






本文复现了论文《Bidirectional LSTM-CRF Models for Sequence Tagging 》的LSTM+CRF模型,并可在Penn Treebank、CoNLL2000和CoNLL2003数据集上测试运行。
LSTM+CRF整体流程与相关变量:
变量:以CoNLL2003为例
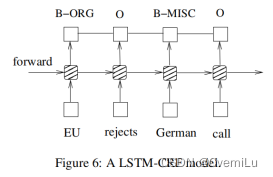
X_train:训练集句子:EU rejects German call to boycott British lamb .
Y_train:训练集句子单词的实体类型:B-ORG O B-MISC O O O B-MISC O O
X_test:测试集句子:SOCCER - JAPAN GET LUCKY WIN , CHINA IN SURPRISE DEFEAT .
Y_test:测试集句子单词的实体类型:O O B-LOC O O O O B-PER O O O O
Word2idx:训练集+测试集单词数组:{'Boat': 0, 'Standings': 1, ... , '<pad>': 27316}
Vocab_size:训练集+测试集单词个数:27317
Tag2idx:训练集+测试集实体类型数组:{'I-ORG': 0, 'I-MISC': 1, ... , '<pad>': 11}}
Max_length:句子最长的长度:设置为124
Dataset:
Inputs:句子单词在word2idx中的编号:[386,10193,24516,14669,24332,17873,9648,21165,11724, 27316,27316,27316, ... , 27316]:一组里面有max_length个数值,用<pad>的编号填充
Targets:句子单词的实体类型在tag2idx中的编号:[1,2,7,2,2,2,7,2,2,11,11,11, ... ,11]:一组里面有 max_length个数值,用<pad>的编号填充
Length_list:每个句子的真实长度:[9, 2, 2, 30, ... , 4]
Dataloder:以batch_size为一组分割Dataset
batch_size:一次训练所抓取的数据样本数量:论文里设置为100
embedding_size:特征向量的大小:论文里设置为50
hidden_size:隐藏层:论文里设置为300
Epochs:循环次数:论文里设置为10
整体流程:
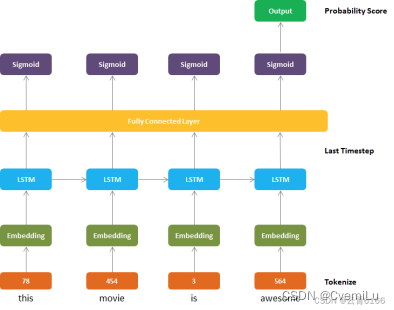
1.构造dataloder:
Dataloder每一块为100行(=batch size)和124列(=sequence length),共有141块(根据具体数据计算).
Dataloder作为嵌入层的输入.
2.Embedding Layer:nn.Embedding
self.embedding = nn.Embedding(vocab_size(=词汇表大小), embedding_size(=嵌入维数,把具体数值改成embedding_size维向量)).
embeds = self.embedding(sentences)
从嵌入层的输出可以看出,它作为嵌入权值的结果创建了一个三维张量。现在它每块有100行,124列和50个嵌入维,也就是说,在我们的审查中,我们为每个标记化的单词添加了嵌入维。该数据现在将进入LSTM层.
torch.nn.Embedding(
num_embeddings, – 词典的大小尺寸,比如总共出现5000个词,那就输入5000。此时index为(0-4999)
embedding_dim,– 嵌入向量的维度,即用多少维来表示一个符号。
padding_idx=None,– 填充id,比如,输入长度为100,但是每次的句子长度并不一样,后面就需要用统一的数字填充,而这里就是指定这个数字,这样,网络在遇到填充id时,就不会计算其与其它符号的相关性。(初始化为0)
max_norm=None, – 最大范数,如果嵌入向量的范数超过了这个界限,就要进行再归一化。
norm_type=2.0, – 指定利用什么范数计算,并用于对比max_norm,默认为2范数。
scale_grad_by_freq=False, 根据单词在mini-batch中出现的频率,对梯度进行放缩。默认为False.
