树与二叉树
一,计算机中的树形结构
根节点:最顶层的节点就是根结点,它是整棵树的源头
叶子节点:在树下端的节点,就是其子节点个数为0的节点
节点的度:指定节点有几个分叉就说这个节点的度是几(叶子节点的度为零)
树的度:只看根结点,树的度等价于根节点的度
-
出度:该节点指向多少个节点
-
入度:多少个节点指向该节点
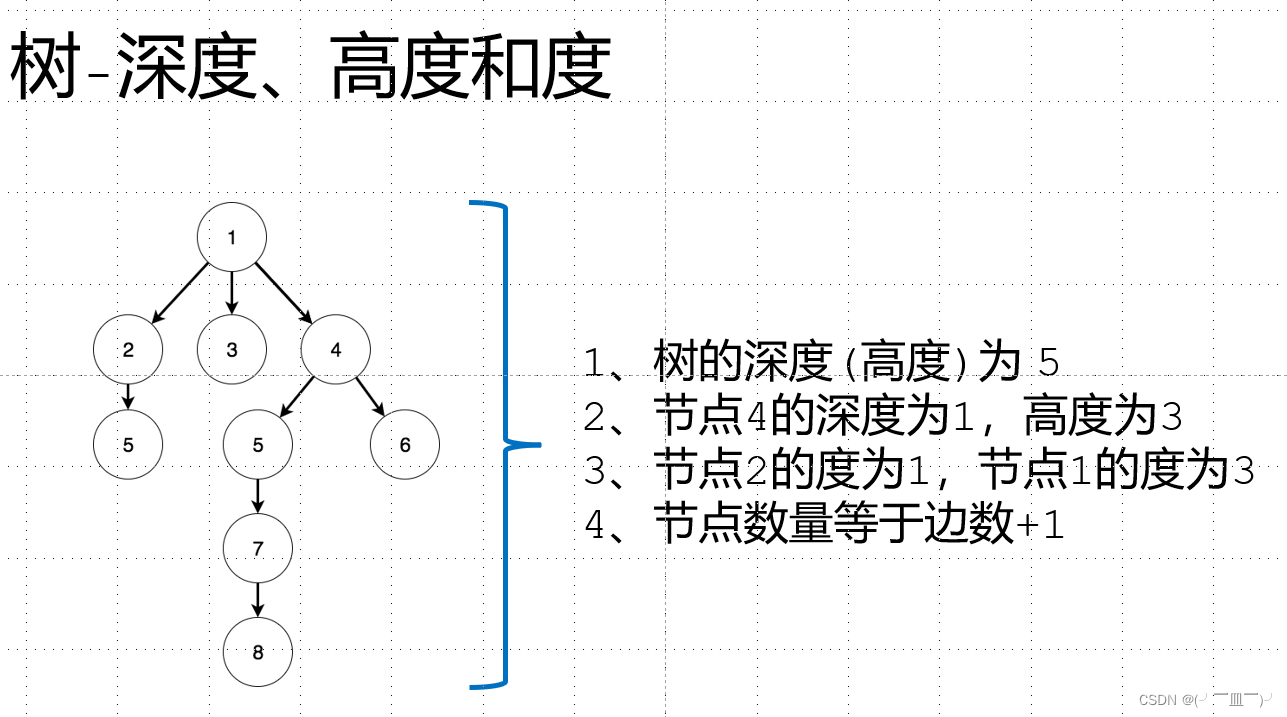
节点高度:指从这个节点到叶子节点的距离(一共经历了几个节点)
节点深度:指从这个节点到根节点的距离(一共经历了几个节点)
树的高度:指所有节点高度的最大值
树的深度:指所有节点深度的最大值
节点的层:从根节点开始,假设根节点为第1层,根节点的子节点为第2层,依此类推
树的节点代表
【
集合
】
,树的边代表
【
关系
】
根节点代表全集
二,广度优先遍历与深度优先遍历
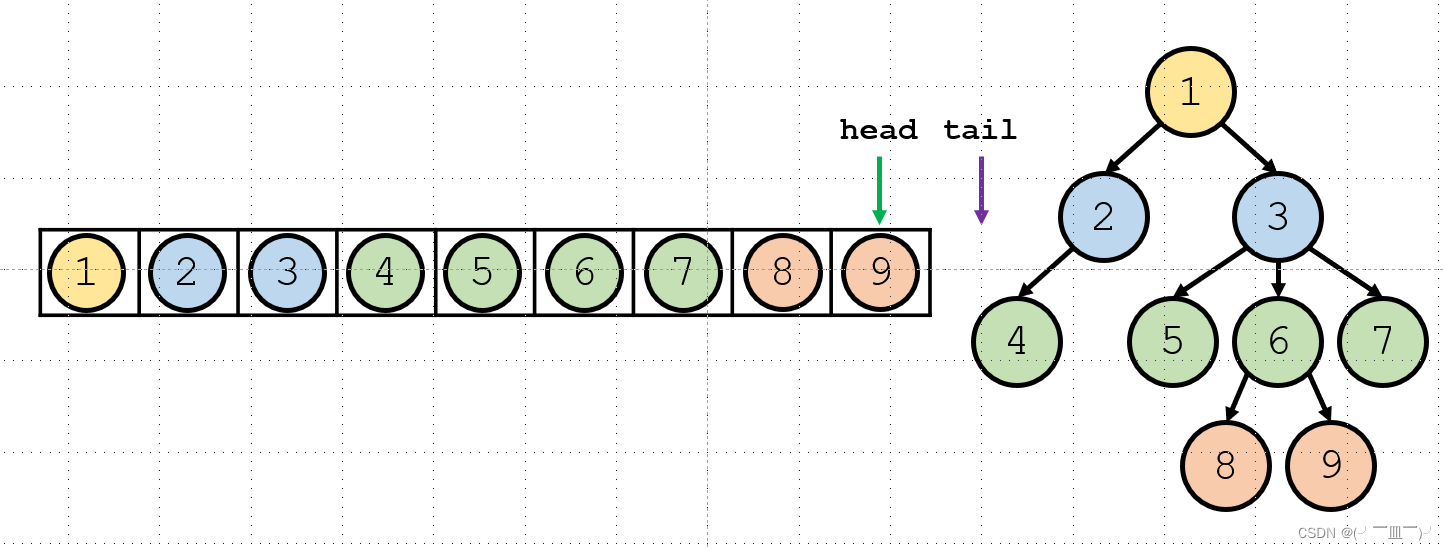
1.广度优先遍历(层序遍历)
使用的数据结构:队列
处理过程:依次压入队首元素的子节点,当队首元素再也没有子节点时,弹出队首元素,以此类推。
2.深度优先遍历
使用的数据结构:栈
处理过程:不断压入栈元素的子节点,当再无子节点可压时,弹出栈顶元素。
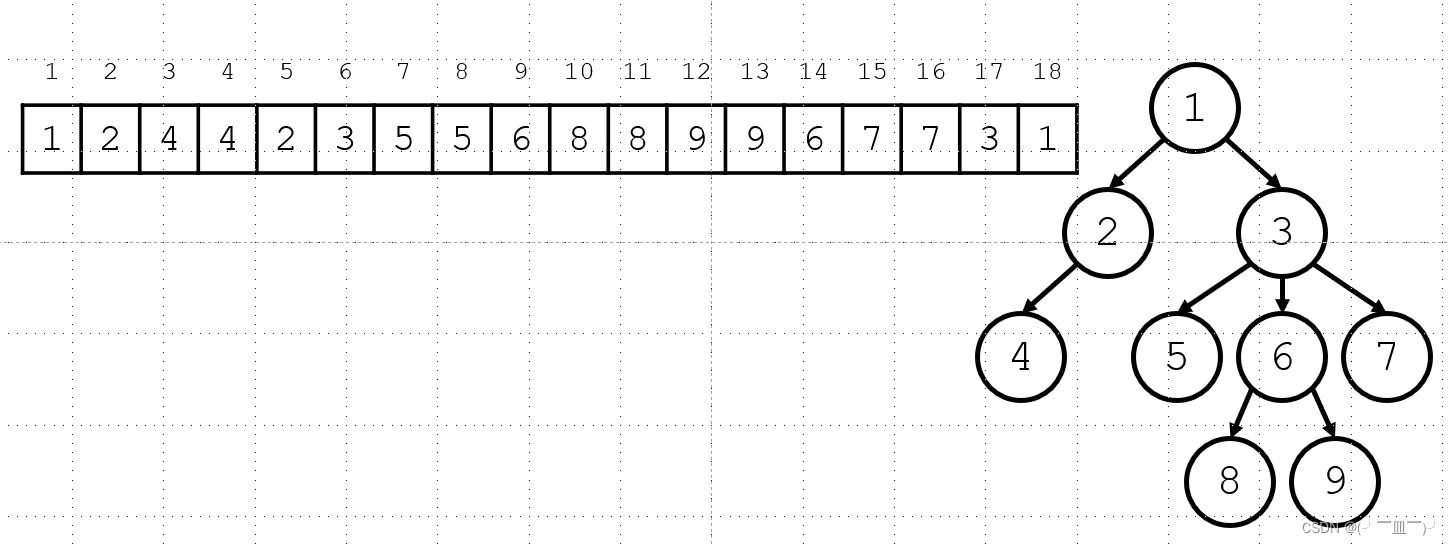
压栈弹出的时间戳(判断节点之间的父子关系)
3与3之间包含5,6,8,9,7表示3的子节点是5,6,7,8,9。
#include
<cstdio>
#include
<cstdlib>
#include
<ctime>
typedef
struct
Node
{
int
key;
Node
* lchild, *rchild;
}
Node
;
Node
* getNewNode(
int
key
) {
Node
* p = (
Node
*)malloc(
sizeof
(
Node
));
p->key =
key
;
p->lchild = p->rchild =
NULL
;
return
p;
}
Node
*insert(
Node
*
root
,
int
key
) {
if
(
root
==
NULL
) {
return
getNewNode(
key
);
}
if
(rand() % 2)
root
->lchild = insert(
root
->lchild,
key
);
else
root
->rchild = insert(
root
->rchild,
key
);
return
root
;
}
void
clear(
Node
*
root
) {
if
(
root
==
NULL
)
return
;
clear(
root
->lchild);
clear(
root
->rchild);
free(
root
);
}
#define
MAX_NODE
10
Node
*queue[
MAX_NODE
+ 5];
int
head, tail;
//广度优先遍历
void
bfs(
Node
*
root
) {
head = tail = 0;
queue[tail++] =
root
;
while
(head < tail) {
Node
* node = queue[head];
printf(
"\nnode:%d"
, node->key);
if
(node->lchild){
queue[tail++] = node->lchild;
printf(
"\t%d->%d(left)\n"
, node->key, node->lchild->key);
}
if
(node->rchild) {
queue[tail++] = node->rchild;
printf(
"\t%d->%d(right)\n"
, node->key, node->rchild->key);
}
head++;
}
cout
<<
endl;
}
int
tot = 0;
