






索引在数据库的查询中起到的作用毋庸置疑,但时常有人提出索引的建立的问题,to be or not to be 的问题。
问题1 索引建立后,就不再变动了 ?
大多数的问题是在于索引建立后并不能一直良好的工作,主要有以下几个问题
1 重复功能的索引,让查询无法把握或者在管理人员不知情的情况下,走了其他的索引,索引并不能有效的工作,并成为负担。
2 索引在PG的数据改变变化导致索引失效的问题。
3 随着应用场景的变化,索引已经不能完成原先设计的功能,而成为查询中导致性能低下的一个瓶颈。
4 索引建立的过多,导致数据的写入性能产生问题。
索引的建立和不建立的问题
在有效评估数据表的大小的情况下,一个索引建立不建立是一个问题,如果数据量小,则一般可以不建立索引,但是问题是
1 怎样的数量算小
2 未来数据增加怎么办
所以建立索引是一个非常需要经验和考量的问题,而并不是建立他就完事了,针对索引整体的跟踪体系,以及分析体系,才是一个让你的数据库更好工作的起点。
select indexrelid,schemaname,relname,indexrelname,idx_scan,idx_tup_read from pg_stat_all_indexes where schemaname not in ('pg_toast','pg_catalog');
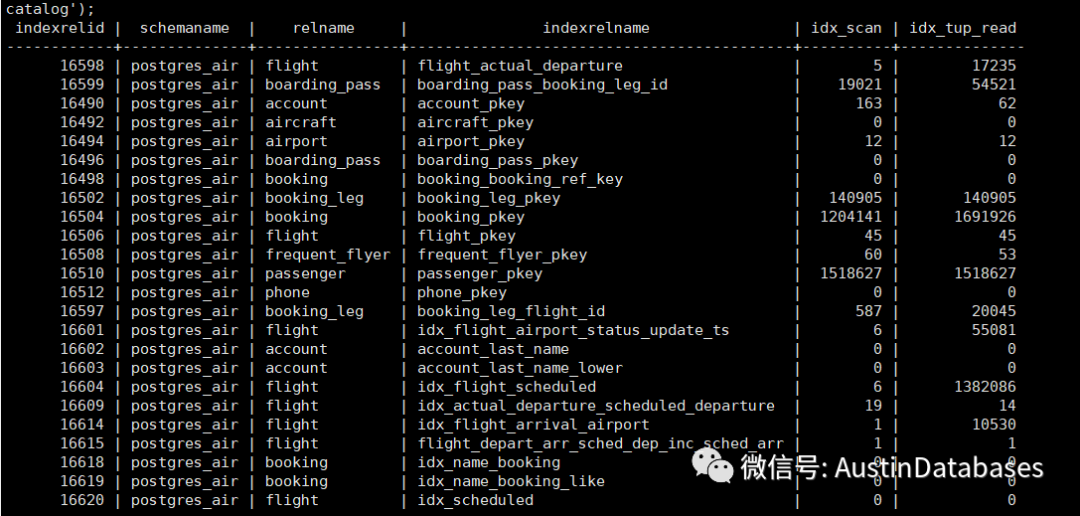
通过这个表可以查看到底有多少索引并不在工作中,或者从PG的开机后,并没有进行工作。但是这样的工作对于主键是不合适的,所以查看这样的工作可以对主键进行一个屏蔽。
同时不可以忽略的问题是随着数据的增长,索引无法完全加载到内存当中,导致的数据查询性能的问题。
同时在数据查询的过程中,索引的也会经历一个曲线,有索引和无索引的表象。
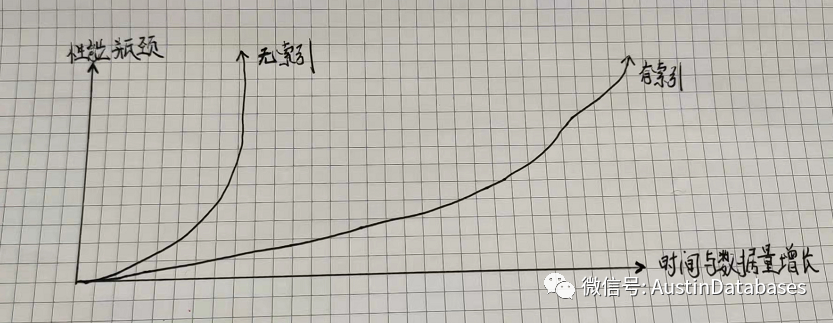
除此以外即使有了索引的情况下,还会产生数据查询条件于数据的采样分布的问题。
我们用下面的例子来说明,同样的表,同样的查询的方式
postgres=# explain SELECT
postgres-# p.last_name,
postgres-# p.first_name
postgres-# FROM passenger p
postgres-# JOIN boarding_pass bp USING (passenger_id)
postgres-# JOIN booking_Leg bl USING (booking_leg_id)
postgres-# JOIN flight USING(flight_id)
postgres-# WHERE departure_airport='LAX'
postgres-# AND lower(last_name)='clark';
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------
Gather (cost=243530.39..638952.23 rows=2091 width=12)
Workers Planned: 4
-> Parallel Hash Join (cost=242530.39..637743.13 rows=523 width=12)
Hash Cond: (bl.flight_id = flight.flight_id)
-> Nested Loop (cost=233079.69..628209.42 rows=31617 width=16)
-> Parallel Hash Join (cost=233079.25..573669.83 rows=31617 width=20)
Hash Cond: (bp.passenger_id = p.passenger_id)
-> Parallel Seq Scan on boarding_pass bp (cost=0.00..323991.73 rows=6323373 width=16)
-> Parallel Hash (cost=232824.35..232824.35 rows=20392 width=16)
-> Parallel Seq Scan on passenger p (cost=0.00..232824.35 rows=20392 width=16)
Filter: (lower(last_name) = 'clark'::text)
-> Index Scan using booking_leg_pkey on booking_leg bl (cost=0.44..1.73 rows=1 width=8)
