










目录
字典dict又称散列表(hash),是用来存储键值对的一种数据结构。
Redis整个数据库是用字典来存储的。(K-V结构)
对Redis进行CURD操作其实就是对字典中的数据进行CURD操作。
redis基本数据结构概念
数组
数组:用来存储数据的容器,采用头指针+偏移量的方式能够以O(1)的时间复杂度定位到数据所在的内存地址。
所以Redis海量存储,效率还快
Hash函数
Hash(散列),作用是把任意长度的输入通过散列算法转换成固定类型、固定长度的散列值。
hash函数可以把Redis里的key:包括字符串、整数、浮点数统一转换成整数。
数组下标=hash(key)%数组容量(hash值%数组容量得到的余数)
Hash冲突
不同的key经过计算后出现数组下标一致,称为Hash冲突。
采用单链表在相同的下标位置处存储原始key和value,当根据key找Value时,找到数组下标,遍历单链表可以找出key相同的value
Redis字典的实现
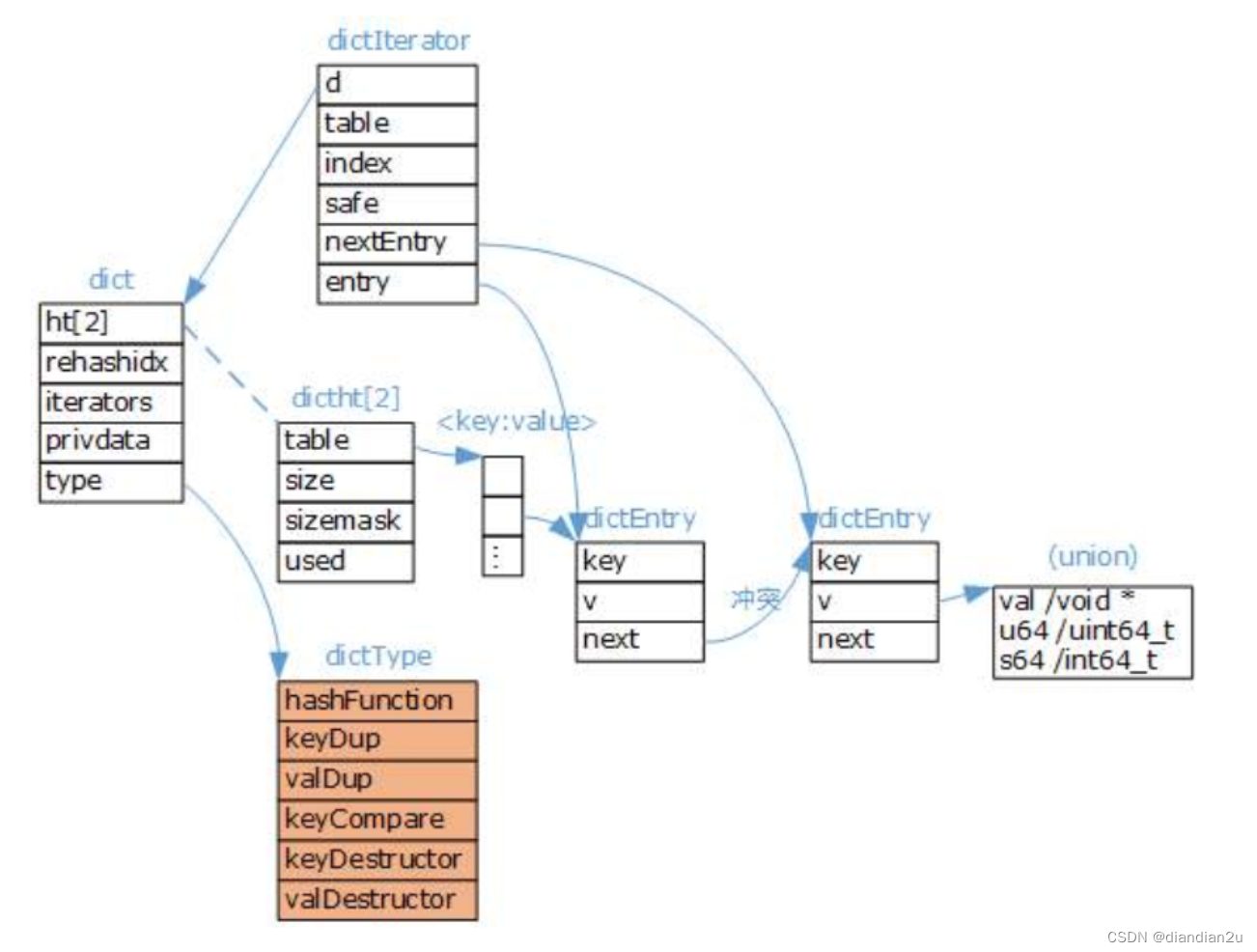
Redis字典实现包括:字典(dict)、Hash表(dictht)、Hash表节点(dictEntry)。

Hash表
typedef struct dictht {
dictEntry **table; //哈希表的数组
unsigned long size; //哈希表数组的大小
unsigned long sizemask; // 用于映射位置的掩码,值永远等于(size-1)
unsigned long used; // 哈希表已有节点的数量,包含next单链表数据
} dictht;
1、hash表的数组初始容量为4,随着k-v存储量的增加需要对hash表数组进行扩容,新扩容量为当前量的一倍,即4,8,16,32
2、索引值=Hash值&掩码值(Hash值与Hash表容量取余)
Hash表节点
typedef struct dictEntry {
void *key; // 键
union { // 值v的类型可以是以下4种类型
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next; // 指向下一个哈希表节点,形成单向链表 解决hash冲突
} dictEntry;
key字段存储的是键值对中的键
v字段是个联合体,存储的是键值对中的值
next指向下一个哈希表节点,用于解决hash冲突

dict字典
typedef struct dict {
