







1.什么是知识图谱
知识图谱(Knowledge Graph)于2012年由谷歌提出并成功应用于搜索引擎当中。它以结构化的形式描述客观世界中概念、实体及其之间的关系,将互联网的信息表达成更接近人类认知世界的形式,提供了一种更好地组织、管理和理解互联网海量信息的能力。节点表示实体或概念,边表示属性或关系。
下面基于不同视角对知识图谱进行理解:
- Web视角:像建立文本之间的超链接一样,建立数据之间的语义链接,并支持语义搜索。
- NLP视角:怎样从文本中抽取语义和结构化数据。
- KR视角:怎样利用该计算机符号来表示和处理知识。
- AI视角:怎样利用实时库来辅助理解人的语言。
- DB视角:用图的方式去存储知识。
知识图谱通过对错综复杂的文档的数据进行有效的加工、处理、整合,转化为简单、清晰的“实体,关系,实体”的三元组,最后聚合大量知识,从而实现知识的快速响应和推理。
知识图谱有自顶向下和自底向上两种构建方式。所谓自顶向下构建是借助百科类网站等结构化数据源,从高质量数据中提取本体和模式信息,加入到知识库中;所谓自底向上构建,则是借助一定的技术手段,从公开采集的数据中提取出资源模式,选择其中置信度较高的新模式,经人工审核之后,加入到知识库中。
2.组成
常见的知识图谱包含三种节点:实体、概念、属性
实体:是指具备可区别性且独立存在的事物,如一个人、一座城市、一本书等等
概念:是指具有同种特性的实体构成的集合,如宗教、学历、籍贯等等
属性:用于区分概念的特征,不同概念具有不同的属性。属性值主要指对象指定属性的值,不同的属性值类型对应于不同类型属性的边。如果属性值对应的是概念或实体,则属性描述两个实体之间的关系,称为对象属性;如果属性值是具体的数值,则称为数据属性
3.知识图谱的结构
3.1知识图谱的逻辑结构
知识图谱在逻辑上可分为模式层与数据层两个层次,数据层主要是由一系列的事实组成,而知识将以事实为单位进行存储。如果用(实体1,关系,实体2)、(实体、属性,属性值)这样的三元组来表达事实,可选择图数据库作为存储介质,例如开源的Neo4j[7]、Twitter的FlockDB[8]、sones的GraphDB[9]等。模式层构建在数据层之上,是知识图谱的核心,通常采用本体库来管理知识图谱的模式层。本体是结构化知识库的概念模板,通过本体库而形成的知识库不仅层次结构较强,并且冗余程度较小。
3.2 知识图谱的体系架构
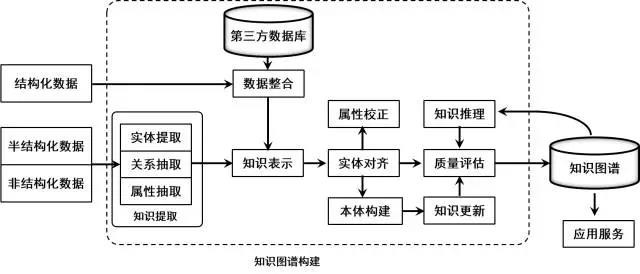
知识图谱的体系架构是其指构建模式结构,如图所示。其中虚线框内的部分为知识图谱的构建过程,也包含知识图谱的更新过程。知识图谱构建从最原始的数据(包括结构化、半结构化、非结构化数据)出发,采用一系列自动或者半自动的技术手段,从原始数据库和第三方数据库中提取知识事实,并将其存入知识库的数据层和模式层,这一过程包含:信息抽取、知识表示、知识融合、知识推理四个过程,每一次更新迭代均包含这四个阶段。通过知识提取技术,可以从一些公开的半结构化、非结构化和第三方结构化数据库的数据中提取出实体、关系、属性等知识要素。知识表示则通过一定有效手段对知识要素表示,便于进一步处理使用。然后通过知识融合,可消除实体、关系、属性等指称项与事实对象之间的歧义,形成高质量的知识库。知识推理则是在已有的知识库基础上进一步挖掘隐含的知识,从而丰富、扩展知识库。分布式的知识表示形成的综合向量对知识库的构建、推理、融合以及应用均具有重要的意义。
3.3原始数据类型
从图中可看出原始数据类型主要包括三种:
1)结构化数据
结构化的数据是指可以使用关系型数据库表示和存储,表现为二维形式的数据。一般特点是:数据以行为单位,一行数据表示一个实体的信息,每一列数据的属性是相同的。例如Mysql中存储的数据。
2)半结构化数据:
半结构化数据是结构化数据的一种形式,它并不符合关系型数据库或其他数据表的形式关联起来的数据模型结构,但包含相关标记,用来分隔语义元素以及对记录和字段进行分层。因此,它也被称为自描述的结构。常见的半结构数据有XML和JSON。
3)非结构化数据:
数据结构不规则或不完整,没有预定义的数据模型,不方便用数据库二维逻辑表来表现的数据。常见的音视频文件等。
3.4信息抽取
从异构数据源中自动抽取信息得到候选知识单元
3.4.1实体抽取
也称为命名实体识别(named entity recognition,NER),是指从文本数据集中自动识别出命名实体
3.4.2关系抽取
文本语料经过实体抽取之后,得到的是一系列离散的命名实体,为了得到语义信息,还需要从相关语料中提取出实体之间的关联关系,通过关系将实体联系起来,才能够形成网状的知识结构。
3.4.3属性抽取
属性抽取的目标是从不同信息源中采集特定实体的属性信息,属性提取的任务是为每个本体语义类构造属性列表(如城市的属性包括面积、人口、所在国家、地理位置等),而属性值提取则为一个语义类的实体附加属性值。属性和属性值的抽取能够形成完整的实体概念的知识图谱维度。常见的属性和属性值抽取方法包括从百科类站点中提取,从垂直网站中进行包装器归纳,从网页表格中提取,以及利用手工定义或自动生成的模式从句子和查询日志中提取。常见的语义类/ 实体的常见属性/ 属性值可以通过解析百科类站点中的半结构化信息(如维基百科的信息盒和百度百科的属性表格)而获得。尽管通过这种简单手段能够得到高质量的属性,但同时需要采用其它方法来增加覆盖率(即为语义类增加更多属性以及为更多的实体添加属性值)
3.5知识表示
传统的知识表示方法主要是以RDF(Resource Description Framework资源描述框架)的三元组SPO(subject,property,object)来符号性描述实体之间的关系。这种表示方法通用简单,受到广泛认可,但是其在计算效率、数据稀疏性等方面面临诸多问题。近年来,以深度学习为代表的以深度学习为代表的表示学习技术取得了重要的进展,可以将实体的语义信息表示为稠密低维实值向量,进而在低维空间中高效计算实体、关系及其之间的复杂语义关联,对知识库的构建、推理、融合以及应用均具有重要的意义。
3.6知识融合
通过知识提取,实现了从非结构化和半结构化数据中获取实体、关系以及实体属性信息的目标。但是由于知识来源广泛,存在知识质量良莠不齐、来自不同数据源的知识重复、层次结构缺失等问题,所以必须要进行知识的融合。知识融合是高层次的知识组织[53],使来自不同知识源的知识在同一框架规范下进行异构数据整合、消歧、加工、推理验证、更新等步骤[54],达到数据、信息、方法、经验以及人的思想的融合,形成高质量的知识库。















 1682
1682

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