Index Cond: (booking_leg_id = bp.booking_leg_id)
-> Parallel Hash (cost=9391.88..9391.88 rows=4706 width=4)
-> Parallel Bitmap Heap Scan on flight (cost=307.96..9391.88 rows=4706 width=4)
Recheck Cond: (departure_airport = 'LAX'::bpchar)
-> Bitmap Index Scan on idx_flight_airport_status_update_ts (cost=0.00..305.14 rows=11295 width=0)
Index Cond: (departure_airport = 'LAX'::bpchar)
(18 rows)
整体的过程
1 并行扫描passenger 表,过滤 last_name 条件
2 并行扫描 boarding_pass 表
3 index scan booking_Leg 表
4 2个表进行hash join passenger 和 boarding_pass
5 将2个表的结果与booking_Leg 表的信息进行nested loop join
6 针对flight 表进行进行bitmap 索引扫描符合 departure_airport 等于 LAX的数据
7 针对三个表和 flight 表的结果进行 hash join
8 最终产生结果
postgres=#
postgres=# explain SELECT
postgres-# p.last_name,
postgres-# p.first_name
postgres-# FROM passenger p
postgres-# JOIN boarding_pass bp USING (passenger_id)
postgres-# JOIN booking_Leg bl USING (booking_leg_id)
postgres-# JOIN flight USING(flight_id)
postgres-# WHERE departure_airport='LAX'
postgres-# AND lower(last_name)=' smith';
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------
Gather (cost=243530.39..638952.23 rows=2091 width=12)
Workers Planned: 4
-> Parallel Hash Join (cost=242530.39..637743.13 rows=523 width=12)
Hash Cond: (bl.flight_id = flight.flight_id)
-> Nested Loop (cost=233079.69..628209.42 rows=31617 width=16)
-> Parallel Hash Join (cost=233079.25..573669.83 rows=31617 width=20)
Hash Cond: (bp.passenger_id = p.passenger_id)
-> Parallel Seq Scan on boarding_pass bp (cost=0.00..323991.73 rows=6323373 width=16)
-> Parallel Hash (cost=232824.35..232824.35 rows=20392 width=16)
-> Parallel Seq Scan on passenger p (cost=0.00..232824.35 rows=20392 width=16)
Filter: (lower(last_name) = ' smith'::text)
-> Index Scan using booking_leg_pkey on booking_leg bl (cost=0.44..1.73 rows=1 width=8)
Index Cond: (booking_leg_id = bp.booking_leg_id)
-> Parallel Hash (cost=9391.88..9391.88 rows=4706 width=4)
-> Parallel Bitmap Heap Scan on flight (cost=307.96..9391.88 rows=4706 width=4)
Recheck Cond: (departure_airport = 'LAX'::bpchar)
