







条件随机场模型(CRF)在序列标注问题中得到广泛应用,并且事实证明CRF的效果不错。本文就以下几个问题写下自己的理解:
1、哪些场景适合序列标注模型,哪些场景适合分类器模型?
Edwin Chen在介绍条件随机场的博文中,通过一个有趣的问题,引入条件随机场序列标注问题,我们这里不妨拿过来直接用一下:
假设你有一组关于 Justin Bieber的日常生活照(你可以想像成Bieber是个自拍狂,经常在朋友圈晒自拍),你想标注一下这些照片描绘的活动场景(比如Bieber是在吃饭、参加舞会、开车,还是在睡觉呢),你会怎么做呢?
一种方法是不考虑照片的发生先后关系,通过svm、决策树之类的分类方法,对每张照片单独分类。比如,你有事先标注的关于Bieber的一个月的日常生活照,你可以通过这些标注集训练一个分类器,通过这些标注集合,你可能得到一个这样的分类器:拍摄于晚上6点之后光线很暗的照片是在睡觉,拍摄于晚上灯光闪烁的照片是在参加舞会.....
通过上述方法虽然也能解决问题,但是会丢失一些信息,比如有一张照片是bieber嘴的一个特写,你怎么判断他是在吃法还是在唱歌呢?如果你能知道,这张照片的前一张是关于Bieber在做饭的照片,那这张嘴的特写照很可能就是在吃饭;反之,前一张照片是在参加舞会,那这张特写就更可能是在唱歌。
因此,为了提高照片标注的准确性,我们就需要参考相邻照片的标注,这就是序列标注问题,也是条件随机场能大显身手的场景。
当然,你也许会说我在训练分类器的时候也可以加上跟时间有关的特征,比如上面的例子,在训练分类器的时候,可以把标注集按时间排序,然后把每张图前后的图片的类别作为分类器特征,来训练分类器。但是仔细想下,就会发现其中的问题,你在用这些分类器模型预测上面例子中的问题时,你是不知道每张图片的前后相邻图片的类别的,它们也是需要预测的;那你可能又说,预测出第一张图片类别后,可以把这个图片的类别作为特征预测下一张,但是这样做引入的问题就是如果第一张预测错了,就会影响第二张的预测,即引起误差传递。而序列标注模型是把这一组照片的类别作为一个整体来预测,是这个整体预测准确率最高。
知乎上有人做了一下总结,我觉得总结的不错:
标注跟分类最大的区别就是:标注采的特征里面有上下文分类结果,这个结果你是不知道的,他在“分类”的时候是跟上下文一起"分类的"。因为你要确定这个词的分类得先知道上一个词的分类,所以这个得整句话的所有词一起解,没法一个词一个词解。


当给出一个"U01:%x[0,1]"的模板时,CRF++会产生如下的一些特征函数集合(func1 ... funcN):

这几个函数我说明一下,%x[0,1]这个特征到前面的例子就是说,根据词语(第1列)的词性(第2列)来预测其标注(第3列),这些函数就是反应了训练样例的情况,func1反映了“训练样例中,词性是DT且标注是B-NP的情况”,func2反映了“训练样例中,词性是DT且标注是I-NP的情况”。
模板函数的数量是L*N,其中L是标注集中类别数量,N是从模板中扩展处理的字符串种类,我理解的是N就是训练数据中,标记、词语、词性这个三元组不同的行数。
第二种是Bigram template:第一个字符是B,每一行%x[#,#]生成一个CRFs中的边(Edge)函数:f(s', s, o), 其中s'为t – 1时刻的标签.也就是说,Bigram类型与Unigram大致机同,只是还要考虑到t – 1时刻的标签.如果只写一个B的话,默认生成f(s', s),这意味着前一个output token和current token将组合成bigram features。目前看到的例子中Bigram都只用了B一个特征模板,即只考虑前面一个标记的影响,可以结合HMM的状态转移概率考虑。
Bifram的模板会产生L * L * N种不同的特征。
3.CRF是怎么计算测试数据的标记的?
了解CRF的同学肯定都知道CRF是判别模型,给定一个句子s,要求出句子的标记,就是找出一个标记序列l,使得P(l|s)概率最大,即

这里n = 所有可能的标记序列数量,以中文切词为例,假设切分标记为B、E、M、S,待切分的句子长度为m,那标记序列的数量就是4的m次方。
那么只要我们能求出是每个标记序列l的概率 P(l|s),然后取概率最大的l,也就求出了最终的标记序列。
假设我们在训练阶段已经得到了每个特征

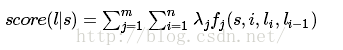
(公式上第一个求和对应特征数,第二个求和对应句子长度)
最终,我们可以通过指数函数和归一化,将分数转换成概率,公式如下
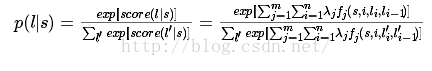
上述算法的很容易理解,但是通过枚举所有可能的标记序列,计算时间长,所以我们在几乎所有介绍CRF的资料上,都是用维特比算法求解,具体的算法细节我也没深入研究过,有兴趣的可以看下相关资料。
4.CRF可以用哪些特征
以CRF++为例,每一列表示一个特征维度,理论上可以使用任意特征,只需要在预处理阶段,提取出这些特征,放到相应的列上就可以了;具体到项目上,选哪些特征就需要根据标注任务选择了。
参考资料:
CRF++官网:https://taku910.github.io/crfpp/
大神Edwin的博客:http://blog.echen.me/2012/01/03/introduction-to-conditional-random-fields/ (Edwin的博客很多内容非常值得看,推荐下)















 119
119

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









