







文章目录
前言
整个模型研发流程包括数据处理、模型研发、测试研发、测试评估、模型部署四大步骤。
一、数据处理
(1)数据采集
数据采集的方式包括人工收集、系统采集、爬虫、虚拟仿真、对抗生成、开源数据。
(2)数据标注
数据标注的方式:人工标注、数据标注软件、自动化标注。
(3)数据清洗
(4)数据增强
数据增强的方式有增强工具、Opencv等。
比如下图:

(5)数据格式转换
(6)数据预处理
值得注意的是以下几点:
➢ 数据在进入模型前,可以通过一些预处理,去掉数据中的一些信息,以便模型能更容易的进行学习。
➢ 数据质量重于数据数量,数据质量直接影响模型精度和泛化能力,任何数据都由有效数据和噪声数据构成。
➢ 通过数据增强可以提高数据的多样性和数量,但增强的作用有限.
➢ 数据样本要能体现整体样本的分布规律,所以要科学采样,防止数据不均衡。
➢ 利用好标注数据或者数据标注自动化是降低成本和时间的有效思路。
➢ 数据处理过程中,80%的成本花在数据标注上。
➢ 研发过程中,80%的工作量花在了数据处理上。
➢ 数据按照使用在深度学习中分为训练集、验证集、测试集
➢ 模型筛选(交叉验证)适用于数据太少的情况。
二、模型研发
(1)模型设计
(2)模型优化
(3)模型训练
三、测试评估
3.1 模型测试
3.2 模型评估
模型评估,顾名思义,就说使用一些合理的方法,来评价和判断模型的优劣,具体评价标准可以体现在多个维度上,比如和精度相关的查准率(精确率)、查全率(召回率)、误检率(虚警率),还有和速度相关的FPS等等。
模型评估的作用:对一个模型在其应用的场景下进行全面的评估,使得该模型能够准确的表达对该场景下的效果。也有对各种场景的测试评估,总之,模型评估的作用就是为了证明这个模型在某种场景下的表现效果到底有多好。
性能指标
➢ 模型训练性能也是非常重要的指标。因为模型训练过程需要花费大量的时间,所以提高模型的训练性能,可以大大提高模型的研发效率。
➢ 性能指标和精度指标通常是矛盾的,所以平衡性能指标和精度指标是必要的工作。
➢ 常用的性能指标单位有: floaps/帧率等。
➢ 性能一般有两个指标:参数量和计算量。
➢ 性能指标和模型运行的平台有关。
评估指标
混淆矩阵(Confusion Matrix)
真正(True Positive, TP):被模型预测为正的正样本。
假正(False Positive , FP):被模型预测为正的负样本。
假负(False Negative , FN):被模型预测为负的正样本。
真负(True Negative , TN):被模型预测为负的负样本。
真正率(True Positive Rate,TPR): TPR=TP/(TP+FN), 即被预测为正的正样本数/正样本实际数。
假正率(False Positive Rate,FPR): FPR=FP/(FP+TN), 即被预测为正的负样本数/负样本实际数。
假负率(False Negative Rate,FNR) : FNR=FN/(TP+FN), 即被预测为负的正样本数/正样本实际数。
真负率(True Negative Rate,TNR): TNR=TN/(TN+FP), 即被预测为负的负样本数/负样本实际数
TP+FP+TN+FN=样本总数
第一个字母表示本次预测的正确性,T就是正确,F就是错误;第二个字母则表示由分类器预测的类别,P代表预测为正例,N代表预测为反例。
举例如下:

准确率(Accuracy)
Accuracy = (TP+TN)/(TP+FN+FP+TN) (正确预测的正反例数/样本总例数)
精确率(Precision)
Precision(TPP)= TP/(TP+FP) (正确预测的正例数/预测正例总数)
召回率(Recall)
Recall(TPR) = TP/(TP+FN) (正确预测的正例数/实际正例总数)
误报率(FPR)
误报率: FPR=FP/(TN+FP) (错误预测的负例数/实际负例总数)
ROC曲线

ROC曲线由召回率和误检率构成
ROC是一组向量组成的一条曲线
AUC
Roc曲线下的面积,介于0和1之间。Auc作为数值可以直观的评价分类器的好坏,值越大越好。

