







PyTorch基础篇:
- PyTorch基础知识 | 安装 | 张量 | 自动求导
- PyTorch主要组成模块 | 数据读入 | 数据预处理 | 模型构建 | 模型初始化 | 损失函数 | 优化器 | 训练与评估
- PyTorch主要组成模块 | hook函数 | 正则化weight decay与Dropout | 标准化
- PyTorch模型定义 | 模型容器 | 模型块 | 修改模型 | 模型读取与保存
- PyTorch进阶技巧 | 自定义损失函数 | 动态调整学习率 | 模型微调 | 半精度训练 | 使用argparse进行调参
- PyTorch可视化 | 可视化网络结构 | 使用TensorBoard可视化训练过程
一、深度学习任务框架
回顾我们在完成一项机器学习任务时的步骤,首先需要对数据进行预处理,其中重要的步骤包括数据格式的统一和必要的数据变换,同时划分训练集和测试集。接下来选择模型,并设定损失函数和优化方法,以及对应的超参数(当然可以使用sklearn这样的机器学习库中模型自带的损失函数和优化器)。最后用模型去拟合训练集数据,并在验证集/测试集上计算模型表现。
深度学习和机器学习在流程上类似,但在代码实现上有较大的差异。首先,由于深度学习所需的样本量很大,一次加载全部数据运行可能会超出内存容量而无法实现;同时还有批(batch)训练等提高模型表现的策略,需要每次训练读取固定数量的样本送入模型中训练,因此深度学习在数据加载上需要有专门的设计。
在模型实现上,深度学习和机器学习也有很大差异。由于深度神经网络层数往往较多,同时会有一些用于实现特定功能的层(如卷积层、池化层、批正则化层、LSTM层等),因此深度神经网络往往需要“逐层”搭建,或者预先定义好可以实现特定功能的模块,再把这些模块组装起来。这种“定制化”的模型构建方式能够充分保证模型的灵活性,也对代码实现提出了新的要求。
接下来是损失函数和优化器的设定。这部分和经典机器学习的实现是类似的。但由于模型设定的灵活性,因此损失函数和优化器要能够保证反向传播能够在用户自行定义的模型结构上实现。
上述步骤完成后就可以开始训练了。我们前面介绍了GPU的概念和GPU用于并行计算加速的功能,不过程序默认是在CPU上运行的,因此在代码实现中,需要把模型和数据“放到”GPU上去做运算,同时还需要保证损失函数和优化器能够在GPU上工作。如果使用多张GPU进行训练,还需要考虑模型和数据分配、整合的问题。此外,后续计算一些指标还需要把数据“放回”CPU。这里涉及到了一系列有关于GPU的配置和操作。
深度学习中训练和验证过程最大的特点在于读入数据是按批的,每次读入一个批次的数据,放入GPU中训练,然后将损失函数反向传播回网络最前面的层,同时使用优化器调整网络参数。这里会涉及到各个模块配合的问题。训练/验证后还需要根据设定好的指标计算模型表现。
总结来说,打通深度学习流程需要搞懂以下几个部分:
- 数据读入
- 模型构建
- 模型初始化
- 损失函数
- 优化器
- 训练和评估
二、数据读入
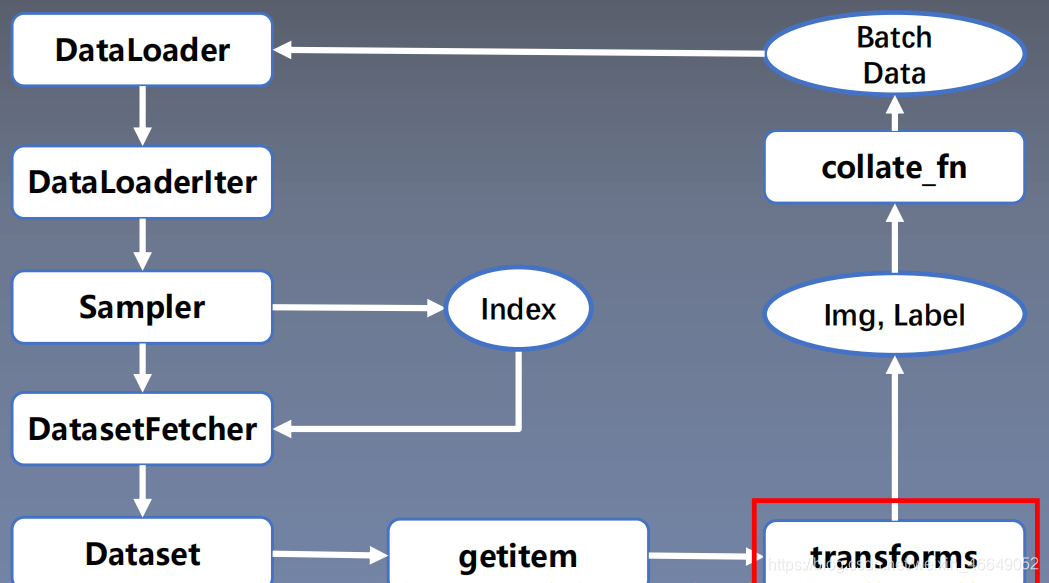
PyTorch数据读取在Dataloader模块下,Dataloader又可以分为DataSet与Sampler。Sampler模块的功能是生成索引(样本序号);DataSet是依据索引读取Img、Lable。数据读入主要是通过Dataset+DataLoader的方式完成的,Dataset定义好数据的格式和数据变换形式,DataLoader用iterative的方式不断读入批次数据。
torch.utils.data.DataLoader():构建可迭代的数据装载器
DataLoader(dataset,
batch_size=1,shuffle=False,sampler=None,
batch_sampler=None,num_workers=0,
collate_fn=None,pin_memory=False,drop_last=False,timeout=0,
worker_init_fn=None,
multiprocessing_context=None)
dataset: Dataset类,决定数据从哪读取及如何读取batch_size:批大小num_works:是否多进程读取数据shuffle:每个epoch是否乱序drop_last:当样本数不能被batchsize整除时,是否舍弃最后一批数据
Epoch:所有训练样本都已输入到模型中,称为一个Epoch
Iteration:一批样本输入到模型中,称之为一个lteration
Batchsize:批大小,决定一个Epoch有多少个lteration
- 样本总数:80,Batchsize : 8
1 Epoch = 10 lteration- 样本总数:87, Batchsize: 8
1 Epoch = 10 lteration ? drop_last = True
1 Epoch = 11 lteration drop_last = False
torch.utils.data.Dataset():Dataset抽象类,所有自定义的Dataset需要继承它,并且复写__getitem__()
getitem:接收一个索引,返回一个样本
class Dataset(object):
def __getitem__(self,index):
raise NotImplementedError
def __add__(self, other) :
