










 线性判别分析(LDA)是一种监督降维方法,用于分类问题,尤其在机器学习、图像识别和数据挖掘中广泛应用。通过找到最佳投影线,使同类样本投影点接近,异类样本远离,从而实现新样本的有效分类。LDA的目标是最大化类间距离并最小化类内距离,通过拉格朗日乘数法求解最优投影向量w,最终的解为Sw−1Sb的c−1个最大广义特征值对应的特征向量。
线性判别分析(LDA)是一种监督降维方法,用于分类问题,尤其在机器学习、图像识别和数据挖掘中广泛应用。通过找到最佳投影线,使同类样本投影点接近,异类样本远离,从而实现新样本的有效分类。LDA的目标是最大化类间距离并最小化类内距离,通过拉格朗日乘数法求解最优投影向量w,最终的解为Sw−1Sb的c−1个最大广义特征值对应的特征向量。
点击下方图片查看HappyChart专业绘图软件

线性判别分析(LDA)是一种监督学习方法,和主成分分析(PCA)一样,其主要用来降维。有些资料也把LDA称为Fisher线性判别(FLD)。LDA在机器学习,图像识别,数据挖掘等领域有着广泛的应用。
LDA的基本思想就是:给定训练样本集,设法将样本投影到一条直线上,使得同类样本的投影点尽可能地接近,异类样本的投影点尽可能远离,在对新样本进行分类时,将其投影到相同的这条直线上,再根据投影点的位置来确定新样本的类别。当是二分类问题时,如下图:
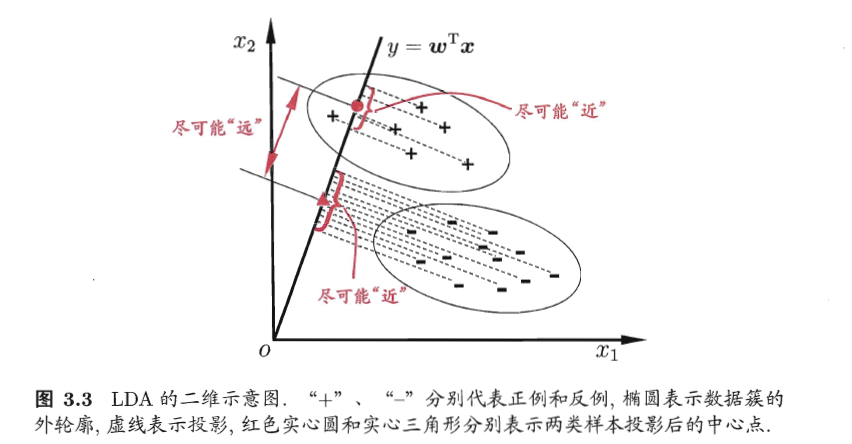
假设用来区分二分类的直线(投影函数)为:
y
=
=
w
T
x
y==w^Tx
y==wTx
LDA分类的一个目标是使得不同类之间的距离越大越好,同一类别之间的距离越小越好,先定义几个值:
类别
i
i
i的原始中心点,也就是类别
i
i
i的均值为:
m
i
=
1
n
i
Σ
x
∈
D
i
x
m_i=\frac{1}{n_i}\Sigma_{x \in D_i}x
mi=ni1Σx∈Dix
D
i
D_i
Di为属于类别
i
i
i的样本点。
类别
i
i
i投影后的中心点(均值)为:
m
i
~
=
w
T
m
i
\widetilde{m_i} = w^Tm_i
mi
=wTmi
衡量类别
i
i
i投影后,类别点之间的分散程度(方差)为:
s
i
~
=
Σ
y
∈
Y
i
(
y
−
m
i
~
)
2
\widetilde{s_i} = \Sigma_{y\in Y_i}(y-\widetilde{m_i})^2
si
=Σy∈Yi(y−mi
)2
Y
i
Y_i
Yi为类别
i
i
i投影后的样本点。
同时考虑不同类之间的距离越大越好,同一类别之间的距离越小越好,则可最大化目标函数:
J
(
w
)
=
∣
m
1
~
−
m
2
~
∣
2
s
1
~
2
+
s
2
~
2
J(w)=\frac{|\widetilde{m_1}-\widetilde{m_2}|^2}{\tilde{s_1}^2+\tilde{s_2}^2}
J(w)=s1~2+s2~2∣m1
−m2
∣2
我们最大化
J
(
w
)
J(w)
J(w)就可以求出最优的w了。要求出w,可以使用拉格朗日乘数法,但是在使用拉格朗日乘数之前,我们需要把
J
(
w
)
J(w)
J(w)里的w单独提取出来。
定义一个投影前各分类分散程度的矩阵:
S
i
=
Σ
i
∈
D
i
(
x
−
m
i
)
(
x
−
m
i
)
T
S_i = \Sigma_{i\in D_i}(x-m_i)(x-m_i)^T
Si=Σi∈Di(x−mi)(x−mi)T
可以看出,如果样本点距离中心点越近,