dictType *type; // 该字典对应的特定操作函数
void *privdata; // 上述类型函数对应的可选参数
dictht ht[2]; // 两张哈希表,存储键值对数据,ht[0]为原生哈希表,ht[1]为rehash哈希表
long rehashidx; // rehash标识, 等于-1时标识没有在rehash,否则正在rehash,存储的值标识ht[0]的 rehash进行到哪个索引值(数组下标)
int iterators; // 当前运行的迭代器数量
} dict;
type字段,指向dictType结构体,里边包括了对该字典操作的函数指针
完整的Redis字典数据结构:
字典扩容
字典达到存储上限(阈值 0.75),需要rehash(扩容)
扩容流程:
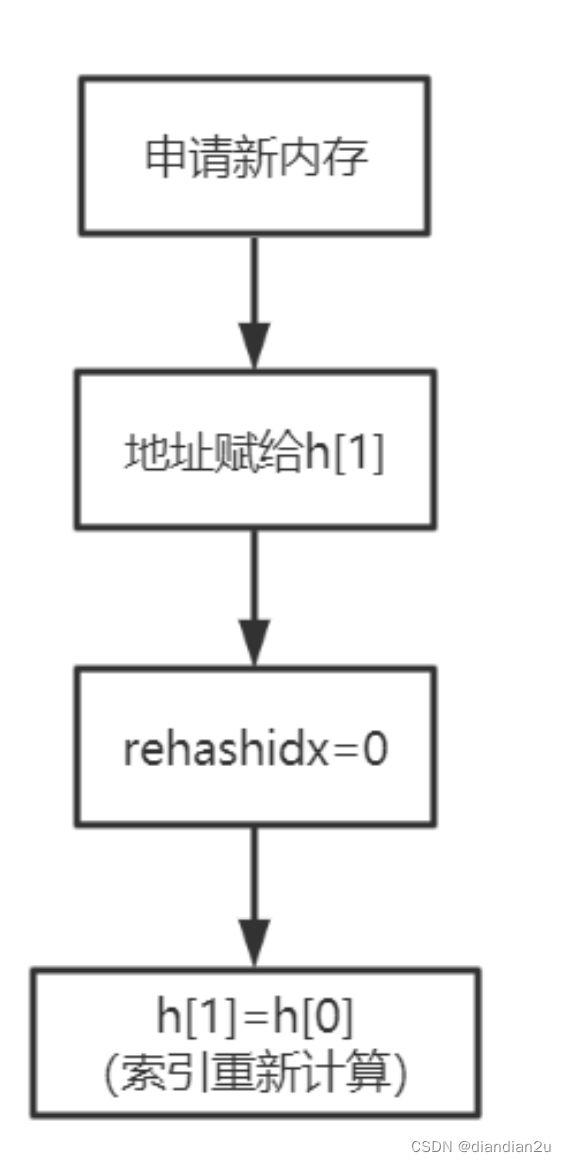
说明:
-
初次申请默认容量为4个dictEntry,非初次申请为当前hash表容量的一倍。
-
rehashidx=0表示要进行rehash操作。
-
新增加的数据在新的hash表h[1]
-
修改、删除、查询在老hash表h[0]、新hash表h[1]中(rehash中)
-
将老的hash表h[0]的数据重新计算索引值后全部迁移到新的hash表h[1]中,这个过程称为 rehash。
渐进式rehash
当数据量巨大时rehash的过程是非常缓慢的,所以需要进行优化。
服务器忙,则只对一个节点进行rehash
服务器闲,可批量rehash(100节点)
应用场景:
1、主数据库的K-V数据存储
2、散列表对象(hash)
3、哨兵模式中的主从节点管理
压缩列表
压缩列表(ziplist)是由一系列特殊编码的连续内存块组成的顺序型数据结构
节省内存
是一个字节数组,可以包含多个节点(entry)。每个节点可以保存一个字节数组或一个整数。
压缩列表的数据结构如下:
 zlbytes:压缩列表的字节长度
zlbytes:压缩列表的字节长度
zltail:压缩列表尾元素相对于压缩列表起始地址的偏移量
zllen:压缩列表的元素个数
entry1..entryX : 压缩列表的各个节点
zlend:压缩列表的结尾,占一个字节,恒为0xFF(255)
entryX元素的编码结构:

previous_entry_length:前一个元素的字节长度
encoding:表示当前元素的编码
content:数据内容
ziplist结构体如下:
struct ziplist<T>{
