






开头还是介绍一下群,如果感兴趣PolarDB ,MongoDB ,MySQL ,PostgreSQL ,Redis, Oceanbase, Sql Server等有问题,有需求都可以加群群内有各大数据库行业大咖,可以解决你的问题。加群请联系 liuaustin3 ,(共2380人左右 1 + 2 + 3 + 4 +5 + 6) 新人奖直接分配到6群。现需要达梦的技术老师,群里最近经常有达梦的问题。
另 starrokcs 的技术老师已经入群,有starrocks 的需求可以解决。


最近不知道做对了什么,上篇SQL SERVER 的文章竟然疯狂了,5000多的阅读量并且还在增长,比MYSQL ,POSTGRESQL ,POLARDB ,MONGODB ,或者其他的数据库都要多,WHY .看来关注SQL SERVER 的人真是不少,之前我一直错觉,SQL SERVER 关注得人不多了。
(同时群里,我看到有人提出如果给数据库一个高低贵贱等级,SQL SERVER的DBA 是最低贱的,这完全是偏见,偏见,偏见!那吃大蒜 喝咖啡的那个高贵?)
言归正传,笔者已经安装好windows 版本的SQL SERVER 2022 准备在有时间的时间,稍微的研究一下新的一些功能。
这次我们说说SQL SERVER中一直被人诟病的问题,缓冲池扫描的问题,我们都知道SQL SERVER 是8KB的页面,这里除了蹩脚的MySQL 是16KB ,其他的数据库都是8KB页面,PG默认也是8KB,但是在数据库重启,或者关闭后,在开机后,SQL SERVER 有一个问题,就是缓冲池扫描的问题。
其他的数据库都有自己的一些解决方案,包含部分开源的数据库产品,但SQL SERVER 作为一个商业数据库产品,在2022之前有民间方案,但称之为成熟的方案没有。随着一些业务的变大,一些SQL SERVER 本身具有128G 或者更大的内存,我见过的是最大的是768GB内存的SQL SERVER 。这些大内存的主机在重启后,将磁盘的数据重新灌入到内存中,是有一个缓慢的过程的,我们称之为 缓冲池扫描。