//深度优先遍历
void
dfs(
Node
*
root
) {
if
(
root
==
NULL
)
return
;
int
start, end;
tot++;
start = tot;
if
(
root
->lchild) dfs(
root
->lchild);
if
(
root
->rchild) dfs(
root
->rchild);
tot++;
end = tot;
printf(
"%d:[%d ,%d]\n"
,
root
->key, start, end);
return
;
}
int
main() {
srand(time(0));
Node
* root =
NULL
;
for
(
int
i = 0; i <
MAX_NODE
; i++) {
root = insert(root, rand() % 100);
}
bfs(root);
dfs(root);
return
0;
}
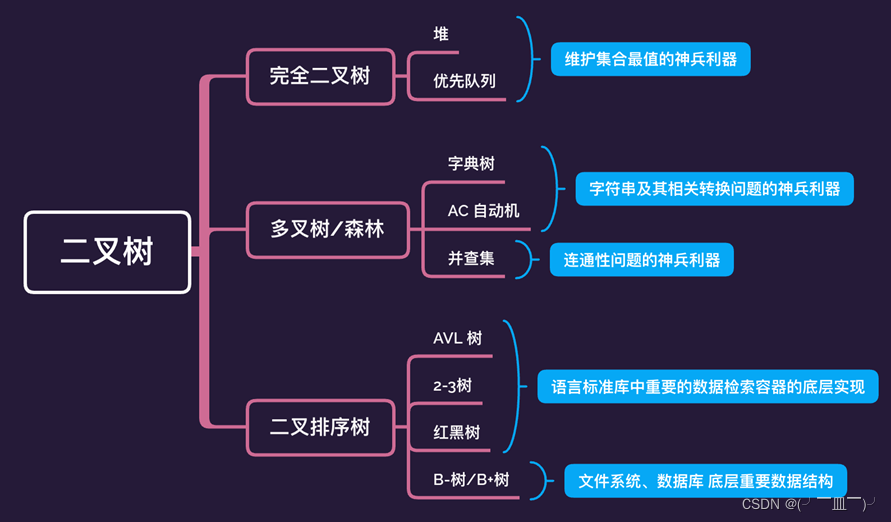
三,二叉树
1.结构:
每个节点度最多为 2
度为0的节点比度为2的节点多1个
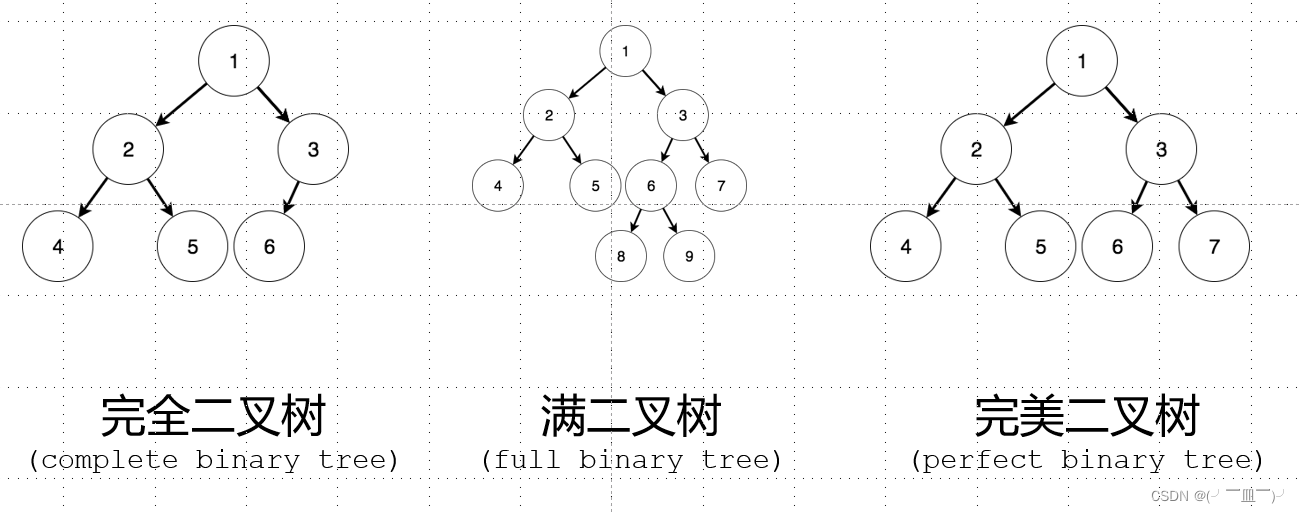
2.特殊类型
完全二叉树:
除了最后一层之外的其他每一层都被完全填充,并且所有结点都保持向左对齐
满二叉树:没有度为1的节点
完美二叉树:
除了叶子结点之外的每一个结点都有两个孩子,每一层都被完全填充
3.完全二叉树:
4.二叉树的作用
作用一:理解高级数据结构的基础
作用二:
练习递归技巧的最佳选择
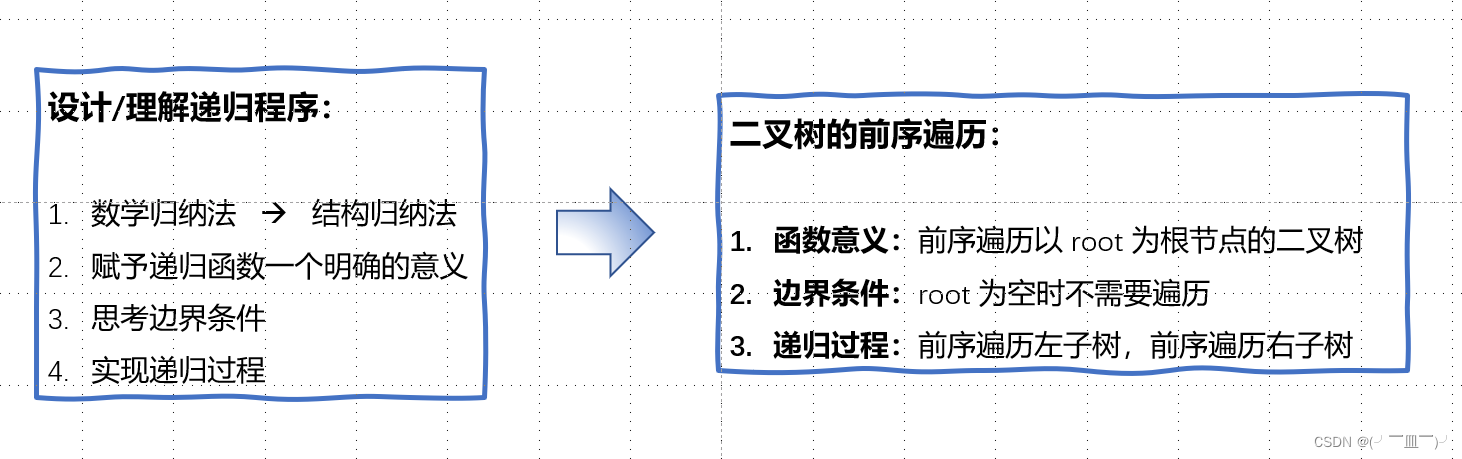
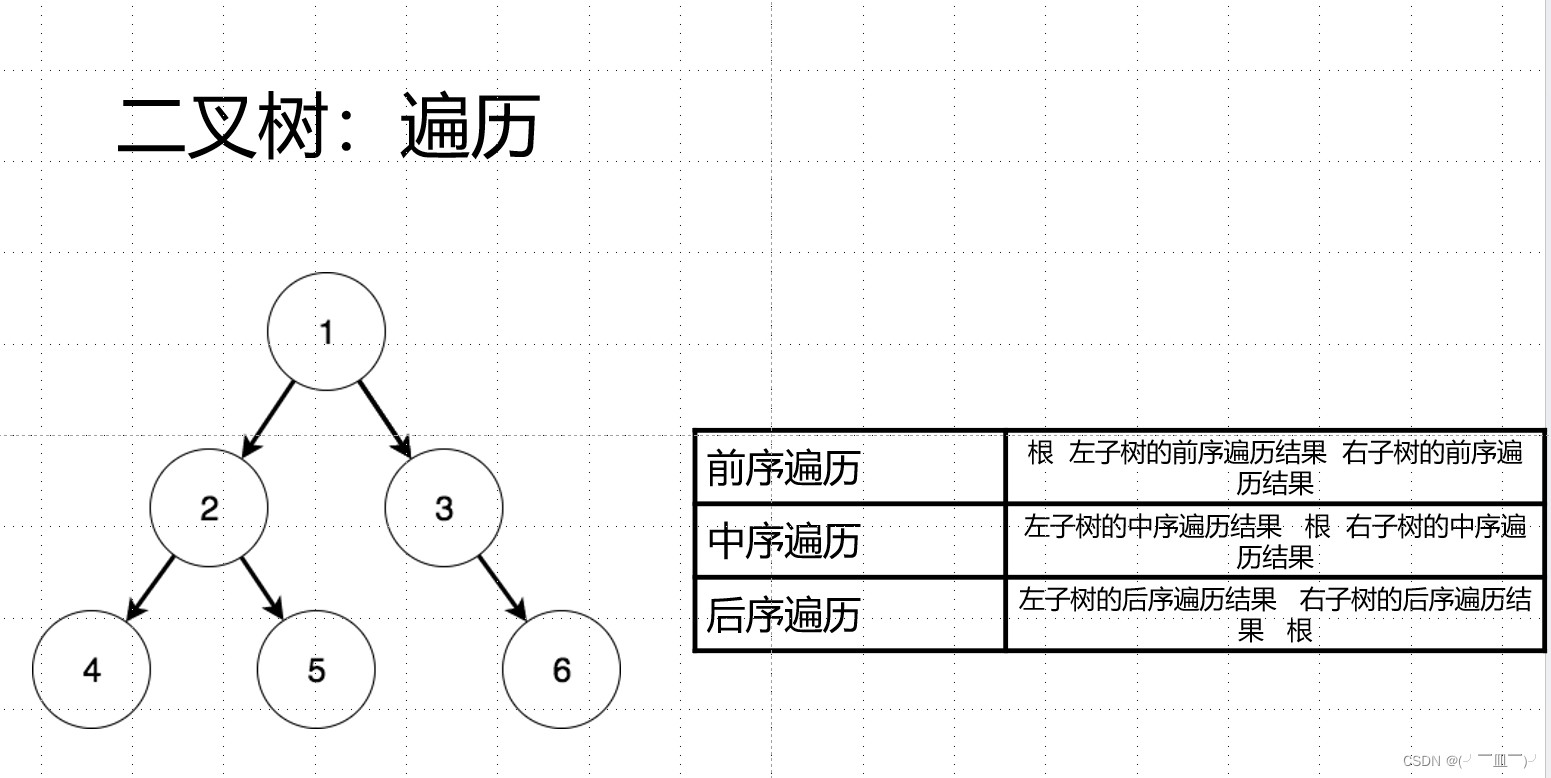
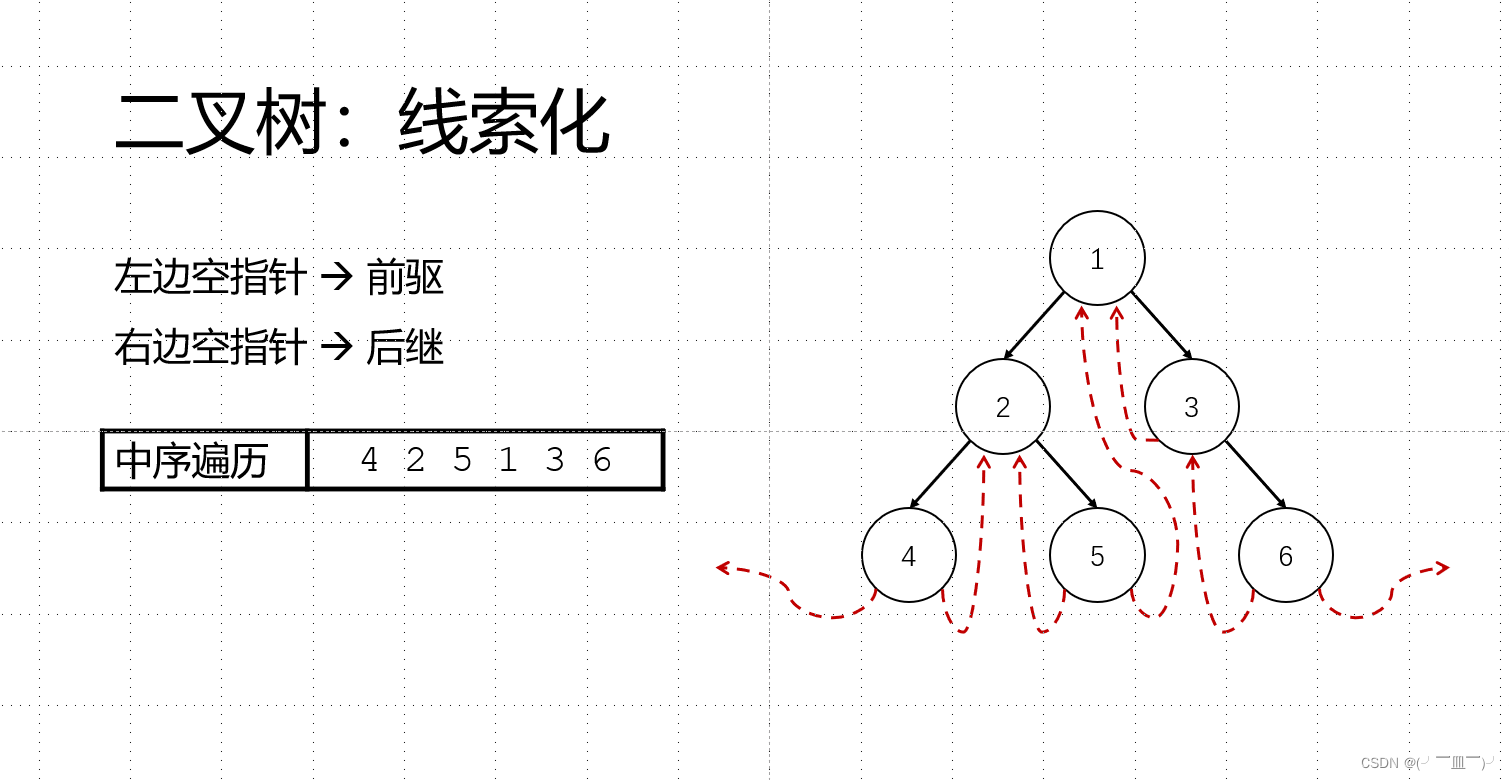
四,二叉树:遍历与线索化
前序遍历:1 245 36
中序遍历:425 1 36
后序遍历:452 63 1
作用:序列化-->传输数据结构
前序遍历+中序遍历 可恢复原本的数据结构
后序遍历+中序遍历 可恢复原本的数据结构
后序遍历+前序遍历 不可恢复原本的数据结构(难以确定左右子树的数量)
作用:让二叉树表现的想链表,不用借助递归程序,让遍历个高效。
例子:
#include
<cstdio>
#include
<cstdlib>
#include
<ctime>
typedef
struct
Node
{
int
key;
int
ltag, rtag;
//1:thread,0:edge;
struct
Node
*lchild, *rchild;
}
Node
;
Node
* getNewNode(
int
key
) {
Node
* p = (
Node
*)malloc(
sizeof
(
Node
));
p->key =
key
;
p->ltag = p->rtag = 0;
p->lchild =
NULL
;
p->rchild =
NULL
;
return
p;
}
Node
* insert(
Node
*
root
,
int
key
) {
if
(
root
==
NULL
)
return
getNewNode(
key
);
if
(rand() % 2)
root
->lchild = insert(
root
->lchild,
key
);
else
root
->rchild = insert(
root
->rchild,
key
);
return
root
;
}
//前序遍历
void
pre_order(
Node
*
root
) {
if
(
root
==
NULL
)
return
;
printf(
"%d "
,
root
->key);
if
(
root
->ltag==0)pre_order(
root
->lchild);
if
(
root
->rtag==0)pre_order(