-> Bitmap Index Scan on idx_flight_airport_status_update_ts (cost=0.00..305.14 rows=11295 width=0)
Index Cond: (departure_airport = 'LAX'::bpchar)
(18 rows)
在我们查询条件变化的情况下,我们的查询执行计划基本是相同的
postgres=#
postgres=# explain SELECT
postgres-# p.last_name,
postgres-# p.first_name
postgres-# FROM passenger p
postgres-# JOIN boarding_pass bp USING (passenger_id)
postgres-# JOIN booking_Leg bl USING (booking_leg_id)
postgres-# JOIN flight USING(flight_id)
postgres-# WHERE departure_airport='FUK' AND lower(last_name)='smith';
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------
Gather (cost=1001.31..124225.90 rows=69 width=12)
Workers Planned: 2
-> Nested Loop (cost=1.31..123219.00 rows=29 width=12)
-> Nested Loop (cost=0.88..113476.86 rows=5785 width=8)
-> Nested Loop (cost=0.44..58845.93 rows=4092 width=4)
-> Parallel Seq Scan on flight (cost=0.00..12125.21 rows=156 width=4)
Filter: (departure_airport = 'FUK'::bpchar)
-> Index Scan using booking_leg_flight_id on booking_leg bl (cost=0.44..298.67 rows=82 width=8)
Index Cond: (flight_id = flight.flight_id)
-> Index Scan using boarding_pass_booking_leg_id on boarding_pass bp (cost=0.44..13.13 rows=22 width=16)
Index Cond: (booking_leg_id = bl.booking_leg_id)
-> Index Scan using passenger_pkey on passenger p (cost=0.43..1.68 rows=1 width=16)
Index Cond: (passenger_id = bp.passenger_id)
Filter: (lower(last_name) = 'smith'::text)
(14 rows)
而当我们还采用同样的查询方式,但将departure_airport 的条件变化后,那么查询计划整体改变了
1 对flight 表进行并行扫描
2 对booking_leg 表进行进行索引的扫描
3 针对这两个数据的集合进行nested loop 的操作
4 在对boarding_pass 表进行索引的扫描
5 在针对两个表的结果集和boarding_pass的结果集进行nested_loop查询
6 在针对passenger 表进行索引的扫描
7 最后在进行3个表的结果与passenger 的表的进行nested loop 的操作
这三个例子中,可以发现随着 departure_airport的表换,整体的查询方式和执行计划也进行了改变。
所以虽然索引都一样,但查询条件的变化也会引起查询的速度和时间的变化
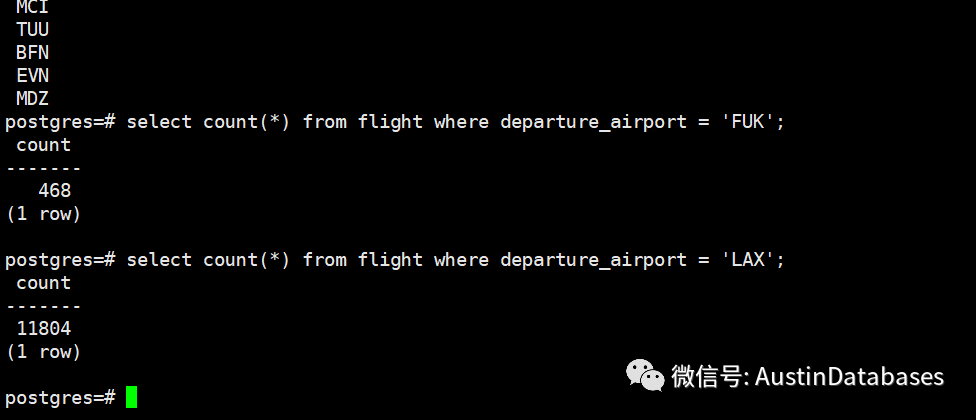
具体的问题在于一个departure_airport 的数据量仅仅有 468 另一个的数据量在 11804.
总结,索引是解决查询速度和优化查询的一个方法,但是查询条件本身的变化也针对整体的数据查询效率也具有一个决定性的条件。
















 481
481











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