unsigned int zlbytes; // ziplist的长度字节数,包含头部、所有entry和zipend。
unsigned int zloffset; // 从ziplist的头指针到指向最后一个entry的偏移量,用于快速反向查询
unsigned short int zllength; // entry元素个数
T[] entry; // 元素值
unsigned char zlend; // ziplist结束符,值固定为0xFF
}
typedef struct zlentry {
unsigned int prevrawlensize; //previous_entry_length字段的长度
unsigned int prevrawlen; // previous_entry_length字段存储的内容
unsigned int lensize; // encoding字段的长度
unsigned int len; // 数据内容长度
unsigned int headersize; // 当前元素的首部长度,即previous_entry_length字段长度与encoding字段长度之和。
unsigned char encoding; // 数据类型
unsigned char *p; // 当前元素首地址
} zlentry;
应用场景: sorted-set和hash元素个数少且是小整数或短字符串(直接使用)
list用快速链表(quicklist)数据结构存储,而快速链表是双向列表与压缩列表的组合。(间接使用)
整数集合
整数集合(intset)是一个有序的(整数升序)、存储整数的连续存储结构。
当Redis集合类型的元素都是整数并且都处在64位有符号整数范围内(2^64),使用该结构体存储。
127.0.0.1:6379> sadd set:001 1 3 5 6 2
(integer) 5
127.0.0.1:6379> object encoding set:001
"intset"
127.0.0.1:6379> sadd set:004 1 100000000000000000000000000 9999999999
(integer) 3
127.0.0.1:6379> object encoding set:004
"hashtable"
intset的结构图如下:

typedef struct intset{
//编码方式
uint32_t encoding;
//集合包含的元素数量
uint32_t length;