若一个学习器的ROC曲线被另一个学习器的曲线包住,那么我们可以断言后者性能优于前者;若两个学习器的ROC曲线发生交叉,则难以一般性断言两者孰优孰劣。此时若要进行比较,那么可以比较ROC曲线下的面积,即AUC,面积大的曲线对应的分类器性能更好。
AUC (Area Under Curve)的值为ROC曲线下面的面积,若分类器的性能极好,则AUC为1。但现实生活中尤其是工业界不会有如此完美的模型,一般AUC均在0.5到1之间,AUC越高,模型的区分能力越好,上图AUC为0.8。 若AUC=0.5,即与上图中红线重合,表示模型的区分能力与随机猜测没有差别。若AUC真的小于0.5,请检查一下是不是好坏标签标反了,或者是模型真的很差。
P-R曲线

P- R曲线即以precision和recall 作为纵、横轴坐标的二维曲线。通过选取不同阈值时对应的精度和召回率画出。

上图就是一幅P-R图, 它能直观地显示出学习器在样本总体上的查全率和查准率,显然它是一条总体趋势是递减的曲线。在进行比较时,若一个学习器的PR曲线被另一个学习器的曲线完全包住,则可断言后者的性能优于前者,比如上图中A优于C。但是B和A谁更好呢?因为AB两条曲线交叉了,所以很难比较,这时比较合理的判据就是比较R曲线下的面积,该指标在一定程度 上表征了学习器在查准率和查全率上取得相对“双高”的比例。因为这个值不容易估算,所以人们引入“平衡点”(BEP)来度量,他表示“查准率=查全率”时的取值,值越大表明分类器性能越好,以此比较我们一下子就能判断A较B好。
BEP有点简单,更常用的是F1度量:
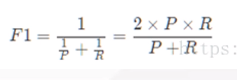
F1-score就是一个综合考虑precision和recall的指标,比BEP更为常用。
mAP
均值平均精确率,即不同类别下的平均精确率!
mAP是由召回率和精确率构成,mAP是各个不同召回率下的最大精确率的平均值。
mAP即Mean Average Precision即平均AP值,是对多个验证集个体求平均AP值,作为object detection中衡量检测精度的指标。
多标签图像分类任务中图片的标签不止一个,因此评价不能用普通单标签图像分类的标准,即mean accuracy,该任务采用的是和信息检索中类似的方法- mAP (mean Average Precision)。
AP
AP(Average Precision)即是:不同召回率下的平均。可以通过计算PR曲线的面积。
AP的计算过程:
-
排序

按照输出的置信度对数据从大到小排序。 -
计算精确率和召回率

-
画出P-R曲线
Top5数据:前5条数据的mAP值,还有Top10,top15

-
求平均值
理论上有N条正样本数据,就可以得到TopN的AP值,Top值越大,ap值越低遇到下一条正样本之后,开始新的召回率计算。

-
AP的P-R曲线

AP衡量的是学出来的模型在每个类别上的好坏,mAP衡量的是学出的模型在所有类别上的好坏。得到AP后mAP的计算就变得很简单了,就是取所有AP的平均值。
FPS
检测速率FPS(frame per second), 1秒内识别的图像数(帧数)。
如何选择评估指标
怎么选择评估指标?这种问题的答案当然是具体问题具体分析啦,单纯地回答谁好谁坏是没有意义的,我们需要结合实际场景给出合适的回答。地震注重召回率, 抓坏人注重精确率。
3.3 评估报告
四、模型部署
模型在各平台部署,包括IOS,Android, IOT 设备,服务器,接口编写。
➢ 拓扑结构: SDK调用,网络调用(socket/http)
➢ 部署系统: windows, linux, android, ios
➢ 部署平台: PC,IOT,Mobile,FPGA
➢ 接口语言: python,C++,JAVA
➢ 优化手段: Cuda, tensorRT, NPU, TPU,其他
➢ 模型加密
➢ 当前常用的推理加速硬件
- CPU
- GPU: CUDA、 TensorRT、Jetson系列( nano、tx2、xaiver)
- TPU
- NPU:华为海思/瑞芯微
- 移动:苹果/高通















 8108
8108











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