S
i
S_i
Si趋近于0,这表示的是类内离散程度。
将
J
(
w
)
J(w)
J(w)分母2化为:
s
i
~
=
Σ
x
∈
D
i
(
w
T
x
−
w
T
m
i
)
2
=
Σ
x
∈
D
i
w
T
(
x
−
m
i
)
(
x
−
m
i
)
T
w
=
w
T
S
i
w
\tilde{s_i}=\Sigma_{x\in D_i}(w^Tx-w^Tm_i)^2\\=\Sigma_{x\in D_i}w^T(x-m_i)(x-m_i)^Tw\\=w^TS_iw
si~=Σx∈Di(wTx−wTmi)2=Σx∈DiwT(x−mi)(x−mi)Tw=wTSiw
而
s
1
~
2
+
s
2
~
2
=
w
T
(
S
1
+
S
2
)
w
=
w
T
S
w
w
\tilde{s_1}^2+\tilde{s_2}^2=w^T(S_1+S_2)w=w^TS_ww
s1~2+s2~2=wT(S1+S2)w=wTSww,
S
w
S_w
Sw就是类内离散度矩阵。
同样,将
J
(
w
)
J(w)
J(w)分子化为:
∣
m
1
~
−
m
2
~
∣
2
=
w
T
(
m
1
−
m
2
)
(
m
1
−
m
2
)
T
w
=
w
T
S
b
w
|\widetilde{m_1}-\widetilde{m_2}|^2=w^T(m_1-m_2)(m_1-m_2)^Tw=w^TS_bw
∣m1
−m2
∣2=wT(m1−m2)(m1−m2)Tw=wTSbw
S
b
S_b
Sb表示类间的离散度矩阵。
这样目标函数转化为:
J
(
w
)
=
w
T
S
b
w
w
T
S
w
w
J(w)=\frac{w^TS_bw}{w^TS_ww}
J(w)=wTSwwwTSbw
这样就可以使用拉格朗日乘数了,但是还有一个问题,如果分子、分母是都可以取任意值的,那就会使得有无穷解,将分母限制为1(一个技巧),作为拉格朗日乘数的限制条件,代入得:
c
(
w
)
=
w
T
S
b
w
−
λ
(
s
T
S
w
w
−
1
)
⇒
d
c
d
w
=
2
S
b
w
−
2
λ
S
w
w
=
0
⇒
S
b
w
=
λ
S
w
w
c(w)=w^TS_bw-\lambda(s^TS_ww-1)\\ \Rightarrow \frac{dc}{dw}=2S_bw-2\lambda S_ww=0\\ \Rightarrow S_bw=\lambda S_ww
c(w)=wTSbw−λ(sTSww−1)⇒dwdc=2Sbw−2λSww=0⇒Sbw=λSww
对于多分类,直接写出结论:
S
w
=
Σ
i
=
1
c
S
i
S
b
=
Σ
i
=
1
c
n
i
(
m
i
−
m
)
(
m
i
−
m
)
T
S
b
w
=
λ
S
w
w
S_w=\Sigma_{i=1}^cS_i\\ S_b=\Sigma_{i=1}^cn_i(m_i-m)(m_i-m)^T\\ S_bw=\lambda S_ww
Sw=Σi=1cSiSb=Σi=1cni(mi−m)(mi−m)TSbw=λSww
其中:
c
c
c为类别个数,
m
m
m为样本总体的中心点(均值向量)。
W的闭式解则是
S
w
−
1
S
b
的
c
−
1
S_w^{-1}S_b的c-1
Sw−1Sb的c−1个最大广义特征值所对应的特征向量组成的矩阵。

















 1553
1553

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









