







0-# 前言
学习一项调优的技术时,通常需要明确三点:Why?What?How?
一、Initialization(参数初始化)
严格意义上讲,“参数初始化”并不算调优手段,anyway,参数初始化是建立模型是不可或缺的一部分,一个不错的参数初始化策略可以:
1. 加快梯度下降的收敛
2. 增加梯度下降收敛在较小误差区域的几率
3. 减少梯度消失或者梯度爆炸发生的几率
接下来,通过一个例子来说明不同的参数初始化策略带来的不同影响
目标问题:
**训练模型区分不同颜色的点**
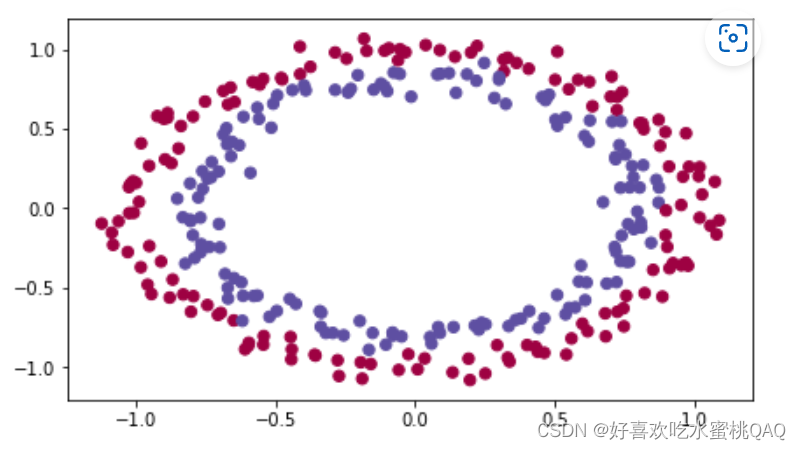
零初始化
将参数W、b都初始化为0
parameters['W' + str(i)] = np.zeros((layers_dims[i], layers_dims[i - 1]))
parameters['b' + str(i)] = np.zeros((layers_dims[i], 1))

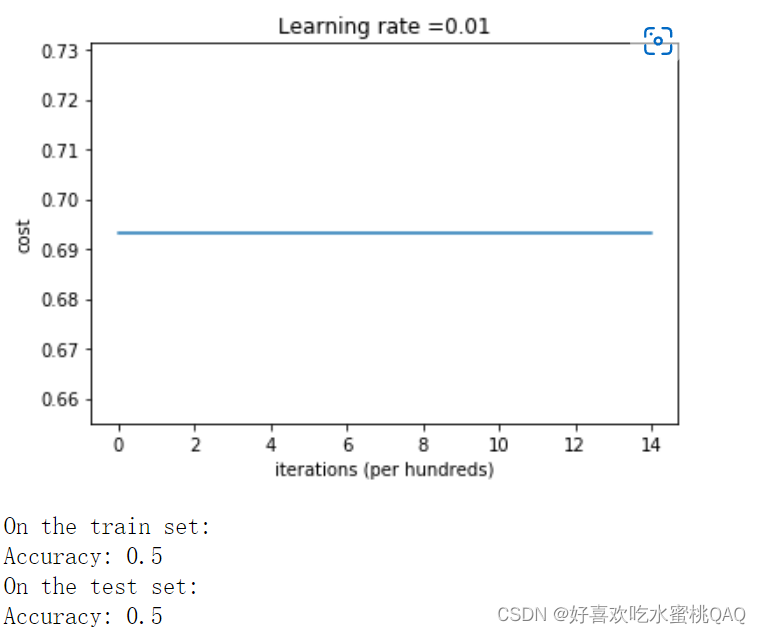