root
->rchild);
return
;
}
//中序遍历
void
mid_order(
Node
*
root
) {
if
(
root
==
NULL
)
return
;
if
(
root
->ltag==0)mid_order(
root
->lchild);
printf(
"%d "
,
root
->key);
if
(
root
->rtag==0)mid_order(
root
->rchild);
return
;
}
//后序遍历
void
post_order(
Node
*
root
) {
if
(
root
==
NULL
)
return
;
if
(
root
->ltag==0)post_order(
root
->lchild);
if
(
root
->rtag==0)post_order(
root
->rchild);
printf(
"%d "
,
root
->key);
return
;
}
void
clear(
Node
*
root
) {
if
(
root
==
NULL
)
return
;
if
(
root
->ltag==0)clear(
root
->lchild);
if
(
root
->rtag==0)clear(
root
->rchild);
free(
root
);
return
;
}
//将根节点线索化--中序遍历
Node
* pre_node =
NULL
,*mid_order_root=
NULL
;
void
__build_mid_order_thread(
Node
*
root
) {
if
(
root
==
NULL
)
return
;
if
(
root
->ltag == 0)__build_mid_order_thread(
root
->lchild);
if
(mid_order_root ==
NULL
) mid_order_root =
root
;
if
(
root
->lchild ==
NULL
) {
root
->lchild = pre_node;
root
->ltag = 1;
}
if
(pre_node && pre_node->rchild ==
NULL
) {
pre_node->rchild=
root
;
pre_node->rtag = 1;
}
pre_node =
root
;
if
(
root
->rtag == 0)__build_mid_order_thread(
root
->rchild);
return
;
}
//封装
void
build_mid_order_thread(
Node
*
root
) {
__build_mid_order_thread(
root
);
pre_node->rchild =
NULL
;
pre_node->rtag = 1;
return
;
}
//寻找后继
Node
* getNext(
Node
*
root
) {
if
(
root
->rtag == 1)
return
root
->rchild;
root
=
root
->rchild;
while
(
root
->ltag == 0)
root
=
root
->lchild;
return
root
;
}
int
main() {
srand(time(0));
Node
*root =
NULL
;
#define
MAX_NODE
10
for
(
int
i = 0; i <
MAX_NODE
; i++) {
root = insert(root, rand() % 100);
}
pre_node =
NULL
;
mid_order_root=
NULL
;
build_mid_order_thread(root);
pre_order(root); printf(
"\n"
);
mid_order(root); printf(
"\n"
);