return ConcatDataset([self, other])
数据读取流程如下:

我们可以定义自己的Dataset类来实现灵活的数据读取,定义的类需要继承PyTorch自身的Dataset类。主要包含三个函数:
__init__: 用于向类中传入外部参数,同时定义样本集__getitem__: 用于逐个读取样本集合中的元素,可以进行一定的变换,并将返回训练/验证所需的数据__len__: 用于返回数据集的样本数
class RMBDataset(Dataset):
def __init__(self, data_dir, transform=None):
"""
rmb面额分类任务的Dataset
:param data_dir: str, 数据集所在路径
:param transform: torch.transform,数据预处理
"""
self.label_name = {
"1": 0, "100": 1}
self.data_info = self.get_img_info(data_dir) # data_info存储所有图片路径和标签,在DataLoader中通过index读取样本
self.transform = transform
def __getitem__(self, index):
# 根据索引index获得数据与标签
path_img, label = self.data_info[index]
img = Image.open(path_img).convert('RGB') # 0~255
if self.transform is not None:
img = self.transform(img) # 在这里做transform,转为tensor等等
return img, label
def __len__(self):
return len(self.data_info)
@staticmethod
def get_img_info(data_dir):
data_info = list()
# 遍历一个目录内,各个子目录与子文件
for root, dirs, _ in os.walk(data_dir):
# 遍历类别
for sub_dir in dirs:
img_names = os.listdir(os.path.join(root, sub_dir))
img_names = list(filter(lambda x: x.endswith('.jpg'), img_names))
# 遍历图片
for i in range(len(img_names)):
img_name = img_names[i]
path_img = os.path.join(root, sub_dir, img_name)
label = rmb_label[sub_dir]
data_info.append((path_img, int(label)))
return data_info
构建好Dataset后,就可以使用DataLoader来按批次读入数据了,实现代码如下:
from torch.utils.data import DataLoader
train_loader = torch.utils.data.DataLoader(train_data, batch_size=batch_size, num_workers=4, shuffle=True, drop_last=True)
val_loader = torch.utils.data.DataLoader(val_data, batch_size=batch_size, num_workers=4, shuffle=False)
其中:
batch_size:样本是按“批”读入的,batch_size就是每次读入的样本数num_workers:有多少个进程用于读取数据shuffle:是否将读入的数据打乱drop_last:对于样本最后一部分没有达到批次数的样本,使其不再参与训练
数据整理器将数据由下面的形式:
转化为batch形式:

三、数据预处理模块—transforms
1.数据预处理transforms模块机制
torchvision.transforms模块包含了很多图像预处理方法:
- 数据中心化
- 数据标准化
- 缩放
- 裁剪
- 旋转
- 翻转
- 填充
- 噪声添加
- 灰度变换
- 线性变换
- 仿射变换
- 亮度、饱和度及对比度变换
这个模块可以进行数据增强与数据预处理,增强模型的泛化能力。数据预处理transforms在数据读取过程中,最后生成数据预处理完的batch data。
class RMBDataset(Dataset):
def __init__(self, data_dir, transform=None):
"""
rmb面额分类任务的Dataset
:param data_dir: str, 数据集所在路径
:param transform: torch.transform,数据预处理
"""
self.label_name = {
"1": 0, "100": 1}
self.data_info = self.get_img_info(data_dir) # data_info存储所有图片路径和标签,在DataLoader中通过index读取样本
self.transform = transform
def __getitem__(self, index):
path_img, label = self.data_info[index]