这也就是一直在SQL SERVER 重启后,被诟病的第一次查询会比价慢,以及我们之前有一些同学撰写的 ,开机后的预热脚本(真的有人这样做,比较有意思,将常用的查询,写长脚本在系统重启后,运行这个脚本加速数据的读入到内存) 但是在SQL SERVER 2022 版本解决了这个问题,他提供 了并行缓冲扫描来解决这个问题,这个增强的缓冲池是利用了多个CPU技术,并行进行数据的扫描,新的技术中为每800万个缓冲区,相当与64G的内存分配一个任务,如果缓冲池少于800万,则还是使用串行扫描。同时2016SP3 2017CU23 ,2019CU9版本的中对于缓冲池扫描事件的添加,让SQL SERVER 用户可以通过Extended events ,可以出发分析buffer pool scan 的问题,设置相关的出发值,来分析问题,这就是因为这个问题在2022版本中添加这个事件的发现来找到系统的性能问题。
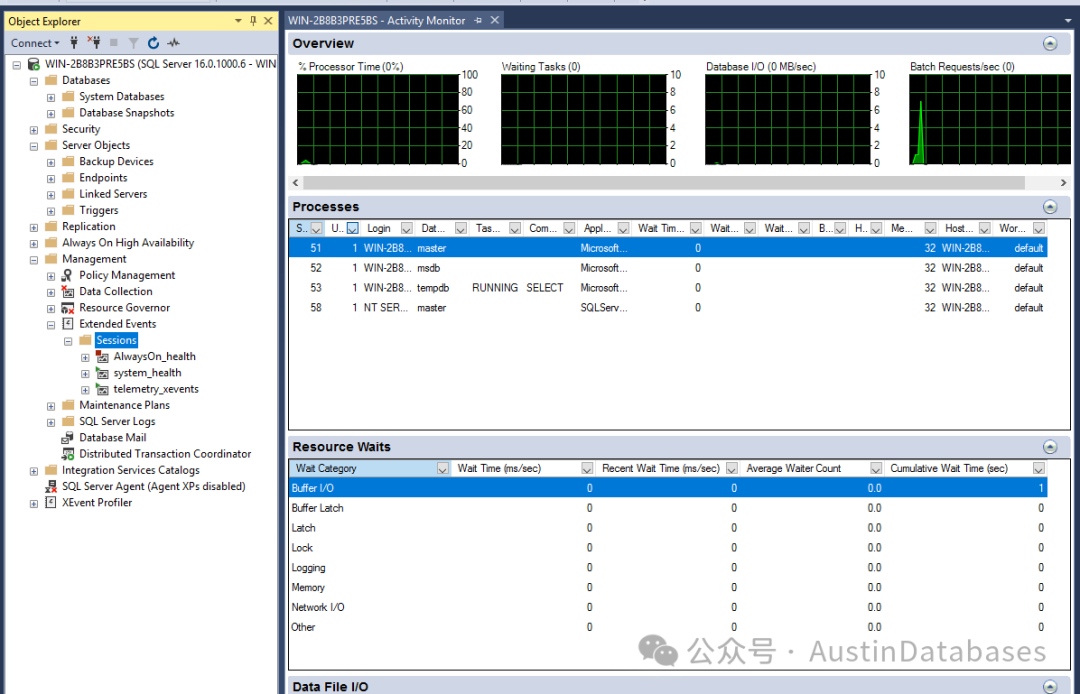
当然国外的媒体也有对这个功能进行一些评测,和说明

同时SQL SERVER DMV 也提供 select * from sys.dm_os_buffer_descriptors; select * from sys.dm_os_waiting_tasks; select * from sys.dm_exec_requests 视图
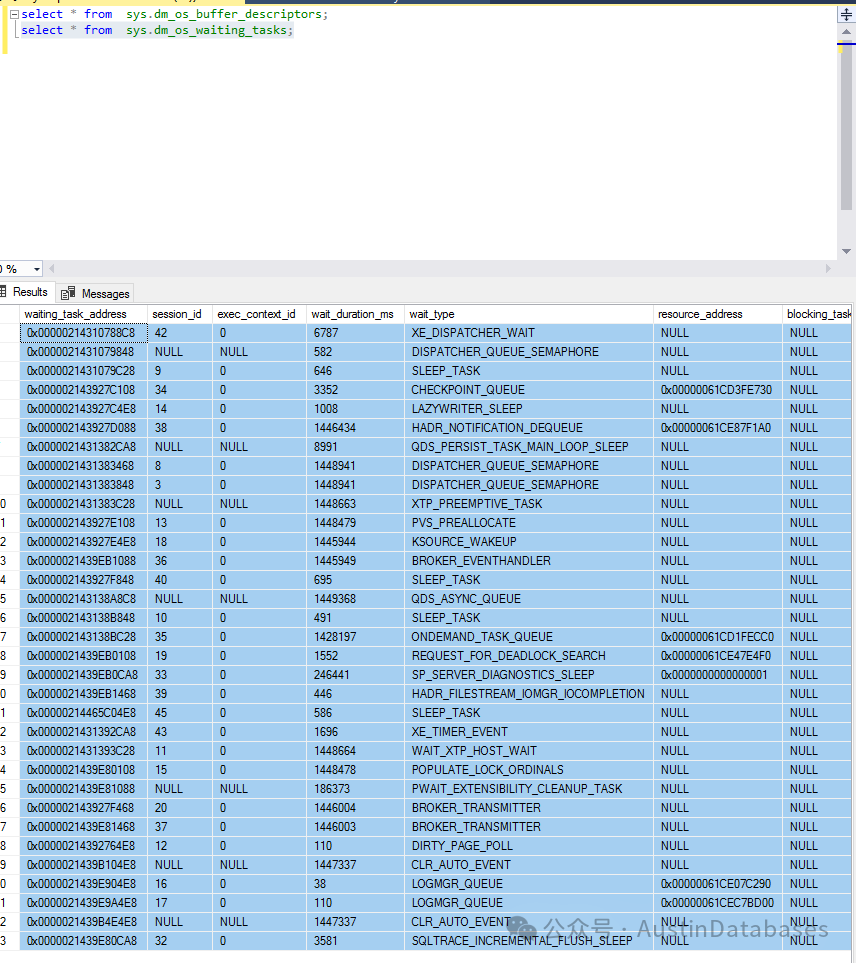
比如 sys.dm_exec_requests 可以监控并行度的一些数据, sys.dm_exec_sessions分析 session 级别的信息并行 sessions, sys.dm_os_waiting_tasks 检查任务中等待 parallelism相关的资源.
