 (10.1.1.100) 56(84) bytes of data.
64 bytes from 10.1.1.100: icmp_seq=1 ttl=64 time=0.143 ms
64 bytes from 10.1.1.100: icmp_seq=2 ttl=64 time=0.046 ms
--- 10.1.1.100 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 1026ms
# shell-1
$ tcpdump -n -i veth0 icmp
08:39:52.182061 IP 10.1.1.101 > 10.1.1.100: ICMP echo request, id 44179, seq 1, length 64
08:39:52.182131 IP 10.1.1.100 > 10.1.1.101: ICMP echo reply, id 44179, seq 1, length 64
因为 veth pair 的特性,所以即便veth0和veth1处在不同的 namespace,它们之间也可以正常通信,并且在veth0网卡上我们可以看到完整的 ICMP Request 和 ICMP Reply 数据包。
还记得在上面的例子中,ICMP Reply 是走的 loopback 的口吗?在当前的场景里,因为veth0和veth1已经在不同的 namespace 下了,所以当veth0在回包时,去路由表local查询,并不会认为veth1 10.1.1.100是本地接口,所以会正常从veth0回包,我们可以看下这两个 namespace 的路由表来验证判断:
$ ip route show table local
local 10.1.1.100 dev veth0 proto kernel scope host src 10.1.1.100
broadcast 10.1.1.255 dev veth0 proto kernel scope link src 10.1.1.100
...
$ ip netns exec ns1 ip route show table local
local 10.1.1.101 dev veth1 proto kernel scope host src 10.1.1.101
broadcast 10.1.1.255 dev veth1 proto kernel scope link src 10.1.1.101
容器间的网络
我们刚才看到了在宿主机默认 namespace 和容器 namespace ns1之间,通过 veth pair 可以打通网络,逻辑上就相当于宿主机和容器是两台独立的主机,通过一条网线连接在了一起。
正常一台宿主机里不会只有一个容器,宿主机和容器是一对多的关系,如果要打通容器之间的网络,单纯的依赖 veth pair 也可以做到,但配置就比较复杂,所以在这里我们引入 bridge 来实现。
Linux 的 bridge 是内核提供的虚拟以太网桥,原理上类似于物理交换机,工作在第二层。我们在 Linux 上创建一个 bridge,然后将容器通过 veth pair 插入到这个 bridge 上,以实现容器间的网络互通。
首先创建并启用 bridge br0:
$ brctl addbr br0
$ ip link set br0 up
然后通过 namespace 来模拟容器网络:
# `ns0`作为容器网络,将 veth pair 的一端放入`ns0`,另一端插入交换机`br0`
$ ip netns add ns0
$ ip link add veth0 type veth peer name veth0_br
$ ip link set veth0 netns ns0
$ ip netns exec ns0 ip addr add 10.1.1.100/24 dev veth0
$ ip link set veth0_br up
$ ip netns exec ns0 ip link set veth0 up
$ brctl addif br0 veth0_br
# `ns1`作为容器网络,将 veth pair 的一端放入`ns1`,另一端插入交换机`br0`
$ ip netns add ns1
$ ip link add veth1 type veth peer name veth1_br
$ ip link set veth1 netns ns1
$ ip netns exec ns1 ip addr add 10.1.1.101/24 dev veth1