img = Image.open(path_img).convert('RGB') # 0~255
# 在数据读取的这个节点开始调用transform,迭代使用多种tansform方法
if self.transform is not None:
img = self.transform(img) # 在这里做transform,转为tensor等等
return img, label
def __len__(self):
return len(self.data_info)
@staticmethod
def get_img_info(data_dir):
data_info = list()
for root, dirs, _ in os.walk(data_dir):
# 遍历类别
for sub_dir in dirs:
img_names = os.listdir(os.path.join(root, sub_dir))
img_names = list(filter(lambda x: x.endswith('.jpg'), img_names))
# 遍历图片
for i in range(len(img_names)):
img_name = img_names[i]
path_img = os.path.join(root, sub_dir, img_name)
label = rmb_label[sub_dir]
data_info.append((path_img, int(label)))
return data_info
2.二十二种transforms数据预处理方法
1.裁剪
transforms.CenterCrop:从图像中心裁剪图片。
size:所需裁剪图片尺寸
transforms.RandomCrop:从图片中随机裁剪出尺寸为size的图片。
transforms.RandomCrop(size,
padding=None,
pad_if_needed=False,fill=6,
padding_mode= 'constant ' )
size:所需裁剪图片尺寸padding:设置填充大小
当为a时,上下左右均填充a个像素
当为(a, b)时,上下填充b个像素,左右填充a个像素
当为(a,b,c,d)时,左,上,右,下分别填充a, b,c, dpad_if_need:若图像小于设定size,则填充padding_mode:填充模式,有4种模式
1、constant:像素值由fill设定
2、edge:像素值由图像边缘像素决定
3、reflect:镜像填充,最后一个像素不镜像,eg:[1,2,3.4] →[3,2,1,2,3,4,3,2]
4、symmetric:镜像填充,最后一个像素镜像,eg:[1,2,3,4]→[2,1,1,2,3,4,4,3]fill:constant时,设置填充的像素值
transforms.RandomResizedCrop:随机大小、长宽比裁剪图片。
RandomResizedCrop(size,
scale=(0.08,1.0),
ratio=(3/4,4/3),interpolation)
size:所需裁剪图片尺寸scale:随机裁剪面积比例,默认(0.08,1)ratio:随机长宽比,默认(3/4,4/3)interpolation:插值方法PIL.lmage.NEARESTPIL.lmage.BILINEARPIL.lmage.BICUBIC
transforms.FiveCrop:在图像的上下左右以及中心裁剪出尺寸为size的5张图片。
transforms .FiveCrop(size)
# 将tuple格式转换为Tensor格式
transforms.FiveCrop(112),
transforms.Lambda(lambda crops: torch.stack([(transforms.ToTensor()(crop)) for crop in crops]))
transforms.TenCrop:TenCrop对这5张图片进行水平或者垂直镜像获得10张图片
size:所需裁剪图片尺寸vertical_flip:是否垂直翻转
transforms.TenCrop(112, vertical_flip=False),
transforms.Lambda(lambda crops: torch.stack([(transforms.ToTensor()(crop)) for crop in crops]))
2. 翻转与旋转
transforms.RandomHorizontalFlip:依概率水平(左右)翻转图片
transforms.RandomHorizontalFlip(p=0.5)
p:翻转概率
transforms.RandomVerticalFlip:依概率垂直(上下)翻转图片
transforms.RandomVerticalFlip(p=0.5)
p:翻转概率
transforms.RandomRotation:随机旋转图片
RandomRotation(degrees,
resample=False,expand=False,
center=None)
degrees:旋转角度
当为a时,在(-a,a)之间选择旋转角度
当为(a,b)时,在(a,b)之间选择旋转角度resample:重采样方法expand:是否扩大图片,以保持原图信息
3.图像变换
transforms.Pad:对图片边缘进行填充。
transforms.Pad(padding,
fill=0,