post_order(root); printf(
"\n"
);
//like linklist
Node
* node = mid_order_root;
while
(node) {
printf(
"%d "
, node->key);
node = getNext(node);
}
clear(root);
return
0;
}
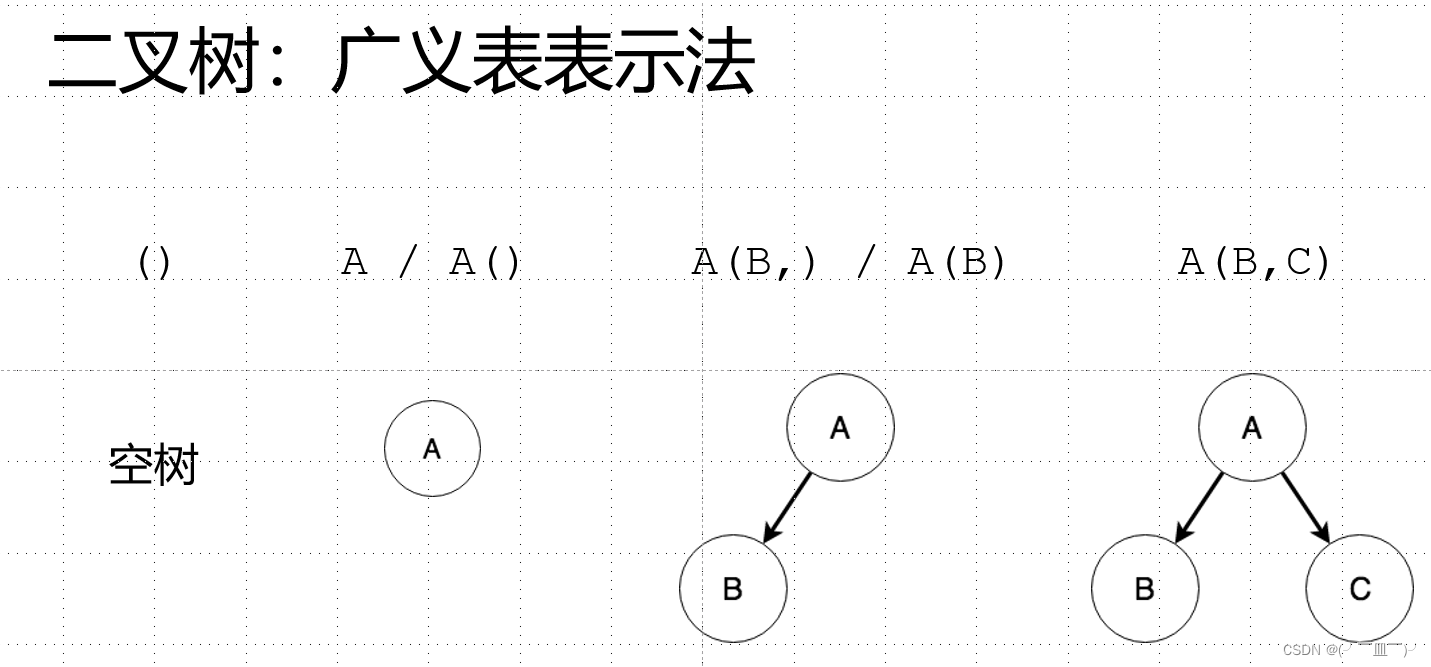
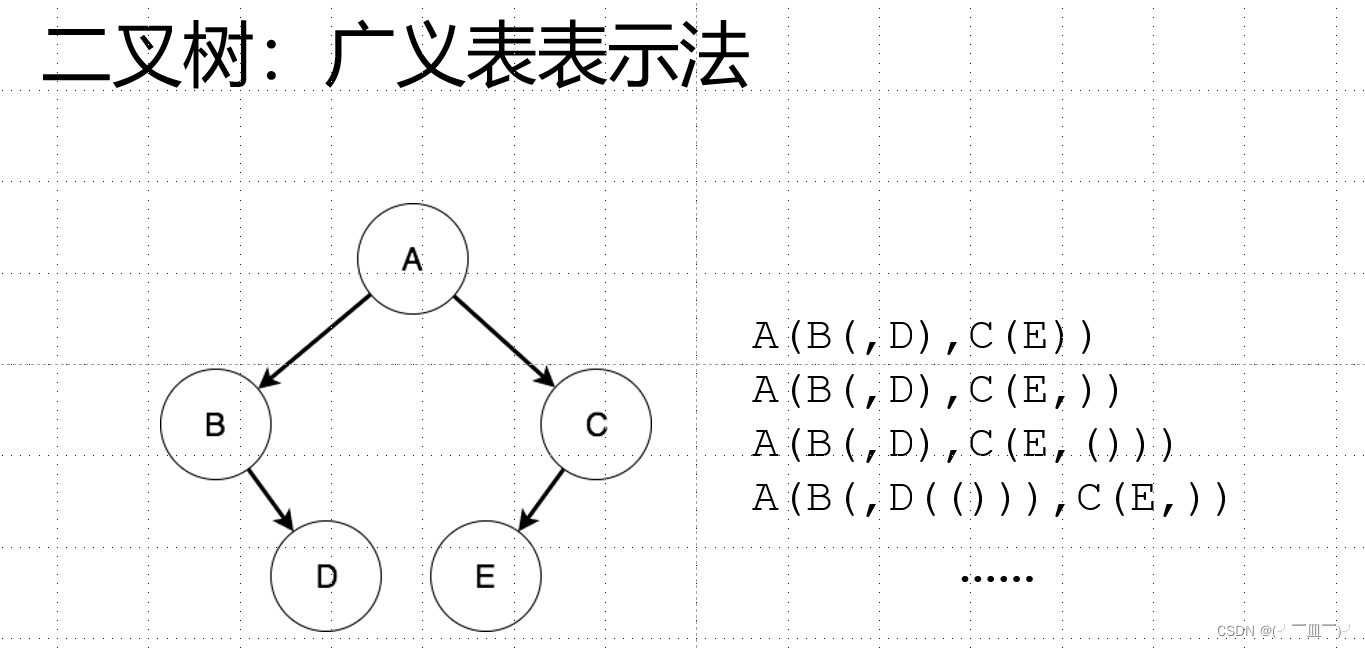
五,广义表:
二叉树转广义表
#define
KEY
(n) (n?n->key:-1)
typedef
struct
Node
{
int
key;
Node
* lchild, * rchild;
}
Node
;
//新建子节点
Node
* getNewNode(
int
key
) {
Node
* p = (
Node
*)malloc(
sizeof
(
Node
));
p->key =
key
;
p->lchild = p->rchild =
NULL
;
return
p;
}
//随机插入
Node
* insert(
Node
*
root
,
int
key
) {
if
(
root
==
NULL
)
return
getNewNode(
key
);
if
(rand() % 2)
root
->lchild = insert(
root
->lchild,
key
);
else
root
->rchild = insert(
root
->rchild,
key
);
return
root
;
}
//生成随机二叉树
Node
* getRandomBinaryTree(
int
n
) {
Node
* root =
NULL
;
for
(
int
i = 0; i <
n
; i++) {
root = insert(root, rand() % 100);
}
return
root;
}
//清除二叉树
void
clear(
Node
*
root
) {
if
(
root
==
NULL
)
return
;
clear(
root
->lchild);
clear(
root
->rchild);
free(
root
);
return
;
}
//二叉树转广义表
char
buff[1000];
int
len = 0;
void
__serialize(
Node
*
root
) {
if
(
root
==
NULL
)
return
;
//root
len+=snprintf(buff + len, 100,
"%d"
,
root
->key);//返回打印的字节数
if
(
root
->lchild ==
NULL
&&
root
->rchild ==
NULL
)
return
;
len += snprintf(buff + len ,100 ,
"("
);
__serialize(
root
->lchild);
if
(
root
->rchild ){
len += snprintf(buff + len, 100,
","
);
__serialize(
root
->rchild);
}
len += snprintf(buff + len, 100,
")"
);
return
;
}
void
serialize(
Node
*
root
) {
memset(buff, 0,
sizeof
(buff));
len = 0;
__serialize(
root
);
return
;
}
void
print(
Node
*
node
) {
printf(
"%d(%d, %d)\n"
,
KEY
(
node
),
KEY
(
node
->lchild),
KEY
(
node
->rchild));
return
;
}
void
output(
Node
*
root
) {
if
(
root