$ ip link set veth1_br up
$ ip netns exec ns1 ip link set veth1 up
$ brctl addif br0 veth1_br
可以看到容器网络可以正常打通:
ip netns exec ns0 ping -c1 10.1.1.101
PING 10.1.1.101 (10.1.1.101) 56(84) bytes of data.
64 bytes from 10.1.1.101: icmp_seq=1 ttl=64 time=0.058 ms
--- 10.1.1.101 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
容器访问外部网络
在刚才的例子中,处在不同 namespace 的容器网络可以通过 veth pair 与 bridge 相连的方式来相互打通,但是如果容器内想要访问外部的网络,就还需要做一些额外的配置。
这里说明一下我的网络环境,我用来测试的 Ubuntu 的机器是插在一个路由器上的,这个路由器的 IP 是
192.168.31.1,DHCP 的网段是192.168.31.0/24,为了使容器网络能跟外部网络通信,这里我们采用简单一点的方式,就是将容器的网卡 IP 设置成物理网卡的 IP 处在同一网段。
首先创建 bridge br0:
$ brctl addbr br0
$ ip link set br0 up
然后创建 namespace ns0作为容器网络,创建 veth pair veth0和veth0_br,其一端放入ns0,另一端插入网桥br0(这里注意一下我给veth0配置的 IP 192.168.31.100是物理网络的网段)。
$ ip netns add ns0
$ ip link add veth0 type veth peer name veth0_br
$ ip link set veth0 netns ns0
$ ip netns exec ns0 ip addr add 192.168.31.100/24 dev veth0
$ ip link set veth0_br up
$ ip netns exec ns0 ip link set veth0 up
$ brctl addif br0 veth0_br
这里还有一个重要的配置,是在ns0中将默认路由的网关配置为192.168.31.1这个物理网络的网关。
$ ip netns exec ns0 ip route add default via 192.168.31.1 dev veth0
$ ip netns exec ns0 route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.31.1 0.0.0.0 UG 0 0 0 veth0
192.168.31.0 0.0.0.0 255.255.255.0 U 0 0 0 veth0
此时br0上已经插入了veth0_br网卡,但我们知道如果仅仅是这样是无法与外部网络通信的,我们还需要将物理网卡也插入网桥,这样逻辑上物理路由器、物理网卡、veth0_br和veth0会处在一个二层内。
ip addr add 192.168.31.92/24 dev br0
ip addr del 192.168.31.92/24 dev enp1s0
brctl addif br0 enp1s0
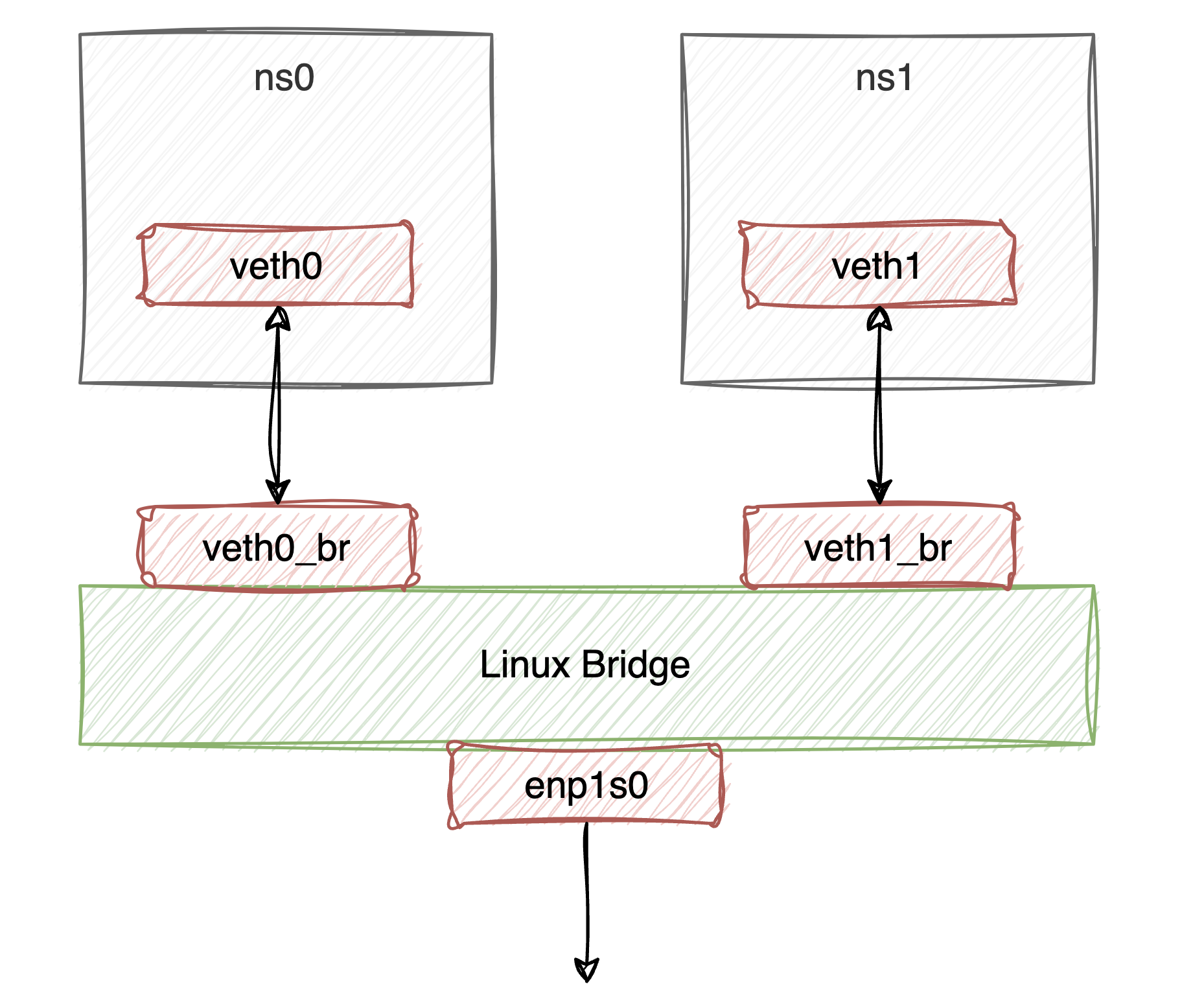
通过这样的配置,容器就能正常访问外部网络了。
$ ip netns exec ns0 ping -c 1 8.8.8.8
PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data.
64 bytes from 39.156.66.10: icmp_seq=1 ttl=46 time=37.3 ms
--- 39.156.66.10 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 2003ms
我们今天介绍了通过 bridge + veth pair 来实现单节点的容器网络的思路,后续会介绍跨节点的场景下的实现。
如果对文章内容有疑问,或者有其他技术上的交流,可以关注我的公众号:李若年















 2784
2784











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