padding_mode= ' constant ' )
padding:设置填充大小
当为a时,上下左右均填充a个像素
当为(a, b)时,上下填充b个像素,左右填充a个像素
当为(a,b,c,d)时,左,上,右,下分别填充a,b,c,dpadding_mode:填充模式,有4种模式,
constant、edge、reflect和symmetricfill:constant时,设置填充的像素值,(R,G,B)or(Gray)
transforms.colorjitter:调整亮度、对比度、饱和度和色相。
transforms.colorJitter(brightness=0,
contrast=0,
saturation=0,
hue=0)
brightness:亮度调整因子
当为a时,从[max(0,1-a),1+a]中随机选择
当为(a,b)时,从[a,b]中随机选择contrast:对比度参数,同brightnesssaturation:饱和度参数,同brightnesshue:色相参数,
当为a时,从[-a,a]中选择参数,
注:0<= a <= 0.5
当为(a,b)时:,从[a,b]中选择参数
注:-0.5<=a<=b<=0.5
transforms.Grayscale:将图片转换为灰度图
Grayscale(num_output_channels)
num_ouput_channels:输出通道数 只能设1或3
transforms.RandomGrayscale:依概率将图片转换为灰度图
num_ouput_channels:输出通道数 只能设1或3p︰概率值,图像被转换为灰度图的概率
transforms.RandomAffine:对图像进行仿射变换,仿射变换是二维的线性变换,由五种基本原子变换构成,分别是旋转、平移、缩放、错切和翻转
transforms.RandomAffine(degrees,
translate=None,scale=None,
shear=None ,resample=False,fillcolor=)
degrees:旋转角度设置translate:平移区间设置
如(a,b),a设置宽(width),b设置高(height)图像在宽维度平移的区间为
-img_width * a < dx < img_width * ascale:缩放比例(以面积为单位)fill_color:填充颜色设置shear:错切角度设置,有水平错切和垂直错切
若为a,则仅在x轴错切,错切角度在(-a, a)之间
若为(a, b),则a设置x轴角度,b设置y的角度
若为(a, b,c,d),则a, b设置x轴角度,c,d设置y轴角度resample:重采样方式,有NEAREST 、BILINEAR、BICUBIC
transforms.RandomErasing:对图像进行随机遮挡。
transforms.RandomErasing(p=0.5,
scale=(0.02,0.33),
ratio=(0.3,3.3),value=0,
inplace=False)
p:概率值,执行该操作的概率scale:遮挡区域的面积ratio:遮挡区域长宽比value:设置遮挡区域的像素值,(R,G,B) or (Gray)
transforms.Lambda(lambda):用户自定义lambda方法。
lambd: lambda匿名函数
lambda [arg1 [,arg2, … , argn]] : expression
eg:
transforms. Lambda(lambda crops: torch.stack([transforms. Totensor()(crop) for crop in crops]))
4.transforms方法的选择操作
transforms.RandomChoice:从一系列transforms方法中随机挑选一个
transforms. RandomChoice([transforms1,transforms2,transforms3])
transforms.RandomApply:依据概率执行一组transforms操作
transforms.RandomApply([transforms1,transforms2,transforms3], p=0.5)
transforms.RandomOrder::对一组transforms操作打乱顺序
transforms. Randomorder([transforms1,transforms2,transforms3])
transforms.Resize:调整图片的大小
transforms.Totensor:将之前的数据结构转换为张量
transforms.Normalize:逐channel的对图像进行标准化(变换后的数据均值为0,标准差为1),标准化的优点是加快模型的收敛。
transforms.Normalize(mean,
std,
inplace=False)
o u t p u t = ( i n p u t − m e a n ) / s t d output = (input - mean) / std output=(input−mean)/std
mean:各通道的均值std:各通道的标准差inplace:是否原地操作
源码如下:
def normalize(tensor, mean, std, inplace=False):
"""Normalize a tensor image with mean and standard deviation.