//保存元素的数组
int8_t contents[];
}intset;
应用场景:
可以保存类型为int16_t、int32_t 或者int64_t 的整数值,并且保证集合中不会出现重复元素。
Set集合使用intset或hashtable作为底层实现。
快速列表
快速列表(quicklist)是Redis底层重要的数据结构。
是列表的底层实现。(在Redis3.2之前,Redis采 用双向链表(adlist)和压缩列表(ziplist)实现。在Redis3.2以后结合adlist和ziplist的优势Redis设计出了quicklist。)
127.0.0.1:6379> lpush list:001 1 2 5 4 3 (integer) 5 127.0.0.1:6379> object encoding list:001 "quicklist"
双向列表(adlist)
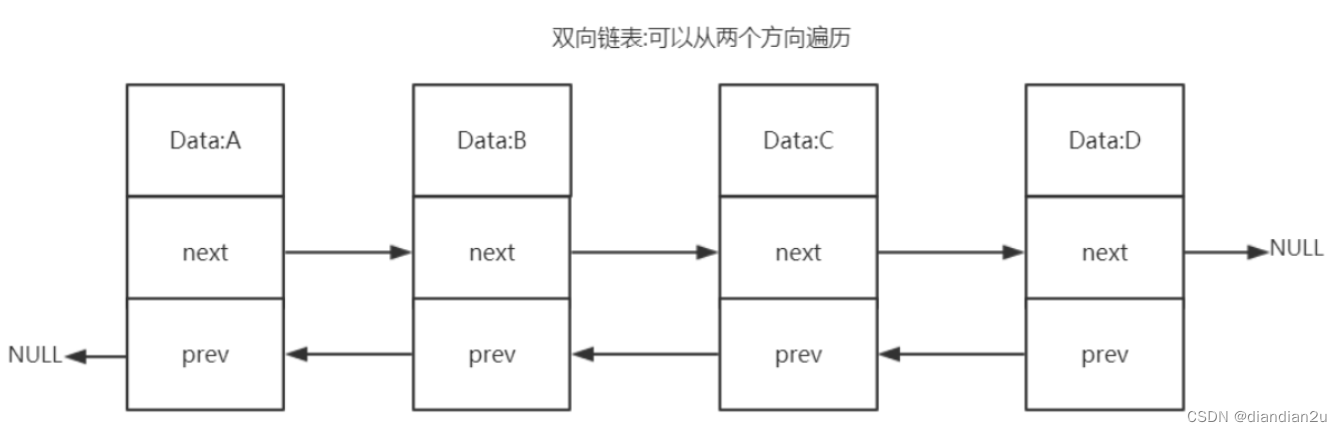
双向链表优势:
-
双向链表具有前置节点和后置节点的引用,获取这两个节点时间复杂度都为O(1)。
普通链表(单链表):节点类保留下一节点的引用。链表类只保留头节点的引用,只能从头节点插入删除
-
无环:表头节点的 prev 指针和表尾节点的 next 指针都指向 NULL,对链表的访问都是以 NULL 结 束。
环状:头的前一个节点指向尾节点
-
带链表长度计数器:通过 len 属性获取链表长度的时间复杂度为 O(1)。
-
多态:链表节点使用 void* 指针来保存节点值,可以保存各种不同类型的值。
快速列表
quicklist是一个双向链表,链表中的每个节点是一个ziplist结构。quicklist中的每个节点ziplist都能够存储多个数据元素。
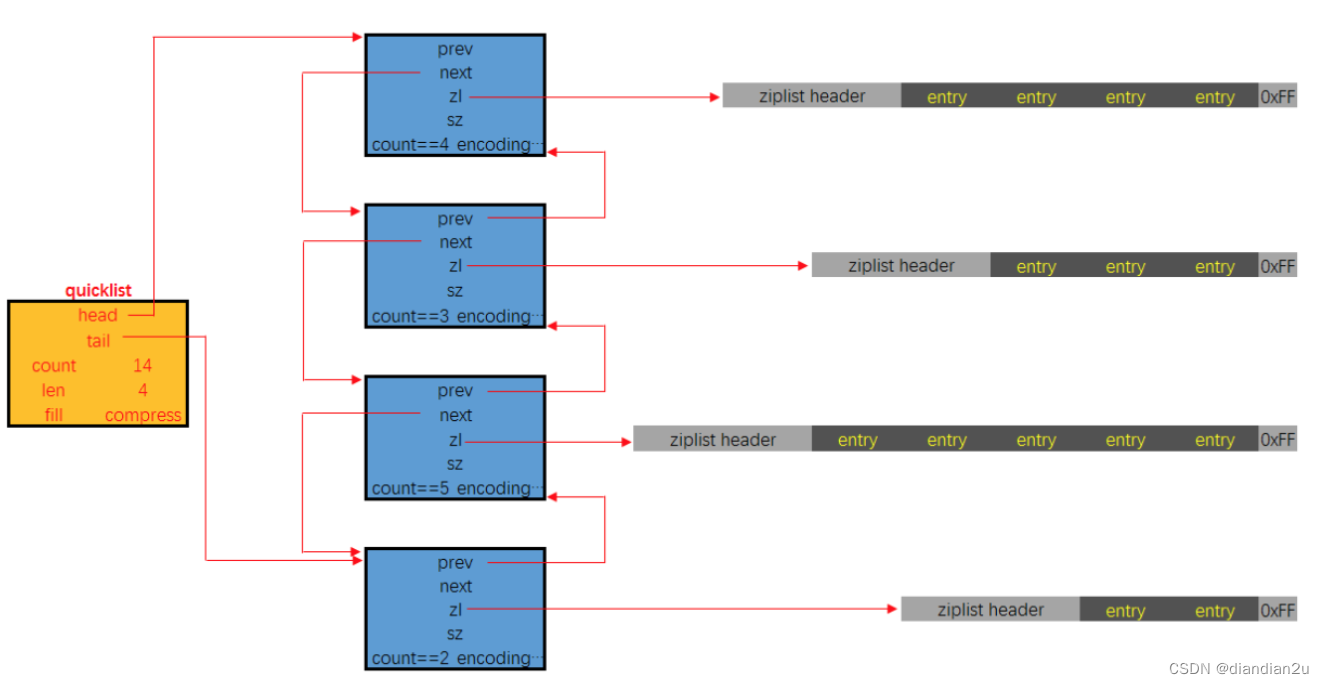
quicklist的结构定义如下:
typedef struct quicklist {
quicklistNode *head; // 指向quicklist的头部
quicklistNode *tail; // 指向quicklist的尾部
unsigned long count; // 列表中所有数据项的个数总和
unsigned int len; // quicklist节点的个数,即ziplist的个数
int fill : 16; // ziplist大小限定,由list-max-ziplist-size给定(Redis限定)
