






决策树的使用
内容来自大神点这里
我们需要先了解一些信息论中的公式
香农熵:
1948 年,香农提出了“信息熵”(shāng) 的概念,解决了对信息的量化度量问题。
一条信息的信息量大小和它的不确定性有直接的关系。比如说,我们要搞清楚一件非常非常不确定的事,或是我们一无所知的事情,就需要了解大量的信息。相反,如果我们对某件事已经有了较多的了解,我们不需要太多的信息就能把它搞清楚。所以,从这个角度,我们可以认为,信息量的度量就等于不确定性的多少。
基本的公式表达如下
对于任意一个随机变量 X,它的熵定义如下:
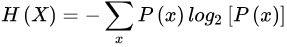
变量的不确定性越大,熵也就越大,把它搞清楚所需要的信息量也就越大。
条件熵
条件熵 H(X|Y) 表示在已知随机变量Y的条件下,随机变量 X 的不确定性。公式如下:

信息增益
简单来讲就是信息增益=香农熵-条件熵,信息增益的值越大,说明使用的条件特征分类的准确度越好。一开始我不太理解,但是后期以我的理解就是当我的条件熵的复杂度在足够小的情况下能够更好的完成分类的话。信息增益越大。我的条件特征就越有价值。
举例

这样一张图表里我们能够看到借贷的拨款与否的内容,这里面的年龄,工作,房子有无都是我们的特征。特征选择在于选取对训练数据具有分类能力的特征。这样可以提高决策树学习的效率,如果利用一个特征进行分类的结果与随机分类的结果没有很大差别,则称这个特征是没有分类能力的。经验上扔掉这样的特征对决策树学习的精度影响不大。通常特征选择的标准是信息增益(information gain)或信息增益比。
根据此公式计算经验熵H(D),分析贷款申请样本数据表中的数据。最终分类结果只有两类,即放贷和不放贷。根据表中的数据统计可知,在15个数据中,9个数据的结果为放贷,6个数据的结果为不放贷。所以数据集D的经验熵H(D)为:
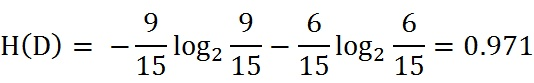
然后我们来看工作有无这个特征,它分为有和无,两个类别,其中有工作且借贷成功的概率是百分百,无工作借贷成功的概率为2/5,不成功为3/5
计算其条件熵(参考条件熵公式)。
最后根据其信息增益判断特征的好坏。















 36万+
36万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