.. note::
This transform acts out of place by default, i.e., it does not mutates the input tensor.
See :class:`~torchvision.transforms.Normalize` for more details.
Args:
tensor (Tensor): Tensor image of size (C, H, W) to be normalized.
mean (sequence): Sequence of means for each channel.
std (sequence): Sequence of standard deviations for each channel.
inplace(bool,optional): Bool to make this operation inplace.
Returns:
Tensor: Normalized Tensor image.
"""
# 输入的合法性判断-是否为Tensor
if not _is_tensor_image(tensor):
raise TypeError('tensor is not a torch image.')
# 是否原地操作,如果不是原地操作,需要将张量克隆一份
if not inplace:
tensor = tensor.clone()
dtype = tensor.dtype
# 将均值与方差转化为张量
mean = torch.as_tensor(mean, dtype=dtype, device=tensor.device)
std = torch.as_tensor(std, dtype=dtype, device=tensor.device)
# sub_:下划线表示原地操作;(input - mean) / std
tensor.sub_(mean[:, None, None]).div_(std[:, None, None])
# 返回变换后的张量
return tensor
5.自定义transfroms方法
transforms方法是在Compose类中通过__call__方法调用的。
class Compose(object):
"""Composes several transforms together.
Args:
transforms (list of ``Transform`` objects): list of transforms to compose.
Example:
>>> transforms.Compose([
>>> transforms.CenterCrop(10),
>>> transforms.ToTensor(),
>>> ])
"""
def __init__(self, transforms):
self.transforms = transforms
def __call__(self, img):
# 循环执行transforms方法
for t in self.transforms:
img = t(img)
return img
def __repr__(self):
format_string = self.__class__.__name__ + '('
for t in self.transforms:
format_string += '\n'
format_string += ' {0}'.format(t)
format_string += '\n)'
return format_string
我们可以发现调用transforms时有如下特点:
- 仅接收一个参数,返回一个参数
- 注意上下游的输出与输入
下面我们自定义transforms,它的基本结构为:
class YourTransforms(object) :
def __init_(self, ...):
...
def __cal1__(self, img):
...
return img
椒盐噪声又称为脉冲噪声,是一种随机出现的白点或者黑点,白点称为盐噪声,黑色为椒噪声。信噪比(Signal-Noise Rate,SNR)是衡量噪声的比例,图像中为图像像素的占比。我们以椒盐噪声为例来自定义transforms方法。
class AddPepperNoise(object):
"""增加椒盐噪声
Args:
snr (float): Signal Noise Rate
p (float): 概率值,依概率执行该操作
"""
def __init__(self, snr, p=0.9):
assert isinstance(snr, float) and (isinstance(p, float)) # 2020 07 26 or --> and
# 信号百分比
self.snr = snr
# 概率
self.p = p
def __call__(self, img):
"""
Args:
img (PIL Image): PIL Image
Returns:
PIL Image: PIL image.