通常,不同于线性回归和逻辑回归,将所有权重W初始化为零会导致神经网络无法打破对称性。这意味着每一层中的每个神经元都将学习相同的东西,即相当于每一层都退化成了一个神经元,显然这是我们不愿意看到的结果。
Points worth emphasizing:
- 在神经网络中,参数W需要随机初始化来打破网络的对称性
- bias可以初始化为0
具体的证明细节可以参考以下两篇博客:
随机数初始化
将参数W初始化为0-10的随机数
parameters['W' + str(i)] = np.random.randn(layers_dims[i], layers_dims[i - 1]) * 10
parameters['b' + str(i)] = np.zeros((layers_dims[i], 1))
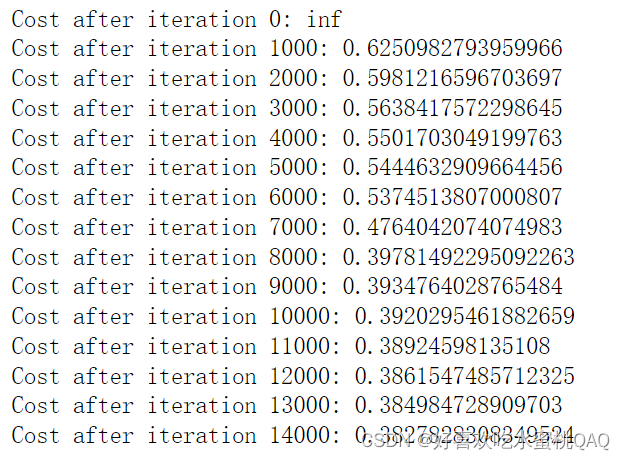
可以看到,与零初始化相比,将参数W初始化为比较大的随机数看起来效果不算太差。
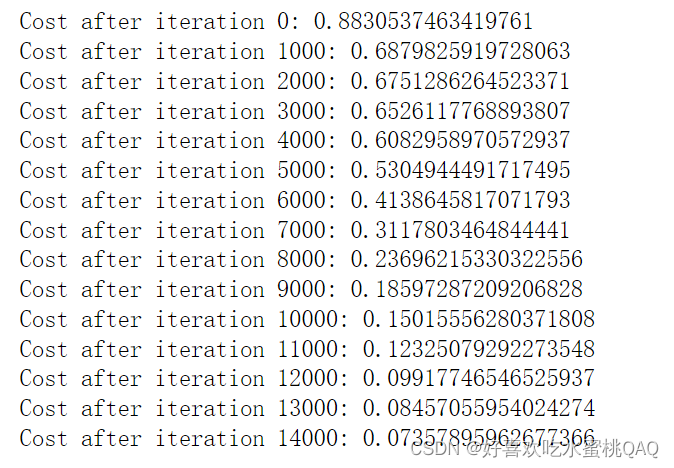
In summary:
- 当iteration为0时,cost很高。这是因为当W被初始化为比较大时,最后一个神经元中的Z较大,使得结果sigmod函数激活后得到的激活值A接近于0或者1,。如果此时模型预测错误,会产生比较大的loss