sparse=False, – 若为True,则与权重矩阵相关的梯度转变为稀疏张量。
_weight=None)
3. LSTM Layer:nn.LSTM
self.lstm = nn.LSTM(embedding_size(=嵌入维数), hidden_size(=隐藏层数), bidirectional=False(=选择是否双向))
lstm_out, _ = self.lstm(packed_sentences)
通过查看LSTM层的输出,我们可以看到每块现在有100行,124列和300个LSTM节点。接下来,该数据被提取到全连接层。
torch.nn.LSTM(
input_size 输入数据的特征维数,通常就是embedding_dim(词向量的维度)
hidden_size LSTM中隐层的维度
num_layers 循环神经网络的层数
bias 用不用偏置,default=True
batch_first 这个要注意,通常我们输入的数据shape=(batch_size,seq_length,embedding_dim),而batch_first默认是False,所以我们的输入数据最好送进LSTM之前将batch_size与seq_length这两个维度调换
dropout 默认是0,代表不用dropout
bidirectional默认是false,代表不用双向LSTM)
输入数据包括input,(h_0,c_0):
input就是shape=(seq_length,batch_size,input_size)的张量
h_0是shape=(num_layers*num_directions,batch_size,hidden_size)的张量,它包含了在当前这个batch_size中每个句子的初始隐藏状态。其中num_layers就是LSTM的层数。如果bidirectional=True,num_directions=2,否则就是1,表示只有一个方向。
c_0和h_0的形状相同,它包含的是在当前这个batch_size中的每个句子的初始细胞状态。h_0,c_0如果不提供,那么默认是0。
输出数据包括output,(h_n,c_n):
output的shape=(seq_length,batch_size,num_directions*hidden_size),
它包含的是LSTM的最后一时间步的输出特征(h_t),t是batch_size中每个句子的长度。
h_n.shape==(num_directions * num_layers,batch,hidden_size)
c_n.shape==h_n.shape
h_n包含的是句子的最后一个单词(也就是最后一个时间步)的隐藏状态,c_n包含的是句子的最后一个单词的细胞状态,所以它们都与句子的长度seq_length无关。
output[-1]与h_n是相等的,因为output[-1]包含的正是batch_size个句子中每一个句子的最后一个单词的隐藏状态,注意LSTM中的隐藏状态其实就是输出,cell state细胞状态才是LSTM中一直隐藏的,记录着信息
4. Fully Connected Layer:nn.Linear
self.hidden_to_tag = nn.Linear(hidden_size(=隐藏层数), self.target_size(=实体类型个数,为12))
feature = self.hidden_to_tag(result)
Feature.shape = torch.Size([100, 124, 12])
对于全连通层,输入特征数= LSTM中隐藏单元数。输出大小= 实体类型个数
torch.nn.Linear(in_feature: int型, 在forward中输入Tensor最后一维的通道数,
out_feature: int型, 在forward中输出Tensor最后一维的通道数,
bias: bool型, Linear线性变换中是否添加bias偏置)
5. CRF Layer:CRF
self.crf = CRF(self.target_size(=实体类型个数),batch_first=True)
self.crf(self.LSTM_Layer(sentences, length_list), targets, self.get_mask(length_list))
假设LSTM节点的输出是1.5 (B-Person), 0.9 (I-Person), 0.1 (B-Organization), 0.08 (I-Organization) and 0.05 (O)。这些分数将会是CRF层的输入。所有的经LSTM层输出的分数将作为CRF层的输入,类别序列中分数最高的类别就是我们预测的最终结果。
CRF(num_tags, batch_first=True)
self.crf.decode(self.LSTM_Layer(sentences, length_list), self.get_mask(length_list))
CRF.decode(emissions, mask=None):使用Viterbi algorithm找到概率最大的实体类型
Parameters:
emissions (Tensor) – Emission score tensor of size if is False, otherwise.(seq_length, batch_size, num_tags)batch_first(batch_size, seq_length, num_tags)
mask (ByteTensor,0、1向量) – Mask tensor of size if is False, otherwise.(seq_length, batch_size)batch_first(batch_size, seq_length)
Return type:List[List[int]]
Returns:List of list containing the best tag sequence for each batch(注意:这个decode返回的是一个list,由于mask的存在,解码返回的是实际的句子长度的解码结果).