"""
# 概率的判断
if random.uniform(0, 1) < self.p:
# 数据格式转换到ndarray
img_ = np.array(img).copy()
# 高,宽,通道数
h, w, c = img_.shape
# 获取信号百分比
signal_pct = self.snr
# 噪声百分比
noise_pct = (1 - self.snr)
# 依概率选取3个mask
mask = np.random.choice((0, 1, 2), size=(h, w, 1), p=[signal_pct, noise_pct/2., noise_pct/2.])
mask = np.repeat(mask, c, axis=2)
img_[mask == 1] = 255 # 盐噪声
img_[mask == 2] = 0 # 椒噪声
return Image.fromarray(img_.astype('uint8')).convert('RGB')
else:
return img
四、模型构建
1.神经网络构造
Module 类是 nn 模块里提供的一个模型构造类,是所有神经网络模块的基类。
模型构建有两个要素:

下面我们以LeNet模型为例,展示其模型创建过程
class LeNet(nn.Module):
# 初始化构建子模块
def __init__(self, classes):
super(LeNet, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16*5*5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, classes)
# 拼接子模块
def forward(self, x):
out = F.relu(self.conv1(x))
out = F.max_pool2d(out, 2)
out = F.relu(self.conv2(out))
out = F.max_pool2d(out, 2)
out = out.view(out.size(0), -1)
out = F.relu(self.fc1(out))
out = F.relu(self.fc2(out))
out = self.fc3(out)
return out
# 权值的初始化
def initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.xavier_normal_(m.weight.data)
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight.data, 0, 0.1)
m.bias.data.zero_()
但是我们什么时候实现模型的拼接与前向传播呢?LeNet模型继承于Module,Module类中有__call__函数,__call__函数表明这一实例是可以像函数一样被调用的,__call__函数中会调用上面定义好的forword前向传播函数。
# Module类
def __call__(self, *input, **kwargs):
for hook in self._forward_pre_hooks.values():
result = hook(self, input)
if result is not None:
if not isinstance(result, tuple):
result = (result,)
input = result
if torch._C._get_tracing_state():
result = self._slow_forward(*input, **kwargs)
else:
# 前向传播
result = self.forward(*input, **kwargs)
for hook in self._forward_hooks.values():
hook_result = hook(self, input, result)
if hook_result is not None:
result = hook_result
if len(self._backward_hooks) > 0:
var = result
while not isinstance(var, torch.Tensor):
if isinstance(var, dict):
var = next((v for v in var.values() if isinstance(v, torch.Tensor)))
else:
var = var[0]
grad_fn = var.grad_fn
if grad_fn is not None:
for hook in self._backward_hooks.values():
wrapper = functools.partial(hook, self)
functools.update_wrapper(wrapper, hook)
grad_fn.register_hook(wrapper)
return result
net = LeNet(4)
print(net)
LeNet(
(conv1): Conv2d(3, 6, kernel_size=(5, 5), stride=(1, 1))
(conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
(fc1): Linear(in_features=400, out_features=120, bias=True)
(fc2): Linear(in_features=120, out_features=84, bias=True)