- 将参数W初始化为比较大的随机数是有效的,但是观察上图的决策边界图可以发现模型还没有完全收敛,即模型的准确率不高。换言之,将参数W初始化为比较大的随机数使得梯度下降算法变慢了
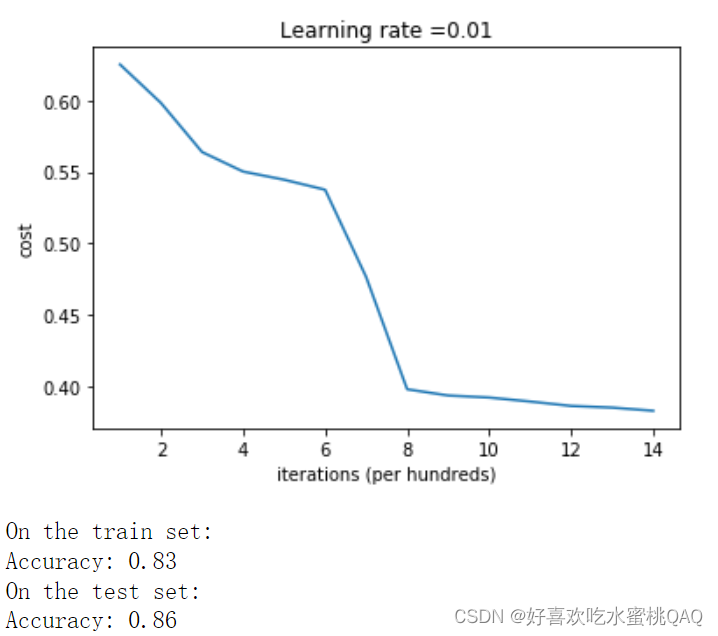
He初始化
使用He初始化方法
parameters['W' + str(i)] = np.random.randn(layers_dims[i],layers_dims[i - 1]) * np.sqrt(2.0 / layers_dims[i - 1])
parameters['b' + str(i)] = np.zeros((layers_dims[i], 1))
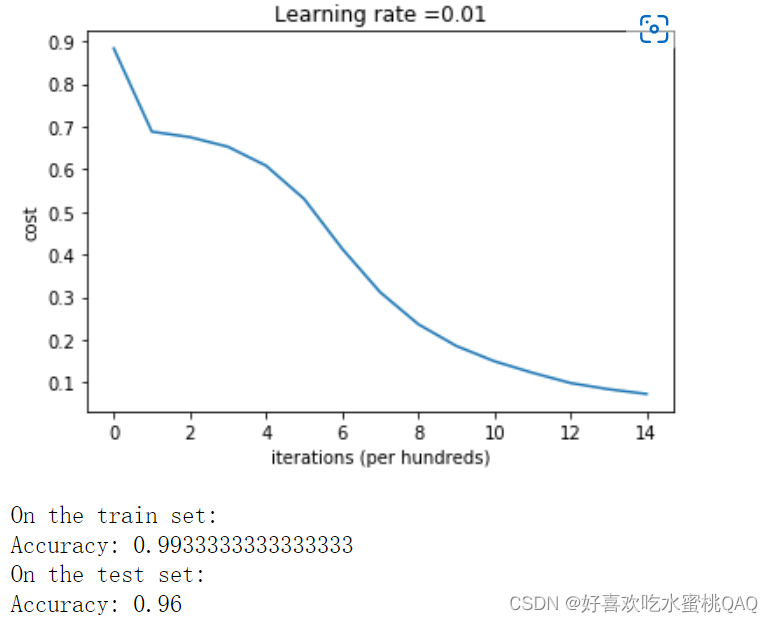
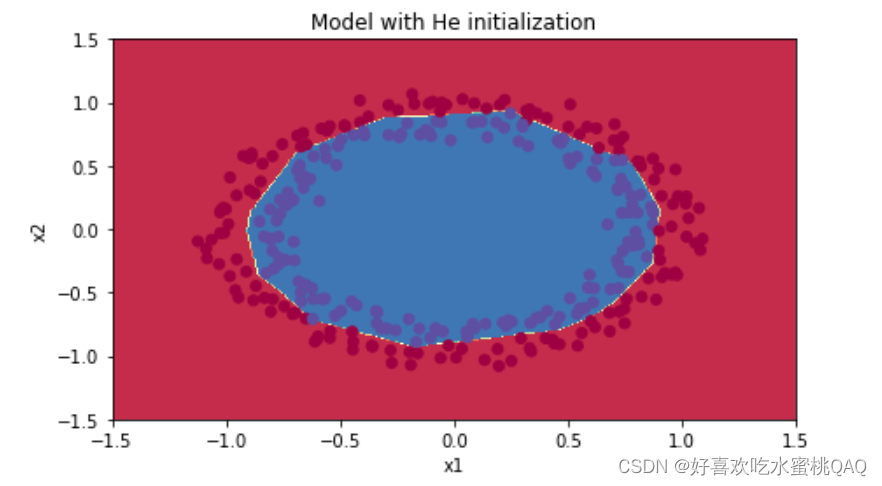
可以看到在He初始化后,经过14000次迭代模型拟合地非常好
总结
在设定相同的迭代次数和超参数后,不同的参数初始化策略的对比如下:

- 不同的初始化策略会导致不同的结果
- 随机初始化参数是为了打破神经网络的平衡并确保不同的隐藏单元可以学习不同的函数
