







bucket用来对原始数据进行分组计算然后在生成一份新的json,先通过下图来看其每个属性的作用,如下图:
根据属性boundaries的规则,会把下图基础数据按照year_born分成如下4组(表格是5组,因为other没数据,也就是说没有大于1880或者小于1840的数据,所以就自动删除了),注意[标志包含此值,)表示不包含此值。如下表格:
| [1840, 1850) | [1850, 1860) | [1860, 1870) | [1870, 1880) | other |
| 1840 | 1853 1855 | 1861 1863 1868 1868 | 1871 |
注
然后,通过例子来看一下执行的结果
基础数据如下(数据插入语句参考官网$bucket (aggregation) — MongoDB Manual):
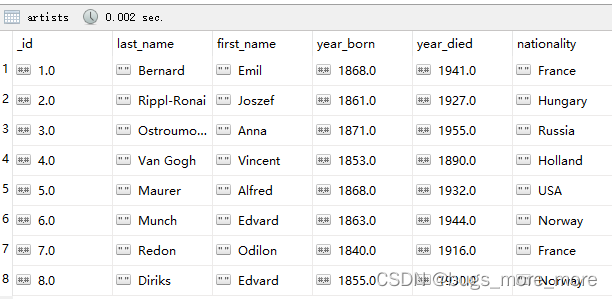
最后执行指令:
db.artists.aggregate( [
// First Stage
{
$bucket: {
groupBy: "$year_born",
boundaries: [ 1840, 1850, 1860, 1870, 1880 ],
default: "Other",
output: {
"count": { $sum: 1 },
"artists" :
{
$push: {
"name": { $concat: [ "$first_name", " ", "$last_name"] },
"year_born": "$year_born"
}
}
}
}
},
// Second Stage
{
$match: { count: {$gt: 3} }//将分组后,count字段值大于3的显示出来,count是在output中通过计算得到的,也就是统计出boundaries指定的某个年龄段人数大于3的记录:
}
] )执行后得到如下结果,根据原始数据,统计出了boundaries指定的某个年龄段人数大于3的记录: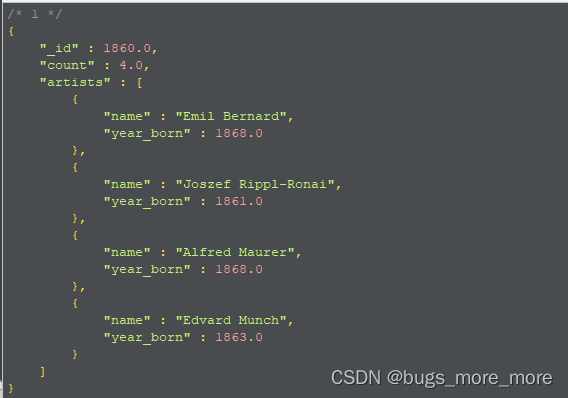

















 364
364

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