另外自SQL SERVER 2016版本中的新功能query store,在2022版本中有了更大的进步,这项功能可以通过SSMS 来对所有查询的消耗进行详细的信息统计,这些设计也都是从SQL SERVER 的社区来的信息,与用户群进行的交互开始得出的结论。之前QS 的主要目的是为了记录查询的记录的信息跟踪而来的,而到了2022版本的数据库上,QS主要的目的是为了提供更多的扩展只能查询处理的新功能而工作的,并且这项功能已经可以通过历史的数据分析得到SQL可以的最好的运行计划以及运行的方式。
这里SQL SERVER 有一个功能 degree of parallelism feedback (DOP),但在历史中,我们的SQL SERVER 在运行这个功能的时候,很多时候都倾向于对于查询使用全量的CPU 来进行并行的工作,虽然初衷是好的,但太多的CPU 在查询中被使用导致了IOPS 称为查询中的瓶颈,而导致更严重的系统性能问题。
举例:在SQL SERVER 2022 QS 中添加了,has_compile_replay_script 的信息记录,这个部分主要会帮助一些复杂的SQL语句在查询中,不在走相关的SQL语句执行计划的编译,而是复用之前记录的执行计划,减少重新计算执行计划的性能损耗。同时SQL SERVER 2022 已经提供了在always on 高可用系统中的standby 节点或者说只读节点的QUERY STORE的功能,之前QS 只能在主节点展开,现在从节点可以有独立的QS 数据存储来响应不同的查询的需求。
has_compile_replay_script | bit | Applies to: SQL Server 2022 (16.x) and later versions Indicates whether the plan has an optimization replay script associated with it: 0 = No optimization replay script (none or even invalid). 1 = optimization replay script recorded. Not applicable to Azure Synapse Analytics. |
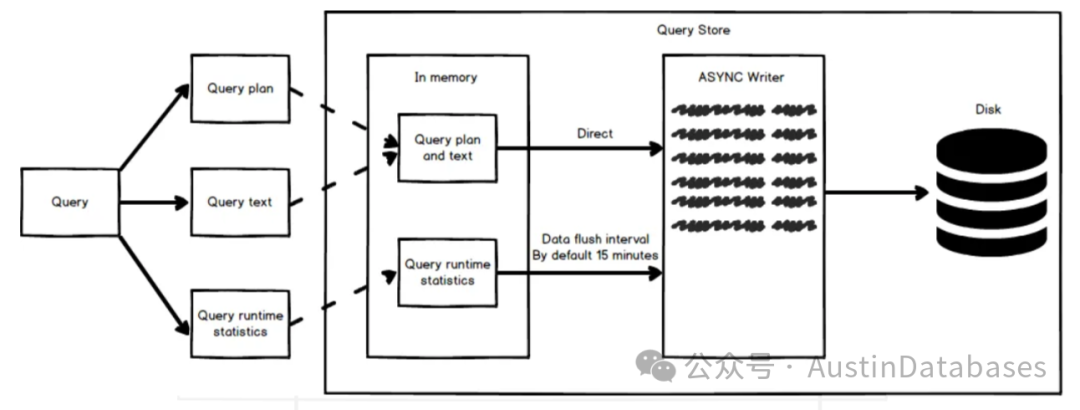
这里可以设置QS 中存储信息的数据存储空间,如果设置的比较小,抛弃历史信息就会比较快同时如果一些设置比较大,则会影响系统的运行。
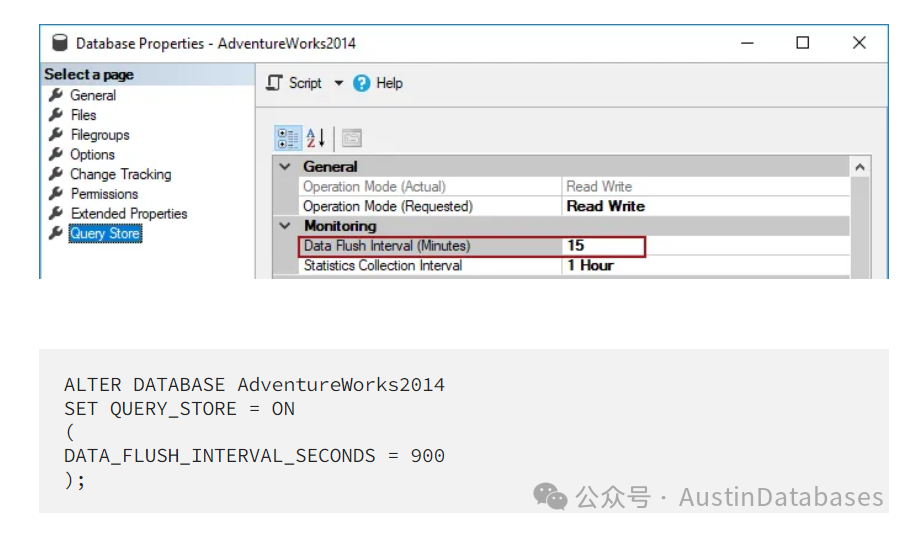
ALTER DATABASE CURRENT SET QUERY_STORE = ON
(
OPERATION_MODE = READ_WRITE,
CLEANUP_POLICY = (STALE_QUERY_THRESHOLD_DAYS = 90),
DATA_FLUSH_INTERVAL_SECONDS = 900,
QUERY_CAPTURE_MODE = AUTO,
MAX_STORAGE_SIZE_MB = 1024,
INTERVAL_LENGTH_MINUTES = 60
);
GO
ALTER DATABASE SCOPED CONFIGURATION SET OPTIMIZED_PLAN_FORCING = ON;
GO如要对数据库运行的执行计划,启动forceing plan 可以按照上方的语句设置QS 并在启动QS 后,设置FP,针对你需要进行设置的数据库进行设置。
如有在QS 运行中,发现自动优化的语句有问题,不细问QS 对于运行的语句进行智能的优化,可以使用如下的语句来对语句禁止使用相关的优化方式的推荐。
SELECT ProductID,
OrderQty,
SUM(LineTotal) AS Total
FROM Sales.SalesOrderDetail
WHERE UnitPrice < $5.00
GROUP BY ProductID,
OrderQty
ORDER BY ProductID,
OrderQty