6. 优化器与损失函数
optimizer = torch.optim.Adam(model.parameters(), lr)#构造优化器
model.zero_grad()#梯度初始化为0
loss = (-1) * model(inputs, length_list, targets)#构造损失函数
loss.backward()#反向传播(计算梯度)
total_norm = torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm)#裁剪梯度
optimizer.step()#更新网络参数
7. 其他小知识点
①pack_padded_sequence()与pad_packed_sequence():
数据进入LSTM层之前要pack_padded_sequence:包装数据
数据离开LSTM层之前要pack_packed_sequence:解压数据
pytorch之数据:pack_padded_sequence()与pad_packed_sequence()_模糊包的博客-CSDN博客
②batch_first的使用
LSTM默认batch_first=False,即默认batch_size这个维度是在数据维度的中间的那个维度,即喂入的数据为【seq_len, batch_size, hidden_size】这样的格式。此时
lstm_out:【seq_len, batch_size, hidden_size * num_directions】
lstm_hn:【num_directions * num_layers, batch_size, hidden_size】
当设置batch_first=True时,喂入的数据就为【batch_size, seq_len, hidden_size】这样的格式。此时
lstm_out:【 batch_size, seq_len, hidden_size * num_directions】
lstm_hn:【num_directions * num_layers, batch_size, hidden_size】
pytorch中LSTM的输出的理解,以及batch_first=True or False的输出层的区别_lstm输出维度的理解_Icy Hunter的博客-CSDN博客
③get_mask的使用
Mask机制就是我们在使用不等长特征的时候先将其补齐,在训练模型的时候再将这些参与补齐的数去掉,从而实现不等长特征的训练问题。
Python Lstm mask机制_Jeaten的博客-CSDN博客
8. 参考
源代码:
复旦nlp实验室 nlp-beginner 任务四:基于LSTM+CRF的序列标注_爱睡觉的Raki的博客-CSDN博客
流程解读:LSTM网络中各层解读_lstm全连接层_云霄6166的博客-CSDN博客
CRF层详解:最通俗易懂的BiLSTM-CRF模型中的CRF层介绍 - 知乎
9. 源代码(本代码可以直接在GPU上运行)
import torch
import torch.nn as nn
from torch.nn.utils.rnn import pack_padded_sequence
from torch.nn.utils.rnn import pad_packed_sequence
from TorchCRF import CRF
import torch
from torch.utils.data import DataLoader, Dataset
import numpy as np
import time
import torch
import matplotlib.pyplot as plt
from torchtext.vocab import Vectors
import sys
import time
#LSTM_CRF模型
class LSTM_CRF(nn.Module):
# LSTM_CRF(LSTM_CRF, vocab_size, tag2idx, embedding_size, hidden_size, max_length=train_max_length, vectors=None)
def __init__(self, vocab_size, tag_to_index, embedding_size, hidden_size, max_length, vectors=None):
super(LSTM_CRF, self).__init__()
self.embedding_size = embedding_size #特征向量大小
self.hidden_size = hidden_size #隐藏层数
self.vocab_size = vocab_size #单词集长度
self.tag_to_index = tag_to_index #实体类型集
self.target_size = len(tag_to_index) #实体类型个数
if vectors is None:#自己训练
self.embedding = nn.Embedding(vocab_size, embedding_size)
else:
self.embedding = nn.Embedding.from_pretrained(vectors)
self.lstm = nn.LSTM(embedding_size, hidden_size, bidirectional=False)#bidirectional:lstm是否为双向:论文设置为false
self.hidden_to_tag = nn.Linear(hidden_size, self.target_size)#设置网络中的全连接层:用隐藏层全连接
self.crf = CRF(self.target_size,batch_first=True)#batch_first为True表示batch是第一个参数而不是第二个参数
self.max_length = max_length
def get_mask(self, length_list):
mask = []
for length in length_list:
mask.append([1 for i in range(length)] + [0 for j in range(self.max_length - length)])
return torch.tensor(mask, dtype=torch.bool, device='cuda')
def LSTM_Layer(self, sentences, length_list):
embeds = self.embedding(sentences)
length_list=length_list.cpu()
packed_sentences = pack_padded_sequence(embeds, lengths=length_list, batch_first=True, enforce_sorted=False)
lstm_out, _ = self.lstm(packed_sentences)
result, _ = pad_packed_sequence(lstm_out, batch_first=True, total_length=self.max_length)
feature = self.hidden_to_tag(result)
return feature
def CRF_layer(self, input, targets, length_list):
"""Compute the conditional log likelihood of a sequence of tags given emission scores.
