









上节说到job提交时候进入了taskScheduler.submitTasks(newTaskSet(tasks.toArray, stage.id, stage.latestInfo.attemptId, jobId,properties)),这节我们就一起了解一下TaskSchedule类和submitTask()方法;
第一步了解taskSchedule类的初始化,此类在sparkContext中被创建,源码见下方;createTaskScheduler函数中,TaskScheduler会根据部署方式而选择不同的SchedulerBackend来处理. 针对不同部署方式会有不同的TaskScheduler与SchedulerBackend进行组合:
- Local模式:TaskSchedulerImpl + LocalBackend
- Spark集群模式:TaskSchedulerImpl + SparkDepolySchedulerBackend
- Yarn-Cluster模式:YarnClusterScheduler + CoarseGrainedSchedulerBackend
- Yarn-Client模式:YarnClientClusterScheduler + YarnClientSchedulerBackend

下面进入scheduler.initialize(backend),taskScheduler为接口类,TaskSchedulerImpl实现taskScheduler接口,具体初始化是在taskSchedulerImpl类中,见下面源码
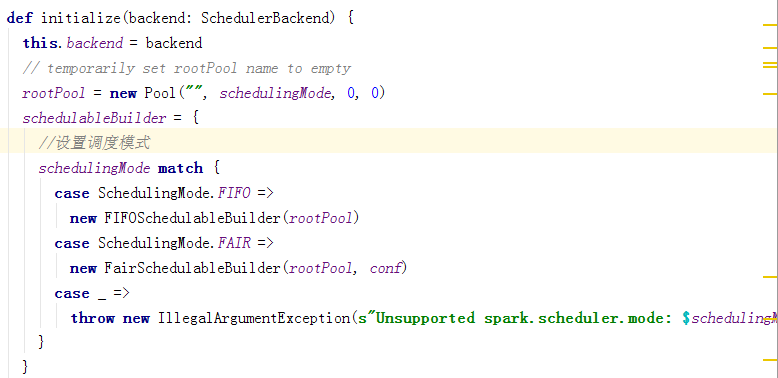
taskScheduler初始化后,会调用start方法,在start方法中,backend也会被调用

故以上可以总结:
SparkContext的createTaskScheduler创建schedulerBackend和taskScheduler–>根据不同的调度方式选择具体的scheduler和backend构造器–>调用TaskSchedulerImpl的initialize方法为scheduler的成员变量backend赋值–>createTaskScheduler返回创建好的(schedulerBackend, taskScheduler)–>调用TaskScheduler.start()启动–>实际上在TaskSchedulerImpl的start方法中调用backend.start()来启动SchedulerBackend。
TaskScheduler是在Application执行过程中,为它进行任务调度的,是属于Driver侧的。对应于一个Application就会有一个TaskScheduler,TaskScheduler和Application是一一对应的。TaskScheduler对资源的控制也比较鲁棒,一个Application申请Worker的计算资源,只要Application不结束就会一直被占有。
下面进入taskSchedulerImpl的作业提交的主要方法,此方法可以概括如下
- 任务(tasks)会被包装成TaskSetManager
- TaskSetManager实例通过schedulableBuilder(分为FIFOSchedulableBuilder和FairSchedulableBuilder两种)投入调度池中等待调度
- 调用backend的reviveOffers函数,向backend的driverActor实例发送ReviveOffers消息,driveerActor收到ReviveOffers消息后,调用makeOffers处理函数
override def submitTasks(taskSet: TaskSet) {
val tasks = taskSet.tasks
logInfo("Adding task set " + taskSet.id + " with " + tasks.length + " tasks")
//同步
this.synchronized {
//把taskSet封装为taskSetManager
val manager = createTaskSetManager(taskSet, maxTaskFailures)
val stage = taskSet.stageId
val stageTaskSets =
taskSetsByStageIdAndAttempt.getOrElseUpdate(stage, new HashMap[Int, TaskSetManager])
stageTaskSets(taskSet.stageAttemptId) = manager
val conflictingTaskSet = stageTaskSets.exists { case (_, ts) =>
ts.taskSet != taskSet && !ts.isZombie
}
if (conflictingTaskSet) {
throw new IllegalStateException(s"more than one active taskSet for stage $stage:" +
s" ${stageTaskSets.toSeq.map{_._2.taskSet.id}.mkString(",")}")
}
//把taskManager递交给scheduler
schedulableBuilder.addTaskSetManager(manager, manager.taskSet.properties)
//判断是否接收到task
if (!isLocal && !hasReceivedTask) {
starvationTimer.scheduleAtFixedRate(new TimerTask() {
override def run() {
if (!hasLaunchedTask) {
logWarning("Initial job has not accepted any resources; " +
"check your cluster UI to ensure that workers are registered " +
"and have sufficient resources")
} else {
this.cancel()
}
}
}, STARVATION_TIMEOUT_MS, STARVATION_TIMEOUT_MS)
}
hasReceivedTask = true
}
//调用backend的reviveOffers函数,向backend的driverActor实例发送ReviveOffers消息
backend.reviveOffers()
}reviveOffers函数代码
下面是CoarseGrainedSchedulerBackend的reviveOffers函数:
override def reviveOffers() {
//发送
driverEndpoint.send(ReviveOffers)
}
如上面源码可以了解,再分发task之前,先调用scheduler.resourceOffers()方法获取资源;资源分配的工作由resourceOffers函数处理;下面进行resourceOffers()方法:

