







第二部分 排序和顺序统计量
第7章 快速排序
- 快速排序最坏情况的时间复杂度为Θ(n²)
- 但是快速排序是实际排序应用中最好的选择,因为它的平均性能非常好:它的期望时间复杂度是Θ(nlgn),而且Θ(nlgn)中隐含的常数因子非常小
- 原址排序
1. 快速排序的描述
与归并排序一样,也使用了分治思想
Quick-sort(A, p, r)
if p < r
q = Partition(A, p, r)
Quick-sort(A, p, q-1)
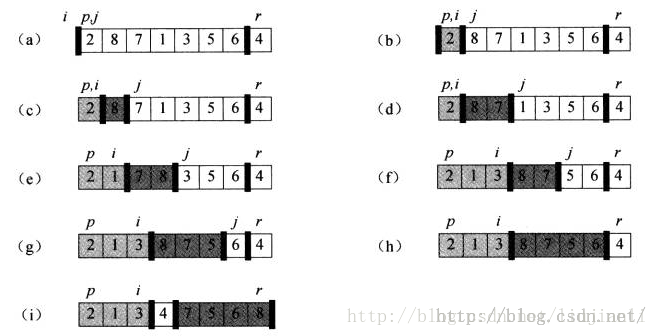
Quick-sort(A, q+1, r)算法的关键部分是Partition过程,它实现了对子数组A[p..r]的原址重排。
Partition总是选择一个x=A[r]作为主元,并围绕它来划分子数组A[p..r]。随着程序的执行,数组被划分成4个区域。
Partition(A, p, r)
x = A[r]
i = p - 1
for j = p to r - 1
if A[j] <= x
i = i + 1
exchange A[i] width A[j]
exchange A[i+1] with A[r]
return i + 12. 快速排序的性能
快速排序的运行时间依赖于划分是否平衡,而平衡与否又依赖于用于划分的元素。划分平衡与归并排序性能一样,否则,其性能接近于插入排序
- 最坏情况划分,时间复杂度为Θ(n²)
- 最好情况划分,时间复杂度为Θ(nlgn)
快速排序的平均运行时间更接近于其最好情况,而非最坏情况。
3. 快速排序的随机化版本
随机从子数组A[p..r]中随机选择一个元素作为主元。为达到这一目的,首先将A[r]与从A[p..r]中随机选出的一个元素交换。
Randomized-Partition(A, p, r)
i = Random(p, r)
exchange A[r] with A[i]
return Partition(A, p, r)Randomized-Quick-sort(A, p, r)
if p < r
q = Randomized-Partition(A, p, r)
Randomized-Quick-sort(A, p, q-1)
Randomized-Quick-sort(A, q+1, r)














 290
290

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









