







关于线性回归的原理请参考Coursera上斯坦福大学Andrew Ng教授的“机器学习公开课”
下面直接到sparkMlib实现线性回归,spark源码下有两个关于机器学习的包,一个是基于RDD的包Mlib-support the RDD-based API in spark.mllib,另外一个也就是spark目前主推的基于 DataFrame-based API,这个在源码的ml包下;基于DataFrame的API更加友好;下面就基于RDD的API进行分析;
训练集数据如下:
-0.4307829,-1.63735562648104 -2.00621178480549 -1.86242597251066 -1.02470580167082 -0.522940888712441 -0.863171185425945 -1.04215728919298 -0.864466507337306
-0.1625189,-1.98898046126935 -0.722008756122123 -0.787896192088153 -1.02470580167082 -0.522940888712441 -0.863171185425945 -1.04215728919298 -0.864466507337306
-0.1625189,-1.57881887548545 -2.1887840293994 1.36116336875686 -1.02470580167082 -0.522940888712441 -0.863171185425945 0.342627053981254 -0.155348103855541
-0.1625189,-2.16691708463163 -0.807993896938655 -0.787896192088153 -1.02470580167082 -0.522940888712441 -0.863171185425945 -1.04215728919298 -0.864466507337306其中第一个字段(逗号前)的为因变量Y,逗号后为自变量X1,X2,X3等,为了测试方便训练集也当做测试集使用;
public static void main(String[] args) {
SparkConf conf =new SparkConf().setAppName("lineRegression").setMaster("local[1]");
JavaSparkContext sc = new JavaSparkContext(conf);
String path = "E:/sparkMlib/sparkMlib/src/mllib/ridge-data/lpsa.data";
JavaRDD<String>data = sc.textFile(path);
JavaRDD<LabeledPoint> parseData = data.map(new Function<String,LabeledPoint>(){
public LabeledPoint call(String line) throws Exception {
String [] part = line.split(",");
//设置特征
String[] features = part[1].split(" ");
double [] v =new double[features.length-1];
for(int i=0;i<features.length-1;i++){
v[i]=Double.parseDouble(features[i]);
}
return new LabeledPoint(Double.parseDouble(part[0]),(Vector) Vectors.dense(v));
}
});
parseData.cache();
// 建立模型
int numIterations = 500;
double stepSize = 0.00000001;
final org.apache.spark.mllib.regression.LinearRegressionModel model = LinearRegressionWithSGD.train(JavaRDD.toRDD(parseData), numIterations,stepSize);
JavaRDD<Tuple2<Double, Double>> valuesAndPreds = parseData.map(
new Function<LabeledPoint, Tuple2<Double, Double>>() {
public Tuple2<Double, Double> call(LabeledPoint point) {
double prediction = model.predict(point.features());
//打印预测值和实际值
System.out.println(prediction+":"+point.label());
return new Tuple2<Double, Double>(prediction, point.label());
}
}
);
//获取均方误差
double MSE = new JavaDoubleRDD(valuesAndPreds.map(
new Function<Tuple2<Double, Double>, Object>() {
public Object call(Tuple2<Double, Double> pair) {
return Math.pow(pair._1() - pair._2(), 2.0);
}
}
).rdd()).mean();
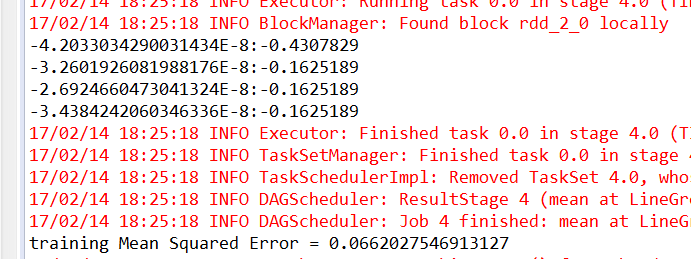
System.out.println("training Mean Squared Error = " + MSE);
}
下面就是调优;















 543
543

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