def resourceOffers(offers: Seq[WorkerOffer]): Seq[Seq[TaskDescription]] = synchronized {
// Mark each slave as alive and remember its hostname
// Also track if new executor is added
var newExecAvail = false
//遍历work资源,更新executor相关的映射
for (o <- offers) {
executorIdToHost(o.executorId) = o.host
executorIdToTaskCount.getOrElseUpdate(o.executorId, 0)
if (!executorsByHost.contains(o.host)) {
executorsByHost(o.host) = new HashSet[String]()
executorAdded(o.executorId, o.host)
newExecAvail = true
}
for (rack <- getRackForHost(o.host)) {
hostsByRack.getOrElseUpdate(rack, new HashSet[String]()) += o.host
}
}
// Randomly shuffle offers to avoid always placing tasks on the same set of workers.
// 从worker当中随机选出一些来,防止任务都堆在一个机器上
val shuffledOffers = Random.shuffle(offers)
// Build a list of tasks to assign to each worker.
// worker的task列表
val tasks = shuffledOffers.map(o => new ArrayBuffer[TaskDescription](o.cores))
val availableCpus = shuffledOffers.map(o => o.cores).toArray
// getSortedTask函数对taskset进行排序
val sortedTaskSets = rootPool.getSortedTaskSetQueue
for (taskSet <- sortedTaskSets) {
logDebug("parentName: %s, name: %s, runningTasks: %s".format(
taskSet.parent.name, taskSet.name, taskSet.runningTasks))
if (newExecAvail) {
taskSet.executorAdded()
}
}
// Take each TaskSet in our scheduling order, and then offer it each node in increasing order
// of locality levels so that it gets a chance to launch local tasks on all of them.
// NOTE: the preferredLocality order: PROCESS_LOCAL, NODE_LOCAL, NO_PREF, RACK_LOCAL, ANY
// 随机遍历抽出来的worker,通过TaskSetManager的resourceOffer,把本地性最高的Task分给Worker
// 本地性是根据当前的等待时间来确定的任务本地性的级别。
// 它的本地性主要是包括四类:PROCESS_LOCAL, NODE_LOCAL, RACK_LOCAL, ANY。
//1. 首先依次遍历 sortedTaskSets, 并对于每个 Taskset, 遍历 TaskLocality
//2. 越 local 越优先, 找不到(launchedTask 为 false)才会到下个 locality 级别
//3. (封装在resourceOfferSingleTaskSet函数)在多次遍历offer list,
//因为一次taskSet.resourceOffer只会占用一个core,
