







参考文章
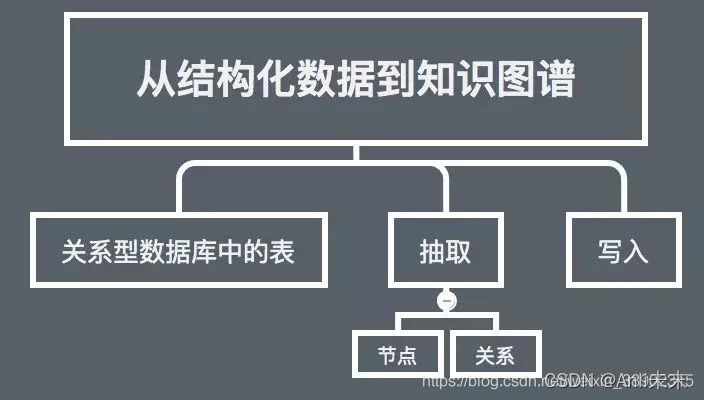
知识图谱构建之二:从结构化数据到知识图谱
# coding: utf-8
#参考链接 https://blog.csdn.net/weixin_38902315/article/details/89848672
from py2neo import Node, Graph, Relationship, NodeMatcher
import pandas as pd
# connect neo4j
graph = Graph("http://127.0.0.1:7474",auth=("neo4j","123456"))
label_1 = "公众号节点"
label_2 = "公众号信息节点"
graph.delete_all()
# step1:read data
#利用pandas读取csv文件
#data = pd.read_csv("./data/raw_data.csv", header=0)
data = pd.read_csv('./data/raw_data.csv',encoding='gbk')
#查看data的行和列
print("查看data的行和列数量",data.shape)
#查看
print("行标题",list(data.columns))
print("查看表的标题\n",data.head)
print("=======================")
#astype()函数可用于转化dateframe某一列的数据类型
#data['建立于'] = data['建立于'].astype('str')
# step2 : extract nodes
#第一类节点:抽取出“公众号名称”字段,去重后转成list。
data[0] = pd.read_csv('./data/raw_data.csv',encoding='gbk',usecols=[0])
node_list = list(set(data[0]))
print("公众号名称字段",node_list)
# step3 : extract nodes
node_info_list = []
#data.columns=['公众号名称', '建立于', '传播', '作者']
for i in list(data.columns)[1:]:
node_info_list.extend(data[i])
#第二类节点:遍历除了“公众号名称”之外的所有字段值,去重后,放进node_info_list中。
node_info_list = list(set(node_info_list))
print("除公众号名称字段",node_info_list)
# step4 : extract relationships
#DataFrame是由多种类型的列构成的二维标签数据结构,DataFrame 是带标签的二维数组
relation_data = pd.DataFrame()
#关系三元组:基于原始的data,列转行抽取关系。
for i in list(data.columns)[1:]:
rel_data = data[["公众号名称", i]]
rel_data["关系"] = i
rel_data.columns = ["公众号节点", "公众号信息节点", "关系"]
relation_data = pd.concat([relation_data, rel_data], axis=0)
print("relation_data的值为\n",relation_data)
'''
#创建节点:create_node遍历节点列表,创建标签为label的节点。
def create_node(node_list, label):