unsigned int compress : 16; // 节点压缩深度设置,由list-compress-depth给定
} quicklist;
quicklistNode的结构定义如下:
typedef struct quicklistNode {
struct quicklistNode *prev; // 指向上一个ziplist节点
struct quicklistNode *next; // 指向下一个ziplist节点
unsigned char *zl; // 数据指针,如果没有被压缩,就指向ziplist结构,反之指向quicklistLZF结构unsigned int sz; // 表示指向ziplist结构的总长度(内存占用长度)
unsigned int count : 16; // 表示ziplist中的数据项个数unsigned int encoding : 2; // 编码方式,1--ziplist,2--quicklistLZF
unsigned int container : 2; // 预留字段,存放数据的方式,1--NONE,2--ziplist
unsigned int recompress : 1; // 解压标记,当查看一个被压缩的数据时,需要暂时解压,标记此参数为1,之后再重新进行压缩
unsigned int attempted_compress : 1; // 测试相关
unsigned int extra : 10; // 扩展字段,暂时没用
} quicklistNode;
数据压缩
quicklist每个节点的实际数据存储结构为ziplist,这种结构的优势在于节省存储空间。为了进一步降低 ziplist的存储空间,还可以对ziplist进行压缩。Redis采用的压缩算法是LZF。其基本思想是:数据与前面重复的记录重复位置及长度,不重复的记录原始数据。
压缩过后的数据可以分成多个片段,每个片段有两个部分:解释字段和数据字段。quicklistLZF的结构体如下:
typedef struct quicklistLZF {
unsigned int sz; // LZF压缩后占用的字节数
char compressed[]; // 柔性数组,指向数据部分
} quicklistLZF;
应用场景
列表(List)的底层实现、发布与订阅、慢查询、监视器等功能。














 432
432











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