//而不是一次用光所有的 core, 这样有助于一个 taskset 中的 task 比较均匀的分布在workers上
//4. 只有在该taskset, 该locality下, 对所有worker offer都找不到合适的task时,
//才跳到下个 locality 级别
var launchedTask = false
for (taskSet <- sortedTaskSets; maxLocality <- taskSet.myLocalityLevels) {
do {
launchedTask = resourceOfferSingleTaskSet(
taskSet, maxLocality, shuffledOffers, availableCpus, tasks)
} while (launchedTask)
}
if (tasks.size > 0) {
hasLaunchedTask = true
}
return tasks
}
private def launchTasks(tasks: Seq[Seq[TaskDescription]]) {
for (task <- tasks.flatten) {
val serializedTask = ser.serialize(task)
if (serializedTask.limit >= maxRpcMessageSize) {
scheduler.taskIdToTaskSetManager.get(task.taskId).foreach { taskSetMgr =>
try {
var msg = "Serialized task %s:%d was %d bytes, which exceeds max allowed: " +
"spark.rpc.message.maxSize (%d bytes). Consider increasing " +
"spark.rpc.message.maxSize or using broadcast variables for large values."
msg = msg.format(task.taskId, task.index, serializedTask.limit, maxRpcMessageSize)
taskSetMgr.abort(msg)
} catch {
case e: Exception => logError("Exception in error callback", e)
}
}
}
else {
val executorData = executorDataMap(task.executorId)
executorData.freeCores -= scheduler.CPUS_PER_TASK
logInfo(s"Launching task ${task.taskId} on executor id: ${task.executorId} hostname: " +
s"${executorData.executorHost}.")
executorData.executorEndpoint.send(LaunchTask(new SerializableBuffer(serializedTask)))
}
}
}以上就是提交大部分过程了,下面引用张包峰的csdn博客图,此图很明显的介绍了作业提交过程:
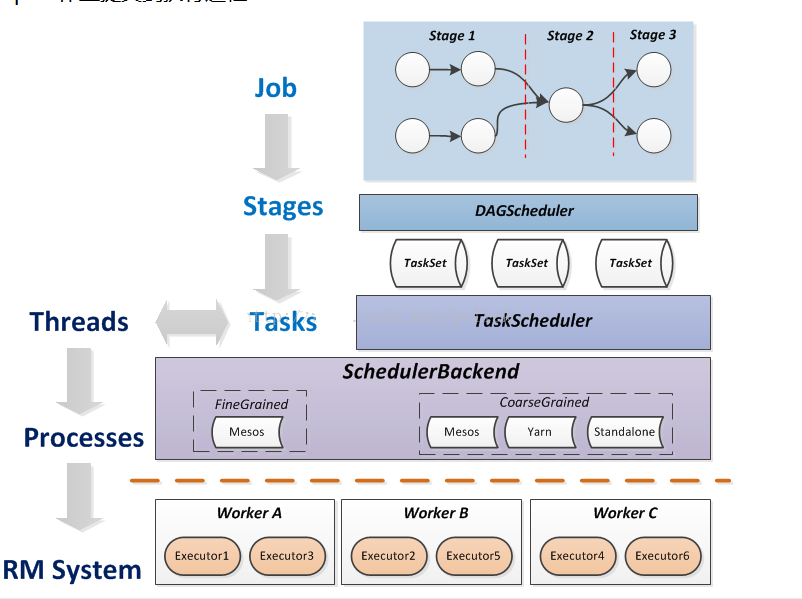

1、Driver程序的代码运行到action操作,触发了SparkContext的runJob方法。
2、SparkContext调用DAGScheduler的runJob函数。
3、DAGScheduler把Job划分stage,然后把stage转化为相应的Tasks,把Tasks交给TaskScheduler。
4、通过TaskScheduler把Tasks添加到任务队列当中,交给SchedulerBackend进行资源分配和任务调度。
5、调度器给Task分配执行Executor,ExecutorBackend负责执行Task。















 2238
2238











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