for name in node_list:
print(name)
name_node = Node(label, name=name)
print(name_node)
graph.create(name_node)
create_node(node_list, label_1)
create_node(node_info_list, label_2)
'''
print('开始创建关系:')
#创建关系:create_relation遍历关系数据并创建关系。
def create_relation(relation_data, label_a, label_b):
for m in range(0, len(relation_data)-2):
print("开始创建第 %d 条关系" % (m))
#创建关系Relationship
# graph.nodes.match(self, *labels, **properties): 找到所有的nodes
reValue1 = Node(label_a, property_key=label_a, property_value=str(list(relation_data['公众号节点'])[m]))
graph.create(reValue1)
reValue2 = Node(label_b, property_key=label_b, property_value=str(list(relation_data['公众号信息节点'])[m]))
graph.create(reValue2)
re_V1_V2 = list(relation_data['关系'])[m]
#创建两个节点间的关系relation = Relationship(start_node, relationship, end_node)
rel = Relationship(reValue1,re_V1_V2,reValue2)
graph.merge(rel, label=[label_b, label_a])
create_relation(relation_data, label_1, label_2)
1.使用APOC过程apoc.refactor.mergeNodes(nodes)合并Neo4j中具有相同name属性值的节点
2.安装 APOC 的 jar 包其他包的地址
3.在neo4j中如何查看apoc的jar包
在neo4j中执行
1.Cypher语句–删除所有没有任何关系的节点
MATCH (n)
WHERE size((n)--())=0
DELETE (n)
2.合并
MATCH (n:公众号节点)
WITH toLower(n.property_value) as name, collect(n) as nodes
CALL apoc.refactor.mergeNodes(nodes) yield node
RETURN *
3.合并
MATCH (n:公众号信息节点)
WITH toLower(n.property_value) as name, collect(n) as nodes
CALL apoc.refactor.mergeNodes(nodes) yield node
RETURN *
4.neo4j删除2个节点之间多余的关系,只留一条
MATCH (a)-[r:关系名]->(b)
WITH a, b, TAIL (COLLECT (r)) as rr
WHERE size(rr)>0
FOREACH (r IN rr | DELETE r)
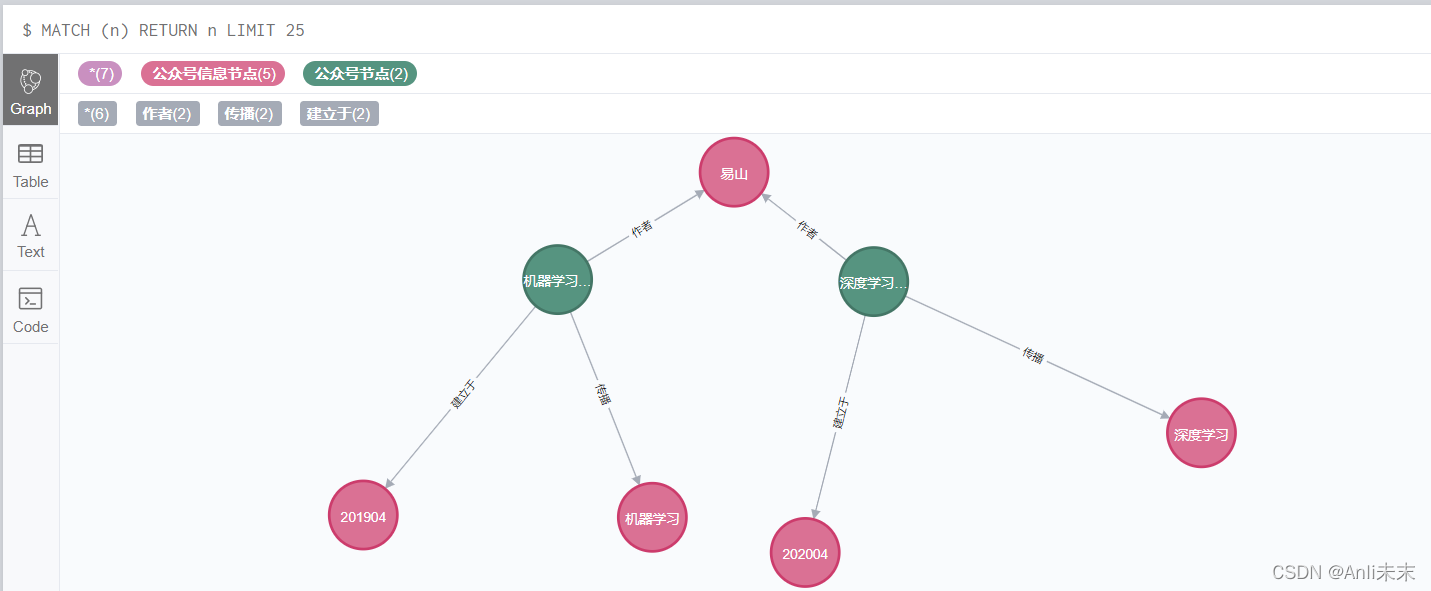
结果图

















 149
149

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