- 通常情况下不会把参数初始化得太大
- He初始化适用于以ReLU函数为激活函数的神经网络
二、Regularization(正则化)
当模型出现过拟合即方差过大时,通常需要采取正则化来减小方差,规避过拟合。正则化常见有以下四种方法
接下来,通过一个例子来说明正则化带来的变化以及不同的正则化方法之间的差异
目标问题:
你刚刚被法国足球公司聘为人工智能专家。他们希望你推荐法国守门员踢球的位置,这样法国队的球员就可以用头击球。
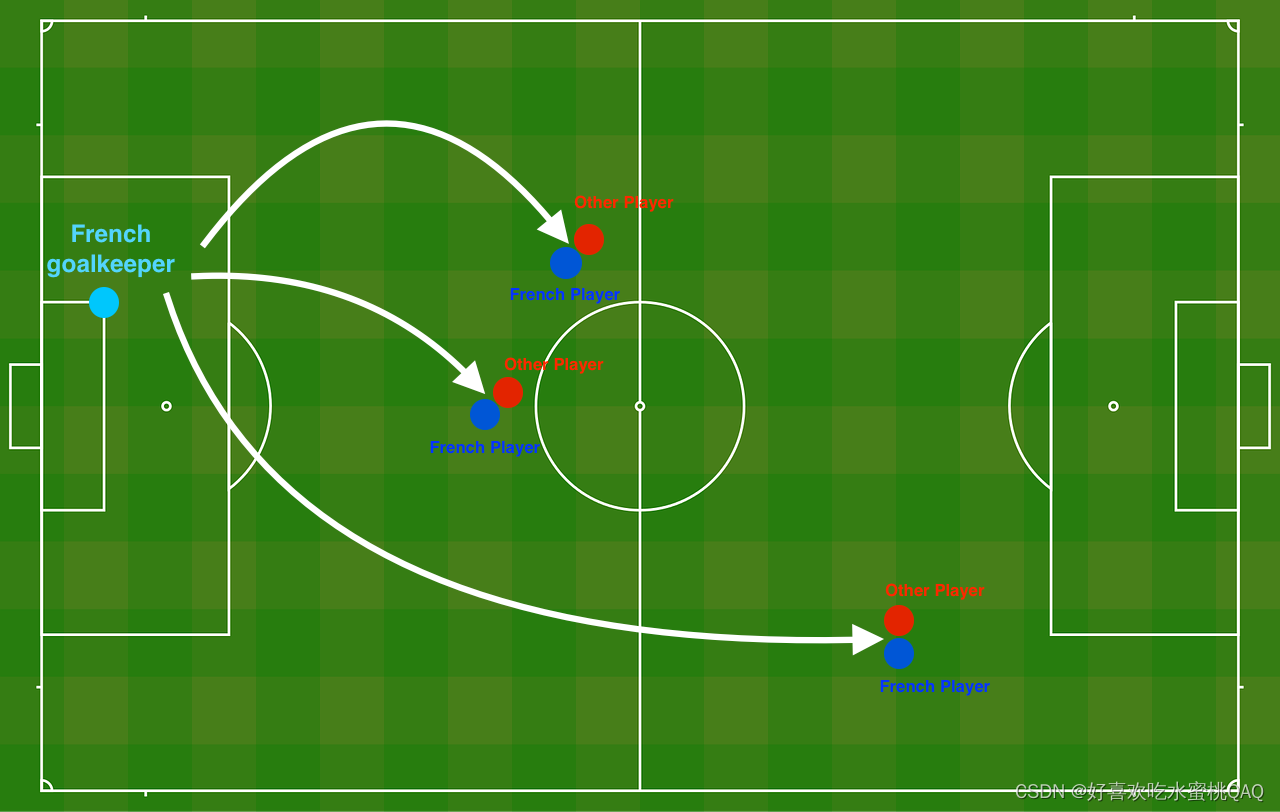
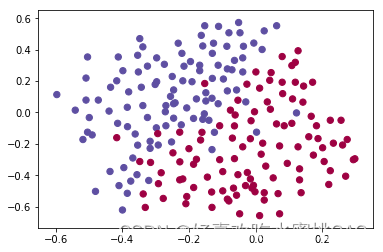
数据集说明:
每个点对应于足球场上的一个位置,在法国守门员从足球场左侧击球后,足球运动员用他的/她的头击球。
----如果圆点是蓝色的,则表示法国选手设法用头击球
----如果圆点是红色,则表示对方球员用头击球
你的目标:
使用深度学习模型找出守门员应该在球场上踢球的位置。
未使正则化
训练过程和结果:
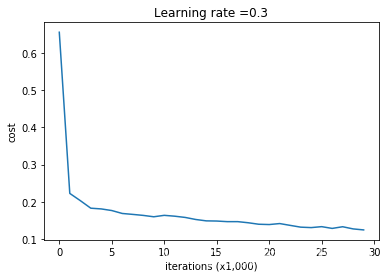
On the training set Accuracy: 0.9478672985781991
