









文章目录
Redis集群与分区
集群的意义:
高可用: 集群的故障转移
高性能:多台计算能力、读写分离
高扩展:横向主机扩展
分区是将数据分布在多个Redis实例(Redis主机)上,以至于每个实例只包含一部分数据。
分区的意义
-
性能的提升
单机Redis的网络I/O能力和计算资源是有限的,将请求分散到多台机器,充分利用多台机器的计算能力
-
存储能力的横向扩展
即使Redis的服务能力能够满足应用需求,但是随着存储数据的增加,单台机器受限于机器本身的存储容量,
将数据分散到多台机器上存储使得Redis服务可以横向扩展。
分区的方式
范围分区和hash分区
范围分区
根据分区键(id)进行分区: 数字的范围比如1–10000、100001–20000…90001-100000,每个范围分到不同的Redis实例中
| id范围 | Redis实例 |
|---|---|
| 1–10000 | Redis01 |
| 100001–20000 | Redis02 |
| … | |
| 90001-100000 | Redis10 |
好处: 实现简单,方便迁移和扩展
缺陷:
-
热点数据分布不均,性能损失
-
非数字型key无法处理,需要保证key的唯一,也要保证key的规则在redis的id范围内
比如uuid可以保证唯一,但不能就能行排序,可采用雪花算法替代,是数字,且能排序,但key比较长
hash分区
利用简单的hash算法: Redis主机位置=hash(key)%N
key:要进行分区的键,比如user_id N:Redis实例个数(Redis主机)
好处:
支持任何类型的key
热点分布较均匀,性能较好
**缺陷: 迁移复杂,需要重新计算,扩展较差(利用一致性hash环) **
client端分区
