







使用requests包!
1.headers获取
以果干为例,
- 谷歌浏览器中中打开果干该网页
- 在网页中右键单击点击“检查”,出现如下页面。

- 点击最上方选项卡中的‘Network’选项,再按F5,出现如下界面
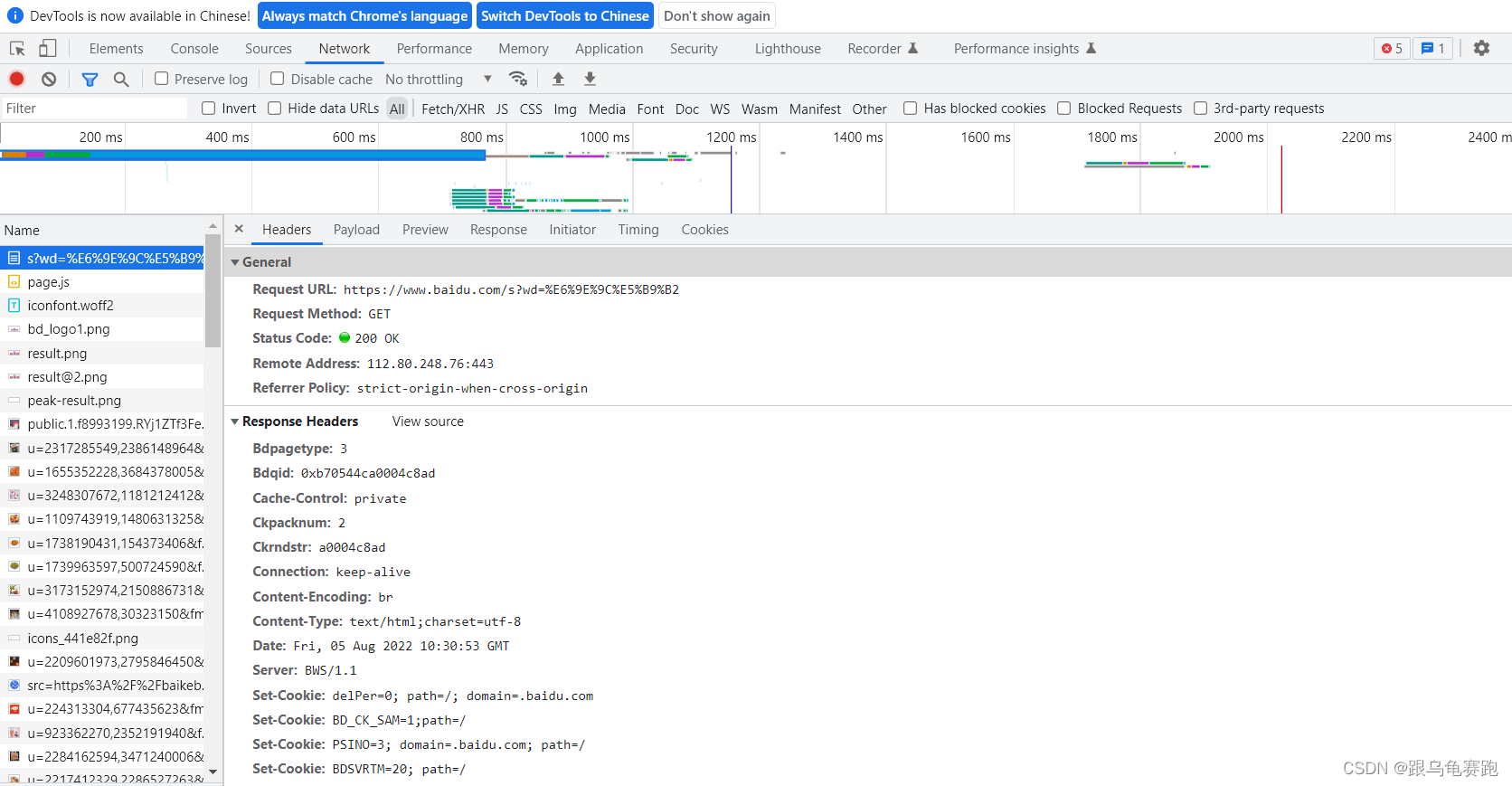
如图就找到了headers
2.爬虫工具requests与lxml访问该网站
判断字串是“百度百科”收录词条与判断在搜索页面的文本中出现的次数是否超过60
#!usr/bin/env python
# -*- coding:utf-8 -*-
"""
@author: admin
@file: test_pachong.py
@time: 2022/08/05
@desc:
"""
import re
import requests
from lxml import etree
headers = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, sdch, b',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.133 Safari/537.'
}
# 访问百度百科词条
word = "果干"
urlbase = 'https://www.baidu.com/s?wd=' + word
dom = requests.get(urlbase, headers=headers)
ct = dom.text
num = ct.count(word)
print(num)
html = dom.content
selector = etree.HTML(html)
n = 0
if selector.xpath('//h3[@class="t c-gap-bottom-small"]'):
ct = ''.join(selector.xpath('//h3[@class="t c-gap-bottom-small"]//text()'))
lable = re.findall(u'(.*)_百度百科', ct)
for w in lable:
w = w.strip()
if w == word:
n += 1
print(n)
298
0
















 2123
2123











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