On the test set Accuracy: 0.915
决策边界图:
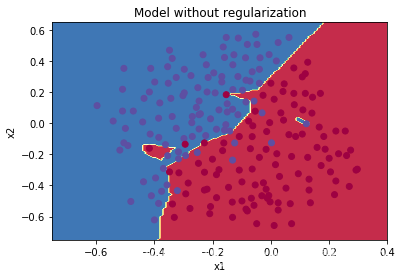
显然模型出现了过拟合的状况,来看看使用正则化之后的变化
L2正则化
避免过拟合的标准方法之一是L2正则化,其核心思想是将原本的损失函数:
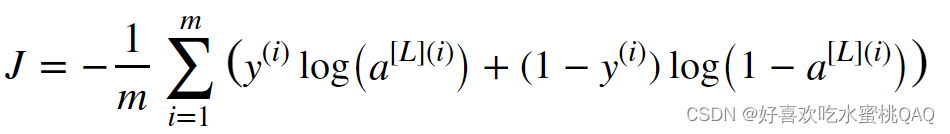
更改为:
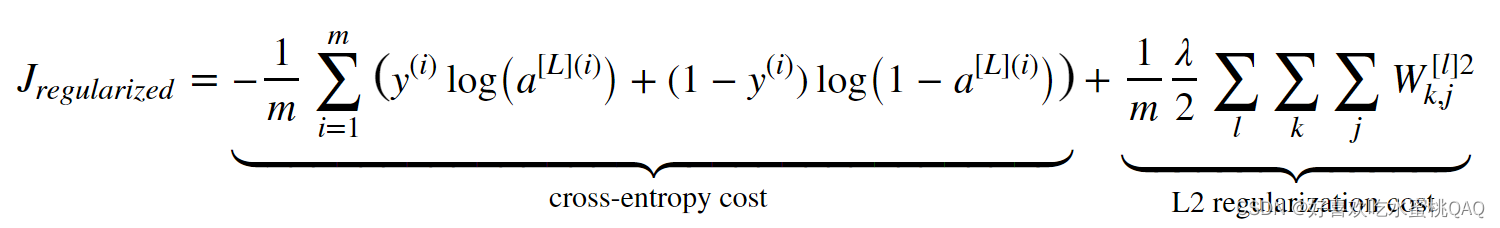
训练过程和结果:
On the train set Accuracy: 0.9383886255924171
On the test set Accuracy: 0.93
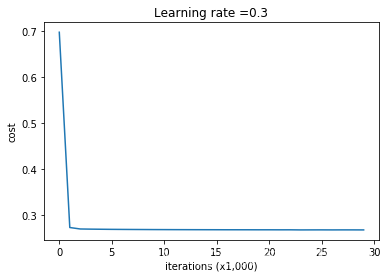
决策边界图:
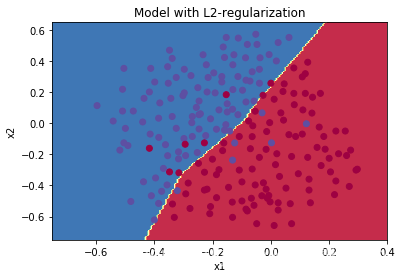
- λ是可以更改值的超参数
- 可以发现,L2正则化使得决策边界更加的“光滑”。如果λ的值大到一定程度,可能会使得决策边界过于“光滑”,导致模型欠拟合
为什么L2正则化可以起到这样的作用?