(fc3): Linear(in_features=84, out_features=4, bias=True)
)
net(X)
net(X) 会调用LeNet 继承⾃自 Module 类的__call__函数,这个函数将调⽤用 LeNet 类定义的forward 函数来完成前向计算。
2.神经网络中常见的层
深度学习的一个魅力在于神经网络中各式各样的层,例如全连接层、卷积层、池化层与循环层等等。
2.1 卷积层
下面介绍几个概念:
- 卷积运算:卷积核在输入信号(图像)上滑动,相应位置上进行乘加。
- 卷积核:又称为滤波器,过滤器,可认为是某种模式,某种特征。

- 卷积维度:一般情况下,卷积核在几个维度上滑动,就是几维卷积。
PyTorch中提供了1d、2d、3d的卷积。
1d conv:
2d conv:
3d conv:



上述都是一个卷积核在一个信号上的卷积。如果涉及多个卷积核多个信号的操作,那么应该怎么判断卷积的维度?下面我们以一个三维卷积核实现二维卷积为例

每个卷积核分别在各自的通道进行卷积操作得到输出值,然后相加再加上偏置才会得到特征图的一个像素值。一个卷积核只在一个二维图像上进行滑动,所以这是二维卷积。为什么它是三维卷积核?正是因为它有多个通道,在多个通道上分别进行卷积。
-
nn.Conv2d:对多个二维信号进行二维卷积nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode= ' zeros ' )主要参数:
in_channels:输入通道数out_channels:输出通道数,等价于卷积核个数kernel_size:卷积核尺寸stride:步长padding:填充个数,用于保持输入与输出图像的尺寸是匹配的dilation:空洞卷积大小groups:分组卷积设置bias:偏置
尺寸计算公式为:
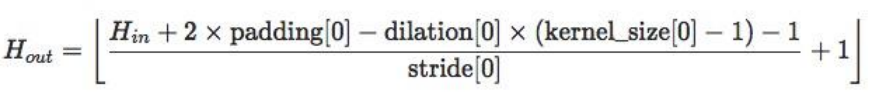
-
nn.ConvTranspose2d
nn.ConvTranspose2d是转置卷积。转置卷积用于对图像进行上采样(UpSample),经常用于图像分割任务。那么,什么是转置卷积?它与正常卷积有什么区别?如图是正常2d卷积。
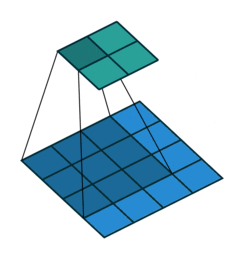
假设图像尺寸为 4 ∗ 4 4*4 4∗4,卷积核为 3 ∗ 3 3*3 3∗3,padding=0,stride=1
图像: 𝟏 𝟔 ∗ 𝟏 𝟏𝟔∗𝟏 16∗1, 卷积核: 𝟒 ∗ 𝟏 𝟔 𝟒∗𝟏𝟔 4∗16 ,输出: 𝟒 ∗ 𝟏 𝟒∗𝟏 4∗1 = ( 𝟒 ∗ 𝟏 𝟔 ) ∗ ( 𝟏 𝟔 ∗ 𝟏 ) (𝟒∗𝟏𝟔) ∗ (𝟏𝟔∗𝟏) (4∗16)∗(16∗1)
如图是转置卷积:

假设图像尺寸为 2 ∗ 2 ,卷积核为 3 ∗ 3 2*2,卷积核为3*3 2∗2,卷积核为3∗3,padding=0,stride=1
图像:𝟒∗𝟏 ,卷积核: 𝟏 𝟔 ∗ 𝟒 𝟏𝟔∗𝟒 16∗4, 输出: 𝟏 𝟔 ∗ 𝟏 = ( 𝟏 𝟔 ∗ 𝟒 ) ∗ ( 𝟒 ∗ 1 ) 𝟏𝟔∗𝟏 = (𝟏𝟔∗𝟒) ∗ (𝟒∗1) 16∗1=(16∗4)∗(4∗1)
与正常卷积相比。转置卷积的卷积核在形状上与正常卷积是转置关系,虽然形状上转置,但是在权值上是完全不相同的,所以,正常卷积与转置卷积是完全不可逆的。
nn.ConvTranspose2d:转置卷积实现上采样。nn.ConvTranspose2d(in_channels, out_channels, kernel_size, stride=1, padding=0, output_padding=0, groups=1, bias=True, dilation=1, padding_mode='zeros')主要参数:
in_channels:输入通道数out_channels:输出通道数kernel_size:卷积核尺寸stride:步长padding:填充个数dilation:空洞卷积大小groups:分组卷积设置bias:偏置
转置卷积的尺寸计算:

转置卷积容易出现棋盘效应,解决办法推荐:《 Deconvolution and Checkerboard Artifacts》
2.2 池化层
池化运算就是对信号进行“收集”并“总结”。常见的池化方法有最大池化与平均池化。根据Boureau理论可以得出结论:在进行特征提取的过程中,均值池化可以减少邻域大小受限造成的估计值方差,但更多保留的是图像背景信息;而最大值池化能减少卷积层参数误差造成估计均值误差的偏移,能更多的保留纹理信息。随机池化虽然可以保留均值池化的信息,但是随机概率值确是人为添加的,随机概率的设置对结果影响较大,不可估计。

-
nn.MaxPool2d:对二维信号(图像)进行最大值池化nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)主要参数:
kernel_size:池化核尺寸stride:步长padding:填充个数dilation:池化核间隔大小ceil_mode:尺寸向上取整return_indices:记录池化像素索引
用于最大值反池化的过程中,将最大值放到对应的位置中
-
nn.AvgPool2d:对二维信号(图像)进行平均值池化nn.AvgPool2d(kernel_size, stride=None, padding=0, ceil_mode=False, count_include_pad=True, divisor_override=None)主要参数:
kernel_size:池化核尺寸stride:步长padding:填充个数ceil_mode:尺寸向上取整count_include_pad:填充值用于计算divisor_override:除法因子(可以根据任务需要,不是设置除以像素个数,而是除以除法因子)
