







论文:EfficientNetV2: Smaller Models and Faster Training(2021.4)
作者:Mingxing Tan, Quoc V. Le
链接:https://arxiv.org/abs/2104.00298
代码:https://github.com/google/automl/tree/master/efficientnetv2
EfficientnetV1解读
接着上一篇EfficientnetV1,V2是对V1的改进,可能精度更高或者更快,所以又接着探索EfficientnetV2,结果和预料一样,在其中也发现了之前很容易忽视的关系到模型精度的细节,网络输入的input-size的重要性。
按照efficientnetv2论文中的实验结果,efficientnetv2_s的精度是比efficientnet-B3的精度高2.4%的,但我们实验跑出的结果却是几乎没什么提升,再结合之前efficientnet-B7和efficientnet-B3跑出的结果也相似,想想这与论文得到的结果不符啊,想了很久才恍然大悟,我们实验是用的相同大小输入图像,这限制了大规模模型比如efficientnet-B7的能力,efficientnetv2_s的情况也一样,后来换成大尺寸输入图片,efficientnetv2_s相对于efficientnet-B3的优势就凸显出来了。
文章目录
1、算法概述
该算法作者是和Efficientnet是同一作者,是Efficientnet的升级版本,作者将训练感知神经结构搜索和缩放相结合,共同优化训练速度和参数效率。在搜索空间中对模型进行搜索,并加入了Fused-MBConv等新操作。作者还提出了一种改进的渐进式学习方法(训练过程中输入图像逐渐增大),该方法可以根据图像大小自适应地调整正则化(例如数据增强)。以这种方式训练,在ImageNet21k的预训练模型加载情况下,EfficientnetV2在ImageNet数据集上实现了87.3%的Top-1准确率,比ViT高2%,而且在相同资源情况下,训练速度加快了5到11倍。具体情况如下图所示:
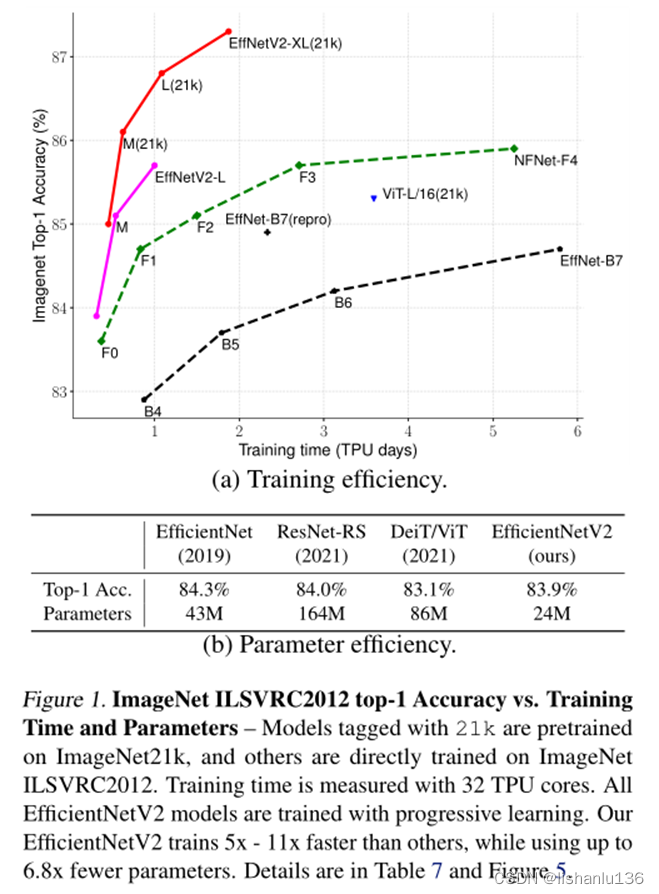
2、背景知识
训练高效与参数高效:
像DenseNet和Efficientnet都属于参数高效,目的是以较少的参数获得较高的精度。而最近也有很多工作将目的转化为提升训练速度和推理速度,比如RegNet、ResNeSt、Efficientnet-X,它们关注GPU/TPU的推理速度,而NFNets和BoTNets关注提升训练速度,但是它们一个共同点就是会带来更多的参数,而作者所提的EfficientnetV2旨在提升训练速度的同时减小参数量,即训练高效的同时保持参数高效。
渐进式训练
之前也有工作采用渐进式训练,它们的目的大多是为了加速训练,但通常情况下会带来掉精度的问题。另一个相关的工作是最近的Mix&Match,它为每个批次随机采样不同大小的图像进行训练,但是却为每个批次都使用相同的正则化,导致精度下降。本文中,作者主要区别在于自适应调整正则化,从而提高了训练速度和准确性。作者安排训练示例从简单到困难进行训练,通过添加更多的正则化来逐渐增加学习难度。
神经网络结构搜索(NAS)
NASNet通过将搜索目标定为FLOPs高效或者推理高效,本文将搜索目标定为训练高效和参数高效。
EfficientNet
它利用NAS搜索在准确性和flop方面有更好权衡搜索得到基线模型EfficientNet-B0,然后通过模型复合缩放策略得到Efficientnet-B1至B7。详细解读见我的另一篇文章EfficientnetV1解读
3、EfficientNetV2细节
3.1 如何让训练高效
训练大尺寸图像较慢,用较小图片训练,可以加速训练过程,然后用大尺寸图片推理,可以得到相似精度。实际EfficientnetV2实验中是渐进式增大训练图像尺寸,然后渐进式增加正则化进行训练。