==
NULL
)
return
;
print(
root
);
output(
root
->lchild);
output(
root
->rchild);
return
;
}
int
main() {
srand(time(0));
#define
MAX_NODE
10
Node
*root = getRandomBinaryTree(
MAX_NODE
);
serialize(root);
output(root);
printf(
"Buff[]:%s\n"
, buff);
return
0;
}
广义表转二叉树
Node
* deserialize(
char
*
buff
,
int
n
) {
//设置根节点
Node
* root =
NULL
, * p =
NULL
;
//设置栈,储存节点
Node
** s = (
Node
**)malloc(
sizeof
(
Node
*) *
MAX_NODE
);
int
top = -1, flag = 1, scode = 0;
for
(
int
i = 0;
buff
[i]; i++) {
if
(
buff
[i] <=
'9'
&&
buff
[i] >=
'0'
) {
scode = 1;
}
else
if
(
buff
[i] ==
'('
) {
scode = 2;
}
else
if
(
buff
[i] ==
','
) {
scode = 3;
}
else
if
(
buff
[i] ==
')'
) {
scode = 4;
}
switch
(scode) {
case
1: {
int
key=0;
//读数
while
(
buff
[i] >=
'0'
&&
buff
[i] <=
'9'
) {
key = key * 10 + (
buff
[i] -
'0'
);
i += 1;
}
//生成二叉树
p = getNewNode(key);
if
(flag == 0 && top >= 0) {
s[top]->rchild = p;
}
if
(flag == 1 && top >= 0) {
s[top]->lchild = p;
}
//避免重复++
i -= 1;
break
;
}
case
2: {
//入栈
s[++top] = p;
flag = 1;
//表示为左子树
break
;
}
case
3: {
flag = 0;
//表示为右子树
break
;
}
case
4: {
//取根节点
if
(top == 0) root = s[top];
//出栈
top -= 1;
break
;
}
}
}
free(s);
return
root;
}
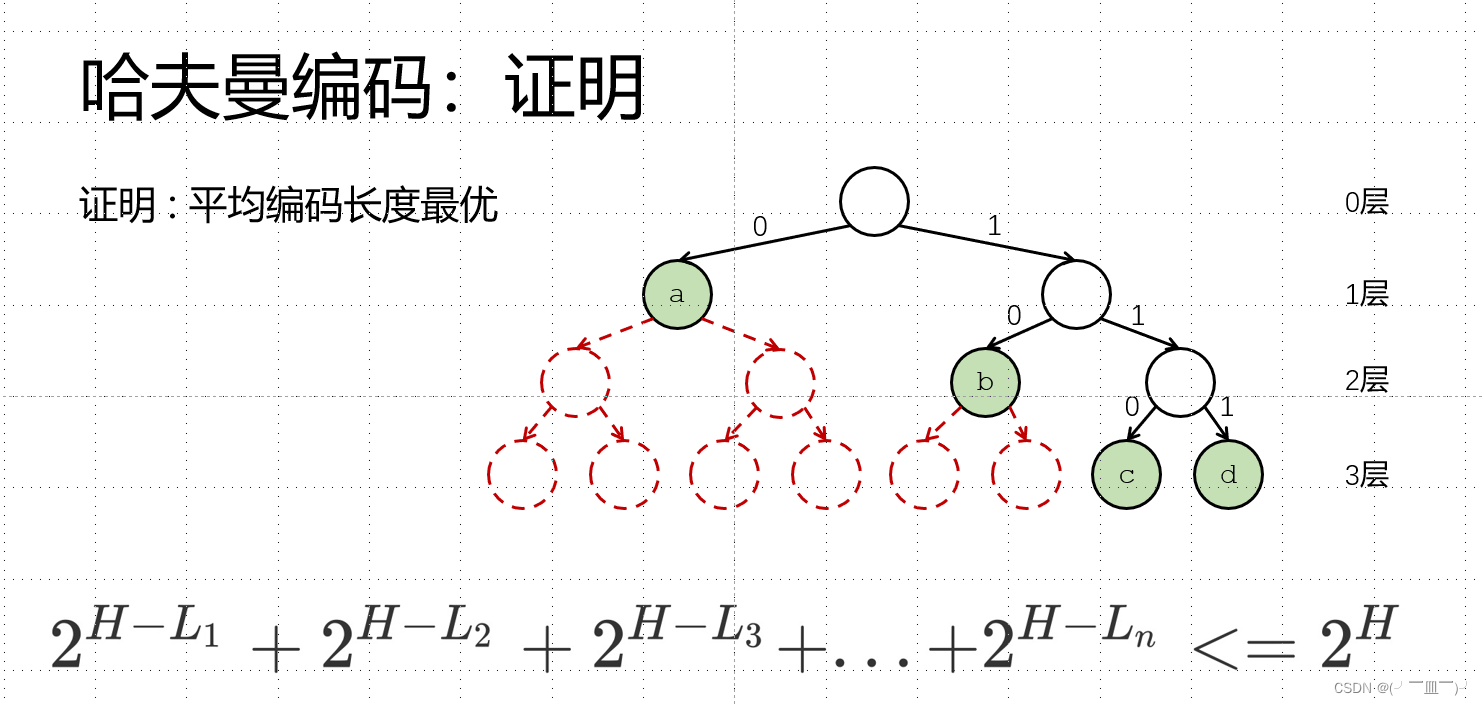
六,哈夫曼编码
定长编码:对于每一个字符的编码长度都一样
变长编码:由于不同字符出现概率不同,每一个字符的编码长度不同。
编码前缀不能包含另一个编码(任何两个字符不能构成结构关系)
H:表示第几层
L:表示第i个字符在二叉树的第几层
代码实现:
#include
<cstdio>
#include
<cstdlib>
#include
<cstring>
#include
<iostream>
using
namespace
std;
typedef
struct
Node
{
char
ch;
int
freq;
struct
Node
* lchild, * rchild;
}
Node
;
Node
* getNewNode(
int
freq
,
char
ch
) {
Node
* p = (
Node
*)malloc(
sizeof
(
Node
));
p->ch =
ch
;
p->freq =
freq
;
p->lchild = p->rchild =
NULL
;
return
p;
}
//交换min_node与未处理node_arr的末尾位置
void
swap_node(