-
nn.MaxUnpool2d:对二维信号(图像)进行最大值池化上采样
前面两个池化操作均是下采样的过程。这里我们介绍上采样池化操作。nn.MaxUnpool2d(kernel_size, stride=None, padding=0) forward(self, input, indices, output_size=None)主要参数:
kernel_size:池化核尺寸stride:步长padding:填充个数
# 初始化图片 img_tensor = torch.randint(high=5, size=(1, 1, 4, 4), dtype=torch.float) # 最大值池化 maxpool_layer = nn.MaxPool2d((2, 2), stride=(2, 2), return_indices=True) img_pool, indices = maxpool_layer(img_tensor) # unpooling # 反池化的输入 img_reconstruct = torch.randn_like(img_pool, dtype=torch.float) # 最大值反池化 maxunpool_layer = nn.MaxUnpool2d((2, 2), stride=(2, 2)) img_unpool = maxunpool_layer(img_reconstruct, indices) print("raw_img:\n{}\nimg_pool:\n{}".format(img_tensor, img_pool)) print("img_reconstruct:\n{}\nimg_unpool:\n{}".format(img_reconstruct, img_unpool))raw_img: tensor([[[[0., 4., 4., 3.], [3., 3., 1., 1.], [4., 2., 3., 4.], [1., 3., 3., 0.]]]]) img_pool: tensor([[[[4., 4.], [4., 4.]]]]) img_reconstruct: tensor([[[[-1.0276, -0.5631], [-0.8923, -0.0583]]]]) img_unpool: tensor([[[[ 0.0000, -1.0276, -0.5631, 0.0000], [ 0.0000, 0.0000, 0.0000, 0.0000], [-0.8923, 0.0000, 0.0000, -0.0583], [ 0.0000, 0.0000, 0.0000, 0.0000]]]])
2.3 线性层
线性层又称全连接层,其每个神经元与上一层所有神经元相连实现对前一层的线性组合,线性变换。
-
nn.Linear:对一维信号(向量)进行线性组合nn.Linear(in_features, out_features, bias=True)主要参数:
in_features:输入结点数out_features:输出结点数bias:是否需要偏置
计算公式: y = 𝒙 𝑾 𝑻 + 𝒃 𝒊 𝒂 𝒔 y = 𝒙𝑾^𝑻 + 𝒃𝒊𝒂𝒔 y=xWT+bias
下面,我们通过代码构建3个输入节点,4个隐藏节点的模型inputs = torch.tensor([[1., 2, 3]]) linear_layer = nn.Linear(3, 4) # 权值矩阵进行初始化 linear_layer.weight.data = torch.tensor([[1., 1., 1.], [2., 2., 2.], [3., 3., 3.], [4., 4., 4.]]) # 增加偏置 linear_layer.bias.data.fill_(0.5) # 输出 output = linear_layer(inputs) print(inputs, inputs.shape) print(linear_layer.weight.data, linear_layer.weight.data.shape) print(output, output.shape)tensor([[1., 2., 3.]]) torch.Size([1, 3]) tensor([[1., 1., 1.], [2., 2., 2.], [3., 3., 3.], [4., 4., 4.]]) torch.Size([4, 3]) tensor([[ 6.5000, 12.5000, 18.5000, 24.5000]], grad_fn=<AddmmBackward>) torch.Size([1, 4])
2.4 激活函数层
激活函数对特征进行非线性变换,赋予多层神经网络具有深度的意义。如果不用非线性激励函数,每一层都是上一层的线性函数,无论神经网络多少层,输出都是输入的线性组合,所以引入非线性激励函数,深层网络就变得有意义了,可以逼近任意函数。
nn.Sigmoid
计算公式: 𝐲 = 𝟏 𝟏 + 𝒆 − x 𝐲 = \frac{𝟏} {𝟏+𝒆^{−x}} y=1+e−x1
梯度公式: 𝒚 ′ = 𝒚 ∗ ( 𝟏 − 𝒚 ) 𝒚′ = 𝒚 ∗ (𝟏 − 𝒚) y′=y∗(1−y)

特性:
- 输出值在(0,1),符合概率
- 导数范围是[0, 0.25],易导致梯度消失
- 输出为非0均值,破坏数据分布
nn.tanh
计算公式:
𝐲 = s i n 𝒙
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 980
980











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