efficientnetv1版本的训练图片尺寸如下所示:

对比来看,efficientnetv2版本官方代码给的配置都是用较小的图片尺寸训练,然后用稍大的图片尺寸推理的,并且随着网络规模的增大,正则化也在加大。

深度可分离卷积在网络层前期是缓慢的,但在网络层后期是高效的。
深度可分离卷积比常规卷积具有更少的参数和FLOPs,但它们通常不能充分利用现代加速器进行加速。而Fused-MBConv可以很好的利用移动端或服务器加速器。其结构如下图所示,它直接把MBConv中的depthwiseconv3x3和后面的conv1x1卷积替换成了常规的conv3x3卷积。
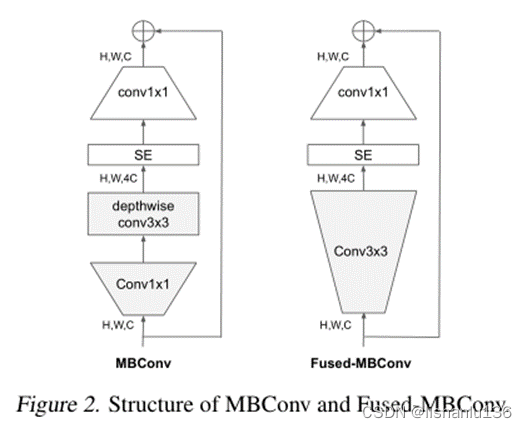
应用了Fused-MBConv的Efficientnet-B4的加速效果如下:

每个stage都以相同的缩放系数的次优的
因为每个stage对训练时间和拥有的参数量的贡献都不是相同的,在本文中,作者将使用非均匀缩放策略在网络后期阶段逐渐添加更多的层。此外,EfficientNets倾向于扩展图像大小,导致大量内存消耗和缓慢的训练。为了解决这个问题,作者稍微修改了缩放规则,并将最大图像大小限制为较小的值。
3.2 EfficientnetV2结构
通过NAS Search得到的EfficientnetV2_s结构如下

与之相对应的Efficientnet-B0结构如下:

可以看出相对于Efficientnet几点不同:
1、 EfficientnetV2在网络前几层使用Fused-MBConv替换了MBConv;
2、 EfficientnetV2中MBConv的扩充比减小了,意味着减小了显存开销;
3、 EfficientnetV2均采用3x3的小卷积核,为了得到相同感受野,网络层数更深了;
4、 EfficientnetV2去掉了最后一个1x1的卷积层
3.3 EfficientnetV2的缩放
(1)将最大推理图像大小限制为480,因为非常大的图像通常会导致昂贵的内存和训练速度开销;
(2)作为一种启发式,我们也逐渐在网络后期阶段(如上图网络结构表中第5和第6阶段)增加更多的层,以达到为了增加网络容量而不增加太多的运行时开销。
3.4 训练速度比较
固定大小的输入图片训练速度对比情况如下:

3.5 渐进式训练
作者认为,即使对于相同的网络,较小的图像尺寸也会导致较小的网络容量,因此需要较弱的正则化;反之,更大的图像尺寸导致更多的计算和更大的容量,从而更容易出现过拟合,所以需要更强的正则化。作者采用的正则化技术有Dropout(网络级正则化技术)、RandAugment(单张图片数据增强)、Mixup(交叉图片数据增强),随着输入图片尺寸的加大,应该加强正则化。
渐进式学习的步骤如下:

4、实验
ImageNet ILSVRC2012上分类实验
网络训练采用渐进式学习,设置如下:

得到的分类结果如下:

消融实验:略















 9357
9357











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









