







信息熵、信息增益
信息熵:一个系统的信息含量的量化指标
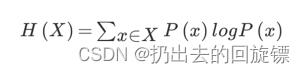
信息增益:定义为集合D的信息熵H(D)与特征A给定条件下D的信息条件熵H(D|A)之差,表示得知特征X的信息而使得类Y的信息的不确定性减少的程度
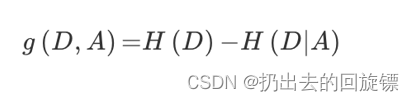
决策树的分类依据之一就是信息增益
决策树 API(泰坦尼克乘客生还概率)
import pandas as pd
from sklearn.feature_extraction import DictVectorizer
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier,export_graphviz
def decision():
titan = pd.read_csv("./titanic.csv")
x = titan[['pclass','age','sex']]
y = titan['survived']
x['age'].fillna(x['age'].mean(),inplace=True)
x_train, x_test, y_train, y_test = train_test_split(x,y,test_size=0.25)
dict = DictVectorizer(sparse=False)
x_train = dict.fit_transform(x_train.to_dict(orient="records"))
print(dict.get_feature_names())
x_test = dict.transform((x_test.to_dict(orient="records")))
dec = DecisionTreeClassifier(max_depth=8)
dec.fit(x_train,y_train)
print("预测的准确率:",dec.score(x_test,y_test))
export_graphviz(dec,out_file="./tree.dot",feature_names=['age', 'pclass=1st', 'pclass=2nd', 'pclass=3rd', 'sex=female', 'sex=male'])
return None
if __name__ == "__main__":
decision()


说明:
- windows安装graphvizdot文件转png
- sklearn决策树API

- 常见决策树使用的算法

- sklearn中默认使用基尼系数来进行划分
- 决策树的可视化,相对利于理解
随机森林
包含多个决策树的分类器,其输出的类别是由个别树输出的类别的众数而定。
建立决策树的过程
- N表示训练用例的个数,M表示特征的数目
- m << M,选出m个特征数目
- 从N个训练用例中采取有放回抽样的方式,取样N次,形成训练集,并且使用未抽取的用例作预测,评估其误差
import pandas as pd
from sklearn.feature_extraction import DictVectorizer
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.tree import DecisionTreeClassifier,export_graphviz
from sklearn.ensemble import RandomForestClassifier
def decision():
titan = pd.read_csv("./titanic.csv")
x = titan[['pclass','age','sex']]
y = titan['survived']
x['age'].fillna(x['age'].mean(),inplace=True)
x_train, x_test, y_train, y_test = train_test_split(x,y,test_size=0.25)
dict = DictVectorizer(sparse=False)
x_train = dict.fit_transform(x_train.to_dict(orient="records"))
print(dict.get_feature_names())
x_test = dict.transform((x_test.to_dict(orient="records")))
rf = RandomForestClassifier()
parm = {"n_estimators":[120,200,300,500,800,1200],"max_depth":[5,8,15,25,30]}
gc = GridSearchCV(rf,param_grid=parm,cv=2)
gc.fit(x_train,y_train)
print("预测概率为:",gc.score(x_test,y_test))
print("查看选择的参数模型:",gc.best_params_)
return None
if __name__ == "__main__":
decision()

说明:
- 只要选择参数合适,随机森林的准确率很高
- 随机森林API

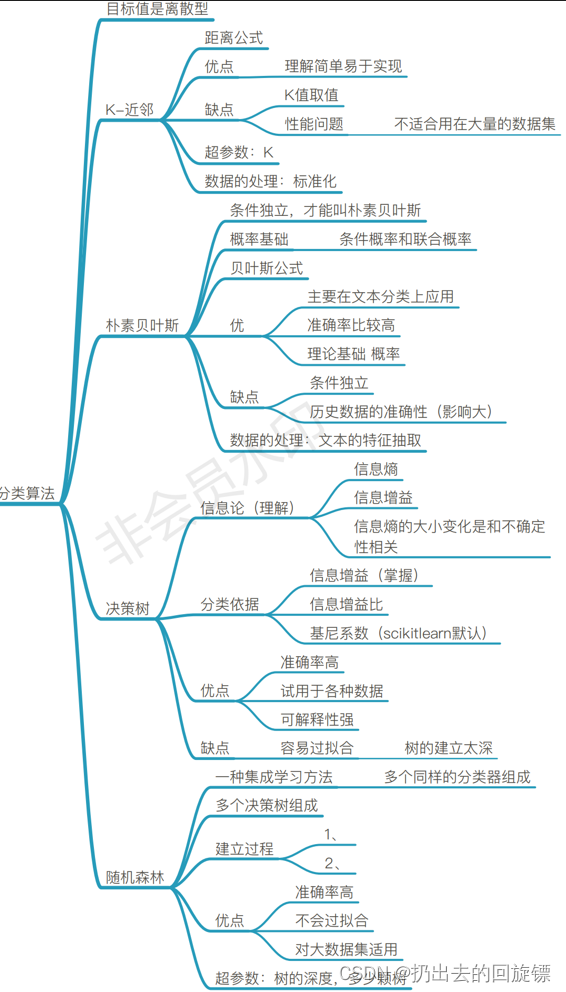
几种分类算法总结














 283
283











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