Node
**
node_arr
,
int
i
,
int
j
) {
Node
* temp =
node_arr
[
i
];
node_arr
[
i
] =
node_arr
[
j
];
node_arr
[
j
] = temp;
return
;
}
//找出node_arr中未处理部分的freq
int
find_min_node(
Node
**
node_arr
,
int
n
) {
int
ind = 0;
for
(
int
j = 1; j <=
n
; j++) {
if
(
node_arr
[ind]->freq >
node_arr
[j]->freq) ind = j;
}
return
ind;
}
Node
* buildHaffmanTree(
Node
**
node_arr
,
int
n
) {
for
(
int
i = 1; i <
n
; i++) {
// find two node
int
ind1 = find_min_node(
node_arr
,
n
- i);
swap_node(
node_arr
, ind1,
n
- i);
int
ind2 = find_min_node(
node_arr
,
n
- i - 1);
swap_node(
node_arr
, ind2,
n
- i - 1);
// merge two node
int
freq =
node_arr
[
n
- i]->freq +
node_arr
[
n
- i - 1]->freq;
Node
* node = getNewNode(freq, 0);
node->lchild =
node_arr
[
n
- i - 1];
node->rchild =
node_arr
[
n
- i];
//合并后的节点占原来的倒数第二个位置
node_arr
[
n
- i - 1] = node;
}
return
node_arr
[0];
}
void
clear(
Node
*
root
) {
if
(
root
==
NULL
)
return
;
clear(
root
->lchild);
clear(
root
->rchild);
free(
root
);
return
;
}
#define
MAX_CHAR_NUM
128
char
* char_code[
MAX_CHAR_NUM
] = { 0 };
void
extractHaffmanCode(
Node
*
root
,
char
buff
[],
int
k
) {
buff
[
k
] = 0;
if
(
root
->lchild ==
NULL
&&
root
->rchild ==
NULL
) {
//strdup()主要是拷贝字符串s的一个副本,由函数返回值返回,这个副本有自己的内存空间,和s不相干。
//功能:复制字符串s
//说明:返回指向被复制的字符串的指针,所需空间由malloc()分配且可以由free()释放。
char_code[
root
->ch] = strdup(
buff
);
return
;
}
buff
[
k
] =
'0'
;
extractHaffmanCode(
root
->lchild,
buff
,
k
+ 1);
buff
[
k
] =
'1'
;
extractHaffmanCode(
root
->rchild,
buff
,
k
+ 1);
return
;
}
int
main() {
char
s[10];
int
n, freq;
scanf(
"%d"
, &n);
Node
** node_arr = (
Node
**)malloc(
sizeof
(
Node
*) * n);
for
(
int
i = 0; i < n; i++) {
scanf(
"%s%d"
, s, &freq);
node_arr[i] = getNewNode(freq, s[0]);