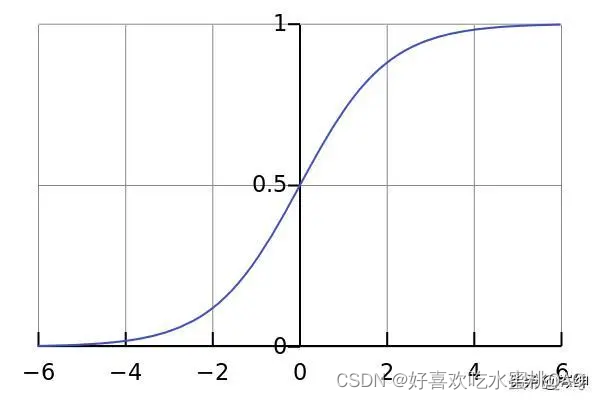
观察sigmod函数图像会发现,在x=0的附近,sigmod函数图像趋向于线性。而L2正则化在基于“具有小权重的模型比具有大权重的模型更简单”的假设下,通过惩罚成本函数中权重的平方值,来减小权重W的值。那么当选取sigmod函数为激活函数时,由于权重W的减小,每一个神经元计算得出的Z也减小,sigmod函数趋向于呈现线性。最终导致我们得到了一个更平滑的模型,在该模型中,随着输入的变化,输出的变化更慢。
things should remember:
- 对损失函数而言,加入了一个正则项
- 对计算梯度而言,需要考虑梯度中有关于权重矩阵的额外项
- 权重最终会变小(“权重衰减”)
dropout正则化(以inverted dropout为例)
droupout一种是广泛使用的、专用于神经网络的正则化方法。其主要做法是,在每一次迭代训练时,随机地关闭一些神经元,得到一个原神经网络的一个子集网络,并在此基础上训练参数。
- Drop-out on the second hidden layer.
dropout1_kiank
- Drop-out on the first and third hidden layers.
first layer: we shut down on average 40% of the neurons. third layer: we shut down on average 20% of the neurons.
dropout2_kiank
事实上,当你关闭了一些神经元,神经网络已经被改变了。dropout背后的思想是,在每一次迭代中,你训练的是整个神经网络的一个子集,因此,网络中的神经元对于来自其他神经元的影响变得不再那么敏感,因为其他神经元随时有可能被关闭。太妙了QAQ!