OPTION (USE HINT('DISABLE_OPTIMIZED_PLAN_FORCING'));
GO参考文章:
https://www.microsoft.com/en-us/sql-server/blog/2022/08/18/query-store-is-enabled-by-default-in-sql-server-2022/
https://learn.microsoft.com/en-us/sql/relational-databases/performance/optimized-plan-forcing-query-store?view=sql-server-ver16
https://learn.microsoft.com/en-us/sql/relational-databases/performance/optimized-plan-forcing-query-store?view=sql-server-ver16
置顶文章:
MYSQL 版本迁移带来 严重生产事故“的”分析
MongoDB 的一张“大字报” 服务客户,欢迎DISS
MySQL 8.0 版本更新 要点 列表 (8.0-8.0.23)
临时工说:炮轰阿里云MongoDB司令部 低质高价技术差 你是要疯!!!!
生成式 AI 能否取代 DBA 结尾有炸弹
临时工说:数据库厂商官方媒体干不过 “破落户” 这究竟是为哪般?
往期热门文章:
PolarDB VS PostgreSQL "云上"性能与成本评测 -- PolarDB 比PostgreSQL 好?
PostgreSQL 版本升级到PG14后,pgbouncer 无法使用怎么回事?
临时工访谈:NoSQL 大有前景,MongoDB DBA 被裁员后谋求新职位
PolarDB for PostgreSQL 有意思吗?有意思呀
PolarDB Serverless POC测试中有没有坑与发现的疑问
PolarDB 数据库架构 测试 serverless 后的 三字真言 稳定,灵活,省钱(的用对地方)
临时工访谈:DBA 考PMP 有用没有用,访谈专业的项目管理人士的意见
MySQL 的SQL引擎很差吗?由一个同学提出问题引出的实验
临时工访谈:从国产数据库 到 普罗大众的产品 !与在美国创业软件公司老板对话
MySQL 的SQL引擎很差吗?由一个同学提出问题引出的实验
临时工访谈:我很普通,但我也有生存的权利,大龄程序员 求职贴
PolarDB Serverless POC测试中有没有坑与发现的疑问
临时工访谈:PolarDB Serverless 发现“大”问题了 之 灭妖记 续集
临时工访谈:庙小妖风大-PolarDB 组团镇妖 之 他们是第一
PostgreSQL PG_DUMP 工作失败了怎么回事及如何处理
PostgreSQL 为什么也不建议 RR隔离级别,MySQL别笑
临时工访谈:OceanBase上海开大会,我们四个开小会 OB 国产数据库破局者
MONGODB ---- Austindatabases 历年文章合集
MYSQL --Austindatabases 历年文章合集
POSTGRESQL --Austindatabaes 历年文章整理
POLARDB -- Ausitndatabases 历年的文章集合
PostgreSQL 查询语句开发写不好是必然,不是PG的锅
SQL SERVER 如何实现UNDO REDO 和PostgreSQL 有近亲关系吗
MongoDB 2023纽约 MongoDB 大会 -- 我们怎么做的新一代引擎 SBE Mongodb 7.0双擎力量(译)
Austindatabases 公众号,主要围绕数据库技术(PostgreSQL, MySQL, Mongodb, Redis, SqlServer,PolarDB, Oceanbase 等)和职业发展,国外数据库大会音译,国外大型IT信息类网站文章翻译,等,希望能和您共同发展。
截止今天共发布 1164篇文章
















 3664
3664

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