}
Node
* root = buildHaffmanTree(node_arr, n);
char
buff[1000];
extractHaffmanCode(root, buff, 0);
for
(
int
i = 0; i <
MAX_CHAR_NUM
; i++) {
if
(char_code[i] ==
NULL
)
continue
;
printf(
"%c : %s\n"
, i, char_code[i]);
}
clear(root);
return
0;
}
七,哈夫曼编码实现任意文件的无损压缩与解压
1 哈夫曼编码实现任意文件的压缩
1.1实验要求
1)利用哈夫曼编码实现任意文件的无损压缩。
2)利用mian函数的参数实现在终端的无损压缩操作。
1.2代码设计
1)压缩操作的封装,umap_freq字节频率哈希表,umap_haffman哈夫曼编码表,node_arr节点数组,buildFreqMap构建字节频率哈希表,buildHaffmanTree构建哈夫曼树,extractHaffmanCode提取哈夫曼编码,createCompressFile创建压缩文件。

2)哈夫曼树节点的设计

ch是字节,freq是字节频率。
3)节点的新建和哈夫曼树的删除 
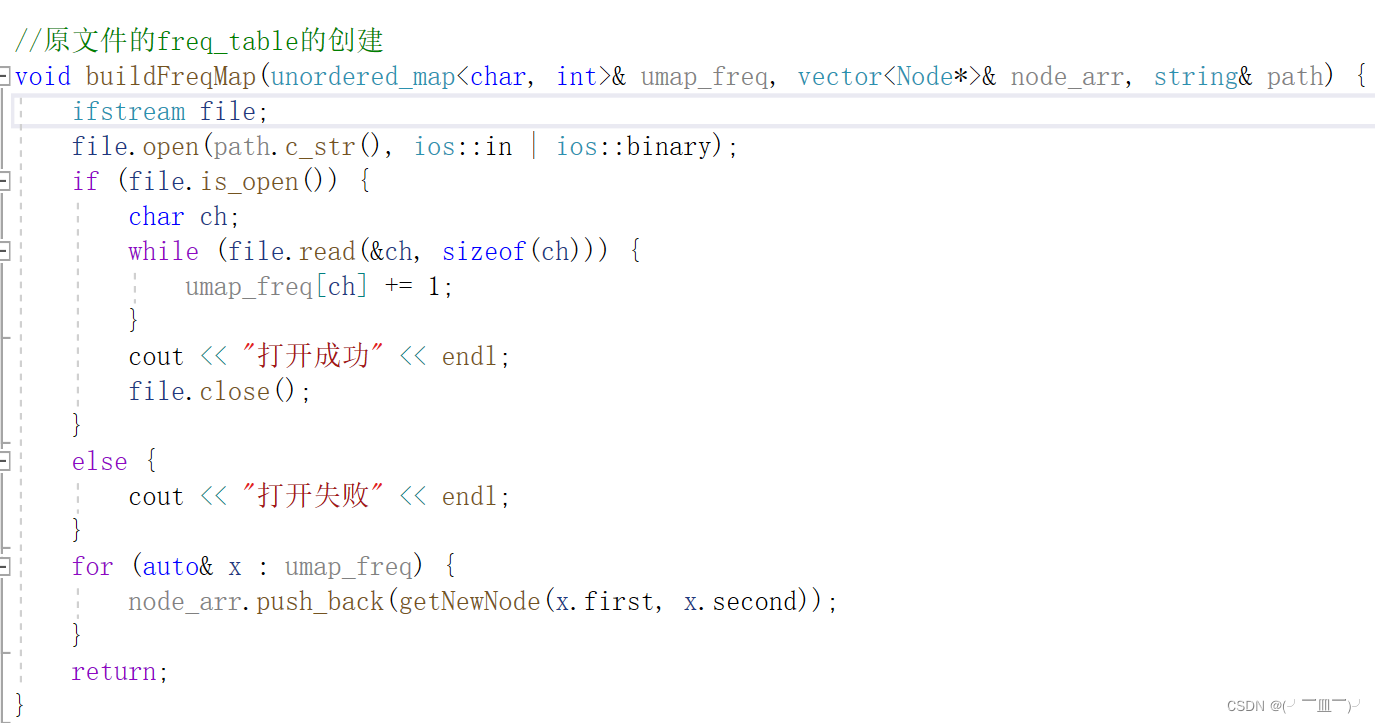
4)原文件二进制打开后,读入字符,计算频率,构建字节频率的哈希表,并将创建的节点地址存入node_arr中,
5)寻找node_arr中频率最小的节点,为后面哈夫曼树的构建做准备

6)每次寻找node_arr中频率最小的节点,并将它与node_arr的最后一位交换,再寻找node_arr中频率第二小的节点并与node_arr的倒数第二位交换,然后在倒数第二位存入,两个最小节点的合成节点,一次建立循环,node_arr[0]存入的便是哈夫曼树的根节点。

7)读取哈夫曼树的信息,向左遍历,buff(哈夫曼编码)加字符0,向右遍历,buff(哈夫曼编码)加字符1,当遍历到哈夫曼树的叶子节点时,读取buff存入umap_haffman中。

8)创建文件
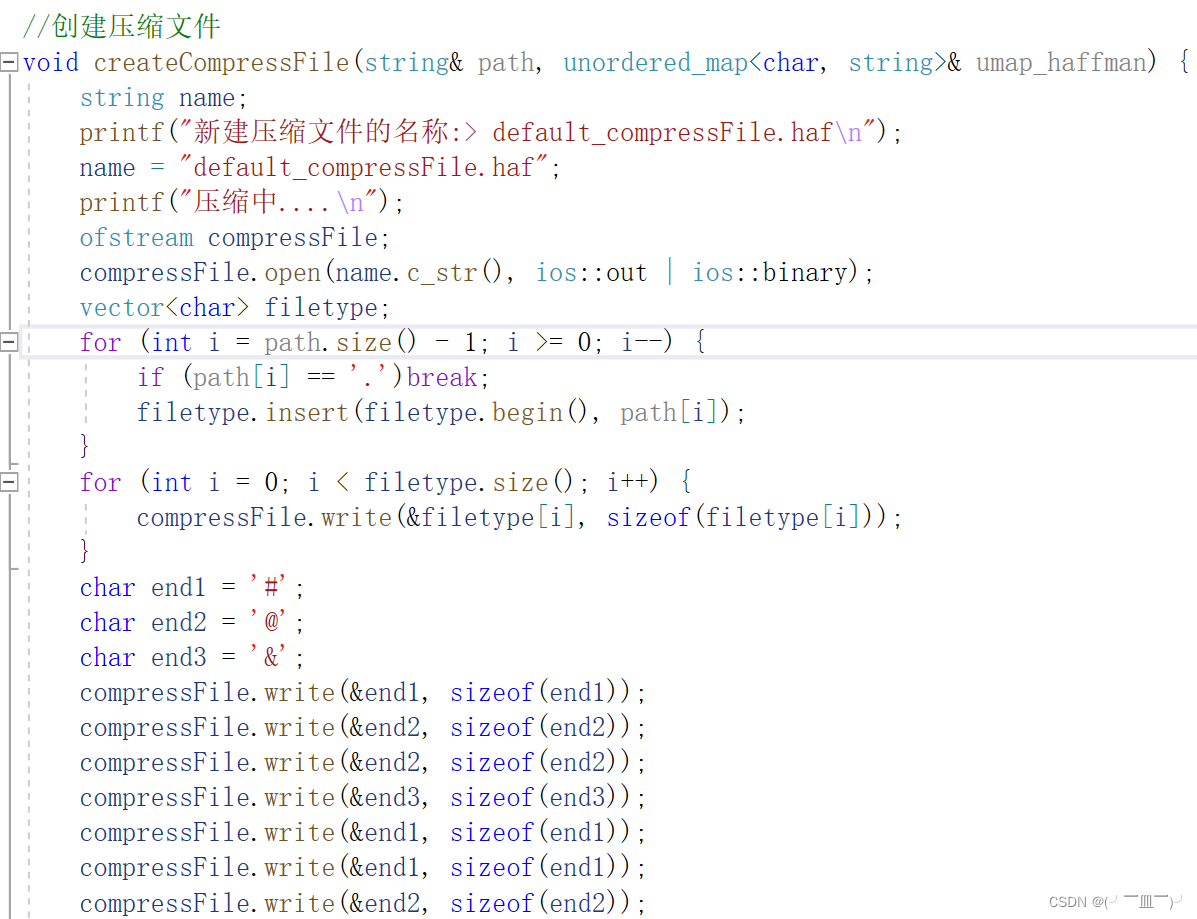
- 为了解压所有类型的文件,要以二进制的打开和写入压缩文件
- 读取压缩文件的绝对路径(path),并存入压缩文件中,然后加入标识符#@@&##@
- 将哈夫曼码的种类数量以字节的形式写入压缩文件中,然后加入标识符#@@&##@

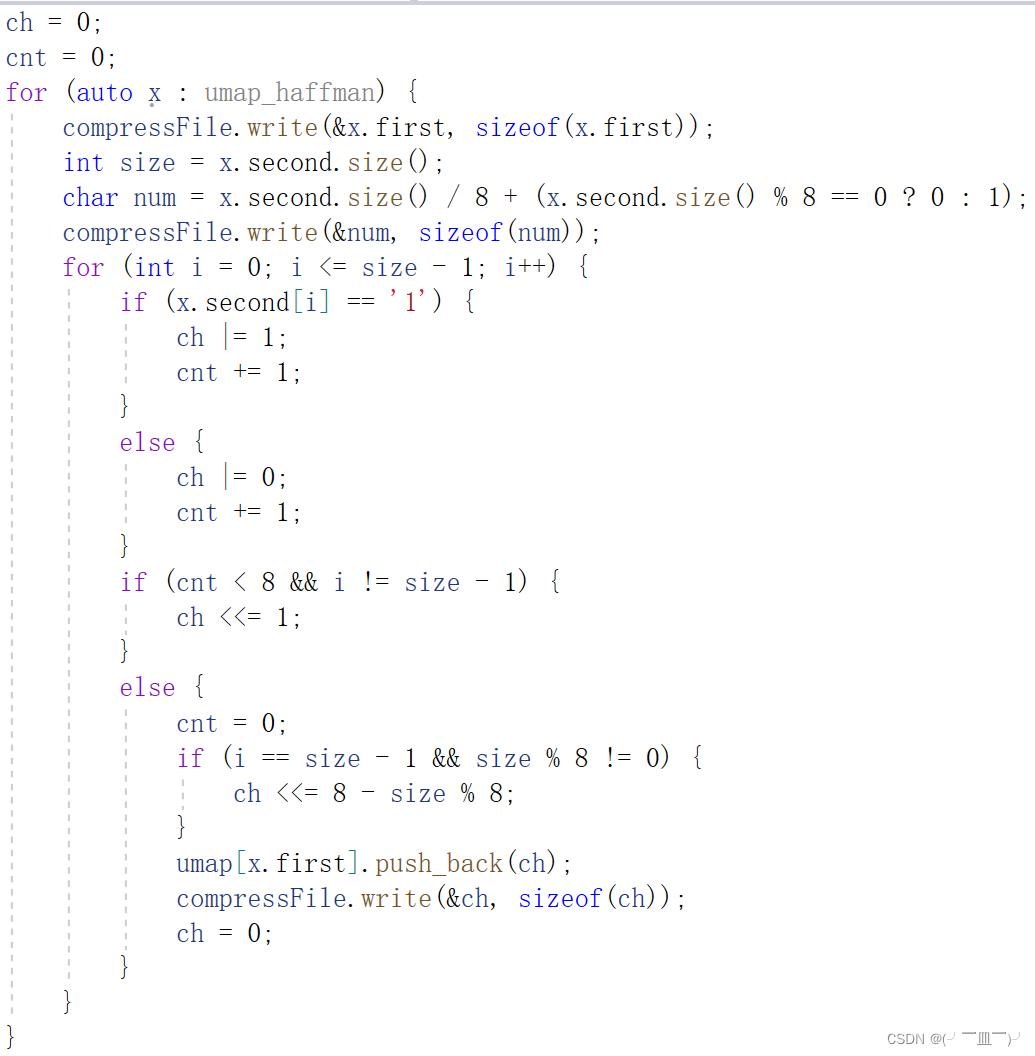
- 将哈夫曼码,按位压入字节中,若满八位的就继续压入新的字节,不满八位的继续左移,直至压满8位,这样既可以减少压缩文件的大小,也可以保证新的字符串类型的哈夫曼码不会出现重复。
- 以二进制的形式按字节读取要压缩的原文件,通过umap(保存<字节,新的字符串类型的哈夫曼码>),转换成哈夫曼码以二进制的形式按字节存入压缩文件中。

- main函数,利用循环读取文件名,并考虑文件名有空格的情况

1.3实验结果与分析
/*要压缩的文件较大时,压缩时间可能会比较大*/
1)在终端打开mycompress.exe
2)压缩操作
在终端输入./mycompress + 要压缩的文件绝对路径
./mycompress表示mycompress.exe
1.4 mycompress.cpp
#define _CRT_SECURE_NO_WARNINGS
#include<iostream>
#include<string>
#include<unordered_map>
#include<fstream>
#include<cstdio>
using namespace std;
/**********************************************************************************
注意:
1.可以压缩解压任意文件!!!
