






本文主要参考了黎湘艳、叶洋的经典著作《游戏数据分析实战》。这本书堪称游戏数据分析的开山之作,这里向两位作者表示感谢。
关于用户留存和流失的模型
参考6.1.1节“合理定义流失用户”
这里是想回答“几天不登录算流失”这个问题。
三天不登录算不算流失,可以看一下三天不登录的用户有多少再次登录了,于是引出了定义:
流失用户回归率 = 回归用户数 ➗ 流失用户数
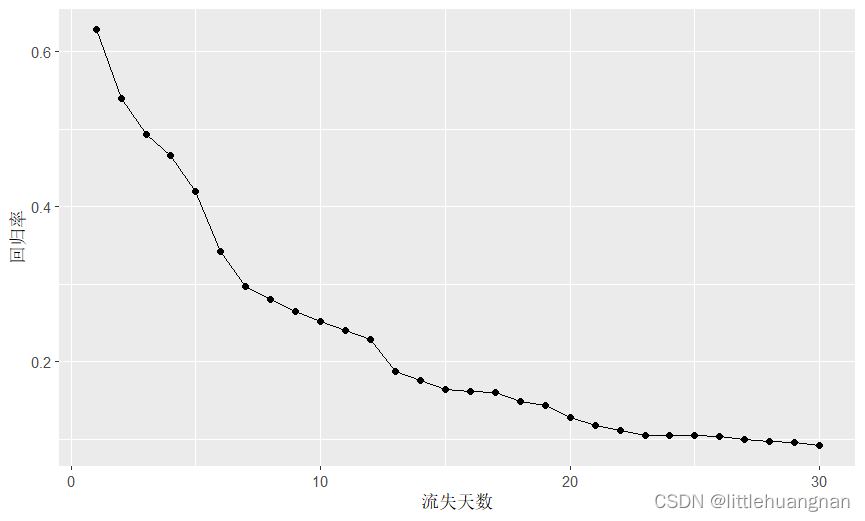
流失天数的选取,作者建议用“找拐点”的方法。例如在上图中,23天起明显平缓了,所以这个数据集中,判断流失的不登录天数就可以设为23天左右。
不过作者没有说明怎么找拐点,虽然这个例子可以用肉眼来找。我也不知道有没有特别炫酷的方法。不过可以尝试一下Max Kuhn的《应用预测建模》里介绍的“多元自适应回归样条”。
R语言有一个earth包,实现了多元自适应回归样条
library(earth)
liushi <- earth(`回归率`~`流失天数`,data=game_liushi)
summary(liushi, digits = 2, style = "pmax")
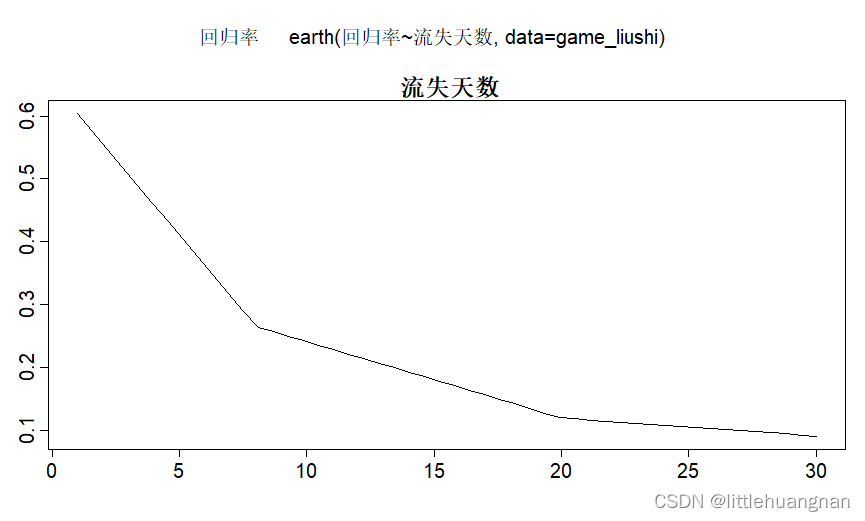 看起来,模型给我们选择第20天作为拐点。
看起来,模型给我们选择第20天作为拐点。















 7346
7346











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