Args:
emissions (`~torch.Tensor`): Emission score tensor of size
``(seq_length, batch_size, num_tags)`` if ``batch_first`` is ``False``,
``(batch_size, seq_length, num_tags)`` otherwise.
tags (`~torch.LongTensor`): Sequence of tags tensor of size
``(seq_length, batch_size)`` if ``batch_first`` is ``False``,
``(batch_size, seq_length)`` otherwise.
mask (`~torch.ByteTensor`): Mask tensor of size ``(seq_length, batch_size)``
if ``batch_first`` is ``False``, ``(batch_size, seq_length)`` otherwise.
reduction: Specifies the reduction to apply to the output:
``none|sum|mean|token_mean``. ``none``: no reduction will be applied.
``sum``: the output will be summed over batches. ``mean``: the output will be
averaged over batches. ``token_mean``: the output will be averaged over tokens.
Returns:
`~torch.Tensor`: The log likelihood. This will have size ``(batch_size,)`` if
reduction is ``none``, ``()`` otherwise.
"""
return self.crf(input, targets, self.get_mask(length_list))
def forward(self, sentences, length_list, targets):
x = self.LSTM_Layer(sentences, length_list)
x = self.CRF_layer(x, targets, length_list)
return x
def predict(self, sentences, length_list):
out = self.LSTM_Layer(sentences, length_list)
mask = self.get_mask(length_list)
return self.crf.decode(out, mask)
#数据处理相关
def read_data(path):#提取conll2003单词与实体类型,整合成句子
sentences_list = [] # 每一个元素是一整个句子
sentences_list_labels = [] # 每个元素是一整个句子的标签
with open(path, 'r', encoding='UTF-8') as f:
sentence_labels = [] # 每个元素是这个句子的每个单词的标签
sentence = [] # 每个元素是这个句子的每个单词
for line in f:
line = line.strip()
if not line: # 如果遇到了空白行
if sentence: # 防止空白行连续多个,导致出现空白的句子
sentences_list.append(' '.join(sentence))
sentences_list_labels.append(' '.join(sentence_labels))
sentence = []
sentence_labels = []
# 创建新的句子的list,准备读入下一个句子
else:
res = line.split()
assert len(res) == 4#假定一行为一个res,且res有四个值
if res[0] == '-DOCSTART-':
continue
sentence.append(res[0])#单词
sentence_labels.append(res[3])#短语类型
if sentence: # 防止最后一行没有空白行,导致最后一句话录入不到
sentences_list.append(sentence)
sentences_list_labels.append(sentence_labels)
return sentences_list, sentences_list_labels
def build_vocab(sentences_list):#合并训练集和测试集,分别把单词和实体类型变成词典
ret = []
for sentences in sentences_list:
ret += [word for word in sentences.split()]
return list(set(ret))
class mydataset(Dataset):
def __init__(self, x : torch.Tensor, y : torch.Tensor, length_list):
self.x = x
self.y = y
self.length_list = length_list
def __getitem__(self, index):
#存每一个句子对应的单词下标集合,实体类型下标集合和长度
data = self.x[index]
labels = self.y[index]
length = self.length_list[index]
return data, labels, length
def __len__(self):
return len(self.x)
def get_idx(word, d):#查找单词在单词表中的位置下标
if d[word] is not None:
return d[word]
else:
return d['<unknown>']
def sentence2vector(sentence, d):#把具体句子中的单词转换成word2idx里面的位置下标
#word是句子中一个个单词
return [get_idx(word, d) for word in sentence.split()]
def padding(x, max_length, d):#填充句子,让所有句子相同长度
length = 0
for i in range(max_length - len(x)):
x.append(d['<pad>'])
return x
def get_dataloader(x, y, batch_size):#生成dataloader
#此时word2idx和tag2idx是train的单词与实体类型数组