***********************************************************************************/
typedef struct Node {
char ch;
int freq;
struct Node* lchild, * rchild;
Node(char ch, int freq, Node* l = NULL, Node* r = NULL) :ch(ch), freq(freq), lchild(l), rchild(r) {}
}Node;
Node* getNewNode(char ch, int freq) {
Node* p = new Node(ch, freq);
return p;
}
void clear(Node* root) {
if (root == NULL)return;
clear(root->lchild);
clear(root->rchild);
delete root;
return;
}
//原文件的freq_table的创建
void buildFreqMap(unordered_map<char, int>& umap_freq, vector<Node*>& node_arr, string& path) {
ifstream file;
file.open(path.c_str(), ios::in | ios::binary);
if (file.is_open()) {
char ch;
while (file.read(&ch, sizeof(ch))) {
umap_freq[ch] += 1;
}
cout << "打开成功" << endl;
file.close();
}
else {
cout << "打开失败" << endl;
}
for (auto& x : umap_freq) {
node_arr.push_back(getNewNode(x.first, x.second));
}
return;
}
//寻找vector中frequency最小的node
int find_min_node(vector<Node*>& node_arr, int n) {
int ind = 0;
for (int i = 1; i <= n; i++) {
if (node_arr[ind]->freq > node_arr[i]->freq) ind = i;
}
return ind;
}
//建Huffman树
Node* buildHaffmanTree(vector<Node*>& node_arr) {
for (int i = 1, I = node_arr.size(); i < I; i++) {
int ind1 = find_min_node(node_arr, I - i);
swap(node_arr[ind1], node_arr[I - i]);
int ind2 = find_min_node(node_arr, I - i - 1);
swap(node_arr[ind2], node_arr[I - i - 1]);
int freq = node_arr[I - i]->freq + node_arr[I - i - 1]->freq;
Node* node = getNewNode(0, freq);
node->lchild = node_arr[I - i - 1];
node->rchild = node_arr[I - i];
node_arr[I - i - 1] = node;
}
return node_arr[0];
}
//创建HuffmanTable
void extractHaffmanCode(Node* root, unordered_map<char, string>& umap_haffman, string buff) {
if (root->lchild == NULL && root->rchild == NULL) {
umap_haffman[root->ch] = buff;
return;
}
buff.push_back('0');
extractHaffmanCode(root->lchild, umap_haffman, buff);
buff[buff.size() - 1] = '1';
extractHaffmanCode(root->rchild, umap_haffman, buff);
return;
}
void menu() {
printf("******************************************************\n\n");
printf("1.压缩文件\n");
printf("2.解压文件\n");
printf("3.退出\n\n");
printf("******************************************************\n\n");
return;
}
//创建压缩文件
void createCompressFile(string& path, unordered_map<char, string>& umap_haffman) {
string name;
printf("新建压缩文件的名称:> default_compressFile.haf\n");
name = "default_compressFile.haf";
printf("压缩中....\n");
ofstream compressFile;
compressFile.open(name.c_str(), ios::out | ios::binary);
vector<char> filetype;
for (int i = path.size() - 1; i >= 0; i--) {
if (path[i] == '.')break;
filetype.insert(filetype.begin(), path[i]);
}
for (int i = 0; i < filetype.size(); i++) {
compressFile.write(&filetype[i], sizeof(filetype[i]));
}
char end1 = '#';
char end2 = '@';
char end3 = '&';
compressFile.write(&end1, sizeof(end1));
compressFile.write(&end2, sizeof(end2));
compressFile.write(&end2, sizeof(end2));
compressFile.write(&end3, sizeof(end3));
compressFile.write(&end1, sizeof(end1));
compressFile.write(&end1, sizeof(end1));
compressFile.write(&end2, sizeof(end2));
unordered_map<char, vector<char>> umap;
if (compressFile.is_open()) {
int len = umap_haffman.size();
char ch = 0;
int cnt = 0;
while (len) {
if (len > 100) {
ch = 100;
compressFile.write(&ch, sizeof(ch));
len -= 100;
}
else if (len == 100) {
ch = 100;
compressFile.write(&ch, sizeof(ch));
len = 0;
}
else if (len < 100) {
ch = len;
compressFile.write(&ch, sizeof(ch));
len = 0;
}
}
compressFile.write(&end1, sizeof(end1));
compressFile.write(&end2, sizeof(end2));
compressFile.write(&end2, sizeof(end2));
compressFile.write(&end3, sizeof(end3));
compressFile.write(&end1, sizeof(end1));
compressFile.write(&end1, sizeof(end1));
compressFile.write(&end2, sizeof(end2));
ch = 0;
cnt = 0;
for (auto x : umap_haffman) {
compressFile.write(&x.first, sizeof(x.first));
int size = x.second.size();
char num = x.second.size() / 8 + (x.second.size() % 8 == 0 ? 0 : 1);
compressFile.write(&num, sizeof(num));
for (int i = 0; i <= size - 1; i++) {
if (x.second[i] == '1') {
ch |= 1;
cnt += 1;
}
else {
ch |= 0;
cnt += 1;
}
if (cnt < 8 && i != size - 1) {
ch <<= 1;
}
else {
cnt = 0;
if (i == size - 1 && size % 8 != 0) {
ch <<= 8 - size % 8;
}
umap[x.first].push_back(ch);
compressFile.write(&ch, sizeof(ch));
ch = 0;
}
}
}
ifstream file;
file.open(path.c_str(), ios::in | ios::binary);
if (file.is_open()) {
char buff;
while (file.read(&buff, sizeof(buff))) {
for (int i = 0; i < umap[buff].size(); i++) {
compressFile.write(&umap[buff][i], sizeof(umap[buff][i]));
}
}
cout << "读出成功!\n" << endl;
file.close();
}
else {
cout << "读出失败!\n" << endl;
}
compressFile.close();
cout << "写入成功!\n" << endl;
}
else {
cout << "打开文件失败!\n" << endl;
}
}
//压缩
void compressFile(string path) {
unordered_map<char, int> umap_freq;
unordered_map<char, string> umap_haffman;
vector<Node*> node_arr;
buildFreqMap(umap_freq, node_arr, path);
Node* root = buildHaffmanTree(node_arr);
string buff;
extractHaffmanCode(root, umap_haffman, buff);
createCompressFile(path, umap_haffman);
clear(root);
}
int main(int argc, char* argv[]) {
if(*(argv + 1) != NULL){
int cnt = 1;
string path;
while (argv[cnt] != NULL) {
if (cnt != 1)path += " ";
path += string(argv[cnt++]);
}
compressFile(path);
}
else cout << "压缩失败--没有有效输入" << endl;
return 0;
}
2 哈夫曼编码实现任意文件的解压
2.1实验要求
1)利用哈夫曼编码实现任意文件的无损解压。
2)利用mian函数的参数实现在终端的无损解压操作。
2.2代码设计
1)封装解压步骤,umap_haffman是哈夫曼码和对应的字节的哈希表

2)以二进制的形式打开压缩文件,读取原文件的文件名后缀(文件类型),通过标识符(#@@&##@),找到文件名后缀,存入filetype

3)先读取哈夫曼码的种类数量(SIZE),再根据SIZE读取压缩文件的哈夫曼码和与它对应的二进制字节,存入umap_haffman(<哈夫曼码,二进制字节>)。

4)读取压缩文件中的哈夫曼码集,转换为相应的字节,以二进制的形式写入解压文件

2.3实验结构与分析
1)解压png
- ./myuncompress表示myuncompress.exe
- 在终端输入./myuncompress+ 要解压的文件绝对路径
2.4 myuncompress.cpp
#define _CRT_SECURE_NO_WARNINGS
#include<iostream>
#include<string>
#include<unordered_map>
#include<fstream>
#include<cstdio>
using namespace std;
/**********************************************************************************
注意:
1.可以压缩解压任意文件!!!
***********************************************************************************/
//创建解压文件的haffman_table
void completeDecomopress(string path, unordered_map<string, char>& umap_haffman) {
ifstream compressFile;
compressFile.open(path.c_str(), ios::in | ios::binary);
string end = "#@@&##@";
string temp;
while (temp.find(end) == -1) {
char ch;
compressFile.read(&ch, sizeof(ch));
temp.push_back(ch);
}
string filetype(temp.begin(), temp.begin() + (temp.size() - 7));
string len;
while (len.find(end) == -1) {
char ch;
compressFile.read(&ch, sizeof(ch));
len.push_back(ch);
}
string num;
int SIZE = 0;
for (int i = 0; i < len.size() - 7; i++) {
SIZE += (int)len[i];
}
for (int i = 0; i < SIZE; i++) {
char ch, size;
compressFile.read(&ch, sizeof(ch));
compressFile.read(&size, sizeof(size));
string s;
for (int i = 0; i < (int)size; i++) {
char c;
compressFile.read(&c, sizeof(c));
s.push_back(c);
}
umap_haffman[s] = ch;
}
string name;
printf("新建解压文件的名称:>default_decompressFile.%s\n", filetype.c_str());
name = "default_decompressFile." + filetype;
printf("解压中.....\n");
ofstream decompressFile;
decompressFile.open(name.c_str(), ios::out | ios::binary);
if (decompressFile.is_open()) {
char ch;
string s;
while (compressFile.read(&ch, sizeof(ch))) {
s.push_back(ch);
char target;
if (umap_haffman.find(s) != umap_haffman.end()) {
target = umap_haffman[s];
s.clear();
decompressFile.write(&target, sizeof(target));
}
}
decompressFile.close();
compressFile.close();
cout << "写入成功!\n" << endl;
}
else {
cout << "打开文件失败!\n" << endl;
}
}
//解压
void decompressFile(string path) {
unordered_map<string, char> umap_haffman;
completeDecomopress(path, umap_haffman);
}
int main(int argc, char* argv[]) {
if (*(argv + 1) != NULL) {
int cnt = 1;
string absolutePath;
while(argv[cnt] != NULL) {
if (cnt != 1) absolutePath += " ";
absolutePath += string(argv[cnt++]);
}
decompressFile(absolutePath);
}
else cout << "解压失败--没有有效地址" << endl;
}


























 14万+
14万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