更具体一些的做法是,对于每一层隐藏层,定义一个与该层激活值A同型的矩阵D,其中D矩阵是一个bool型矩阵。D矩阵的作用类似于面具,即在激活值A传给下一层前,先“戴上面具”——D矩阵。
- 前向传播
D1 = np.random.rand(A1.shape[0],A1.shape[1]) # Step 1: initialize matrix D1
D1 = D1 < keep_prob # Step 2: convert entries of D1 to 0 or 1 (using keep_prob as the threshold)
A1 = np.multiply(A1,D1) # Step 3: shut down some neurons of A1
A1 = A1 / keep_prob # Step 4: scale the value of neurons that haven't been shut down
- 反向传播
dA2 = np.multiply(dA2,D2) # Step 1: Apply mask D2 to shut down the same neurons as during the forward propagation
dA2 = dA2 / keep_prob # Step 2: Scale the value of neurons that haven't been shut down
需要注意的是,keep_prob是用于是否关闭隐藏层的概率大小的参数。在将A传给下一隐藏层之前,需要将A再除以keep_prob(这是inverted dropout的做法),以此确保A的期望值不变,反向传播同理。
训练过程和结果:
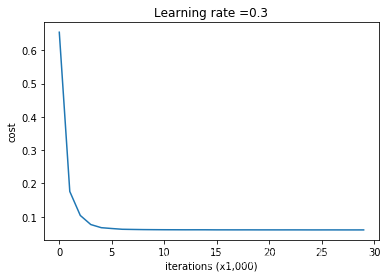
On the train set Accuracy: 0.9289099526066351
On the test set Accuracy: 0.95
决策边界图:
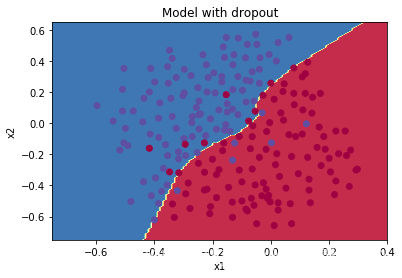
Note:
- 常见的错误是在训练模型和预测时都使用了dropout。注意dropout只有在训练时才会使用。
- 常见深度学习框架如tensorflow, PaddlePaddle, keras 或者 caffe都会有对应dropout的实现。
things should remember:
- Dropout是一项正则化技术
- 只在训练模型时使用dropout
- 在前向传播和反向传播都需要使用dropout
- 在戴上面具“矩阵D”后,需要将激活值除以keep_prob以确保激活值的期望不变
- 关于以上三种模型的对比如下表:

Conclusions:
- 正则化可以有效避免过拟合
- 正则化使得参数W更小
- L2正则化和dropout正则化都十分有效
数据扩增
简单解释就是在原有数据集基础上,使用各种方法生成新的数据。
例如在训练图像分类器时:
-
扭曲图像

-
水平翻转
-
旋转、裁剪

总之想尽办法获取更多的有效数据来训练模型通常是有效的。
Early stopping
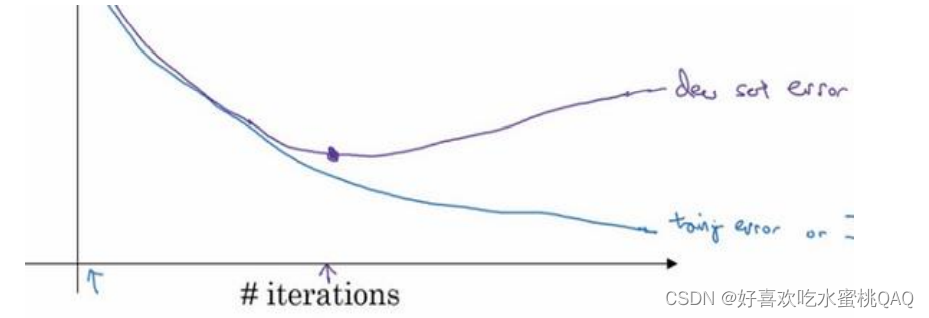
Early stopping简而言之就是在测试集的误差到达最低点时停止训练模型,即“及时止损”。
但是Early stopping的缺点是明显。训练模型时,我们通常需要关注两个问题:
- 如何降低成本函数
- 在降低成本函数的同时,防止过拟合,即减少方差
也就是说,我们的目标有两个,即“低偏差,低方差”。通常情况下,这两个目标独立考虑、处理时问题比较清晰。而Early stopping的做法是,在降低成本函数的同时又希望能够避免过拟合,并没有采取不同的方式来实现这两个目标,使得问题变得复杂化了。
总之我认为该方法能够奏效的情况极少o(╯□╰)o
















 1195
1195











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