#x=x_train,y=y_train
word2idx, tag2idx, vocab_size = pre_processing()
#s是一句一句的
inputs = [sentence2vector(s, word2idx) for s in x]
targets = [sentence2vector(s, tag2idx) for s in y]
length_list = [len(sentence) for sentence in inputs]#统计各句子中单词个数
# 在Conll2000和2003数据集中,由于训练集最大句子长度为113,测试集最大句子长度为124,所以直接设置max_length=124
max_length = 124
# max_length = 0
# max_length = max(max(length_list), max_length)
# print(max_length)
# print(max(length_list))
# sys.exit()
# max_length = max(max(length_list), max_length)
inputs = torch.tensor([padding(sentence, max_length, word2idx) for sentence in inputs])
targets = torch.tensor([padding(sentence, max_length, tag2idx) for sentence in targets], dtype=torch.long)
dataset = mydataset(inputs, targets, length_list)
#shuffle为false:词法分析单词之间的位置不可以打乱
dataloader = DataLoader(dataset, shuffle=False, batch_size=batch_size)
return dataloader, max_length
def pre_processing():#生成单词与实体类型数组(不含重复项)
x_train, y_train = read_data("conll2003_ner/train.txt")
x_test, y_test = read_data("conll2003_ner/test.txt")
d_x = build_vocab(x_train+x_test)#单词集
d_y = build_vocab(y_train+y_test)#实体类型集
word2idx = {d_x[i]: i for i in range(len(d_x))}#给单词编号
tag2idx = {d_y[i]: i for i in range(len(d_y))}#给实体类型编号
#penn treebank
# tag2idx["<START>"] = 39
# tag2idx["<STOP>"] = 40
# conll2000
# tag2idx["<START>"] = 23
# tag2idx["<STOP>"] = 24
#conll2003
tag2idx["<START>"] = 9
tag2idx["<STOP>"] = 10
pad_idx = len(word2idx)
word2idx['<pad>'] = pad_idx
tag2idx['<pad>'] = len(tag2idx)
# tag2idx['<unknown>'] = len(tag2idx)
vocab_size = len(word2idx)
idx2tag = {value: key for key, value in tag2idx.items()}
print(tag2idx)
return word2idx, tag2idx, vocab_size
def compute_f1(pred, targets, length_list):#计算f1值
tp, fn, fp, tn = [], [], [], []
#penn treebank
x = 45
y=41
#conll2000
# x=30
# y=25
# conll2003
# x = 15
# y = 9#为实体类型数组长度
for i in range(x):
tp.append(0)
fn.append(0)
fp.append(0)
tn.append(0)
for i, length in enumerate(length_list):
for j in range(length):
a, b = pred[i][j], targets[i][j]
if (a == b):
tp[a] += 1
tn[a] += 1
else:
fp[a] += 1
fn[b] += 1
tps = 0
fps = 0
fns = 0
tns = 0
for i in range(y):
tps += tp[i]
fps += fp[i]
fns += fn[i]
tns += tn[i]
precision = tps / (tps + fps)
recall = tps / (tps + fns)
accurary = (tps + tns) / (tps + tns + fns + fps)
f1=2 * precision * recall / (precision + recall)
return f1
#main:
batch_size = 100 #一次训练所抓取的数据样本数量:论文里设置为100
embedding_size = 50 #特征向量的大小:论文里设置为50
hidden_size = 300 #隐藏层:论文里设置为300
epochs = 10 #循环次数:论文里设置为10
def train(model, vocab_size, tag2idx, embedding_size, hidden_size, max_length, vectors=None):
model = model(vocab_size, tag2idx, embedding_size, hidden_size, max_length, vectors=vectors)#初始化模型
if torch.cuda.is_available():
model = model.cuda() # model 在 GPU 上进行训练
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)#lr为学习率,论文里设置为0.1
start_time = time.time()
loss_history = []
print("dataloader length: ", len(train_dataloader))#表示训练集按照batchsize分成了多少组
#训练模式
model.train()
f1_history = []
idx2tag = {value: key for key, value in tag2idx.items()}
for epoch in range(epochs):#循环
total_loss = 0.
f1 = 0
for idx, (inputs, targets, length_list) in enumerate(train_dataloader):#其中每次循环有batch_size个句子
if torch.cuda.is_available():
inputs = inputs.cuda()
targets = targets.cuda()
length_list = length_list.cuda()
model.zero_grad()#梯度初始化为0
loss = (-1) * model(inputs, length_list, targets)
total_loss += loss.item()
pred = model.predict(inputs, length_list)#预测训练集的实体类型
# print(inputs,targets,length_list)
# print(loss)
# print(pred)
# sys.exit()
f=compute_f1(pred, targets, length_list)
f1 += f#计算f1
loss.backward()#反向传播(计算梯度)
max_norm = 0.5
total_norm = torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm)#裁剪梯度:解决梯度爆炸问题
clip_coef = max_norm/total_norm#用于max_norm调参
optimizer.step()#更新网络参数
# if (idx + 1) % 10 == 0 and idx:#10组含有batch_size条句子为一组
cur_loss = total_loss
loss_history.append(cur_loss / (idx + 1))
f1_history.append(f1 / (idx + 1))
total_loss = 0
print("epochs : {}, batch : {}, loss : {}, f1 : {}".format(epoch + 1, (idx+1) * batch_size,
cur_loss / ((idx + 1) * batch_size),
f1 / (idx + 1)))
#绘制损失函数图像
plt.plot(np.arange(len(loss_history)), np.array(loss_history))
plt.xlabel('Iterations')
plt.ylabel('Training Loss')
plt.title('LSTM+CRF model')
plt.show()
#绘制f1图像
plt.plot(np.arange(len(f1_history)), np.array(f1_history))
plt.title('train f1 scores')
plt.show()
#保存模型
# torch.save(model.state_dict(), "model.pth")
# 恢复为预保存好特定参数的网络模型
# model.load_state_dict(torch.load("model.pth"))
# print(model)
#测试模式
model.eval()
f1 = 0
accuracy = 0
precision = 0
recall = 0
f1_history = []
s = 0
with torch.no_grad():#不会更新已经训练好的模型的网络参数
for idx, (inputs, targets, length_list) in enumerate(test_dataloader):
if torch.cuda.is_available():
inputs = inputs.cuda()
targets = targets.cuda()
length_list = length_list.cuda()
loss = (-1) * model(inputs, length_list, targets)
total_loss += loss.item()
pred = model.predict(inputs, length_list)
f= compute_f1(pred, targets, length_list)
f1 += f
f1_history.append(f1 / (idx + 1))
s = idx
print("f1 score : {},test size = {}".format(f1 / (s + 1), (s + 1)))
# 绘制f1图像
plt.plot(np.arange(len(f1_history)), np.array(f1_history))
plt.title('test f1 scores')
plt.show()
if __name__ == '__main__':
x_train, y_train = read_data("conll2003_ner/train.txt")
x_test, y_test = read_data("conll2003_ner/test.txt")
word2idx, tag2idx, vocab_size = pre_processing()
train_dataloader, train_max_length = get_dataloader(x_train, y_train, batch_size)
test_dataloader, test_max_length = get_dataloader(x_test, y_test, 32)
train(LSTM_CRF, vocab_size, tag2idx, embedding_size, hidden_size, max_length=train_max_length, vectors=None)















 117
117











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