对于一个给定的key,客户端(需要编程)直接选择正确的节点来进行读写。许多Redis客户端都实现了客户端分区 ( JedisPool),也可以自行编程实现。
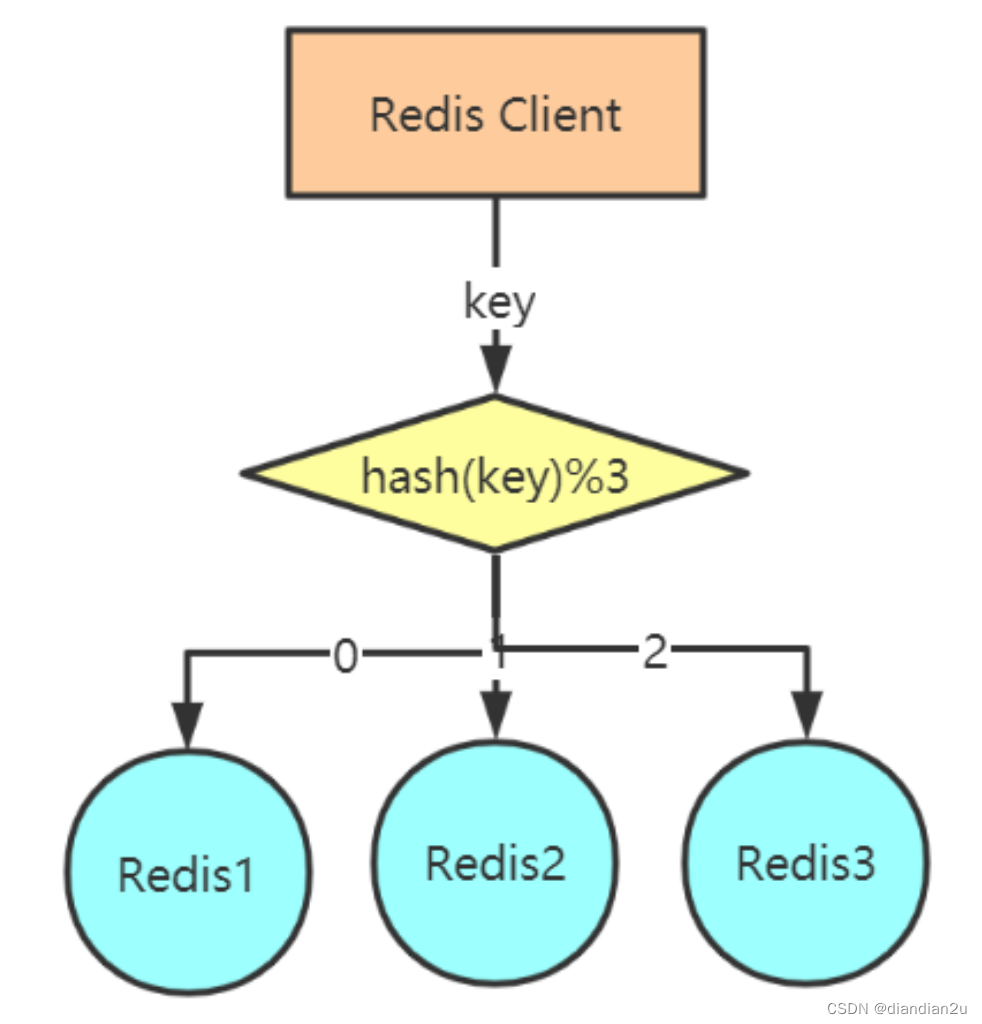
客户端选择算法
hash(普通hash)
hash(key)%N
hash:可以采用hash算法,比如CRC32、CRC16等
N:是Redis主机个数
比如:
user_id : u001
hash(u001) : 1844213068
Redis实例=1844213068%3
余数为2,所以选择Redis3。
普通Hash的优势: 实现简单,热点数据分布均匀
普通Hash的缺陷: 点数固定,扩容的话需要重新计算
查询时必须用分片的key来查,一旦key改变,数据就查不出了,所以要使用不易改变的key进行分片
一致性hash
基本概念
普通hash是对主机数量取模,扩容非常复杂,需要重新计算,那就把主机数量个数扩大些。
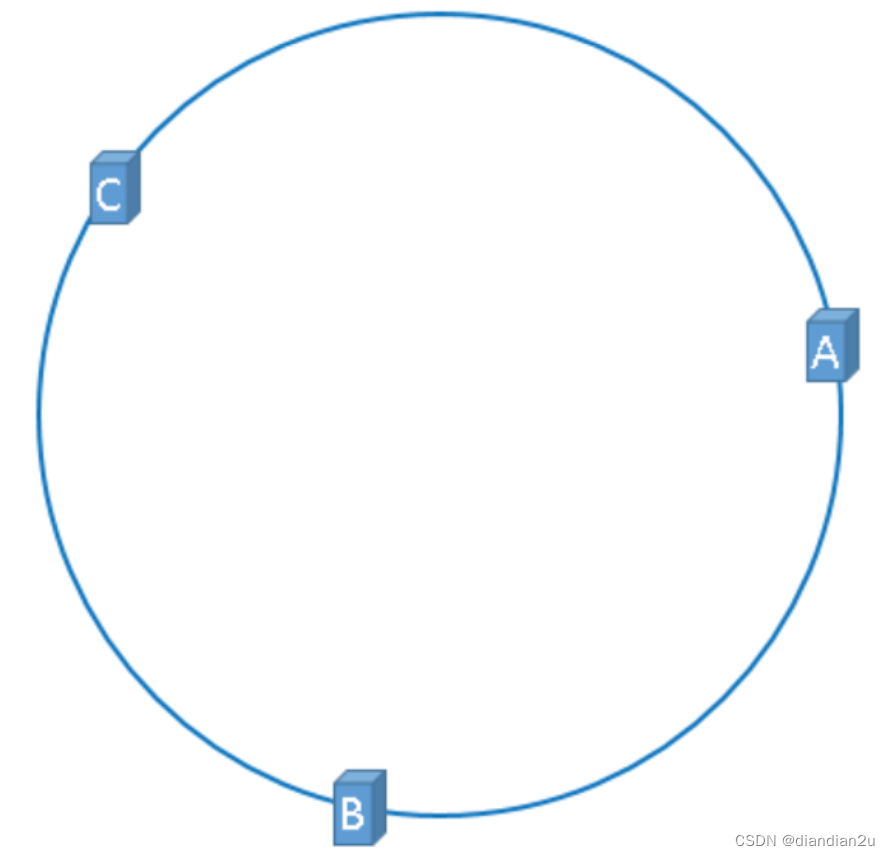
一致性hash是对2^32(4 294 967 296)取模。我们把232想象成一个圆,就像钟表一样,钟表的圆可以理解成由60个点组成的圆,而此处我们把这个圆想象成由232个点组成的圆,示意图如下:

圆环的正上方的点代表0,0点右侧的第一个点代表1,以此类推,2、3、4、5、6…直到232-1,也就是说0点左侧的第一个点代表232-1 。我们把这个由2的32次方个点组成的圆环称为hash环。
假设我们有3台缓存服务器,服务器A、服务器B、服务器C,那么,在生产环境中,这三台服务器肯定有自己的IP地址,我们使用它们各自的IP地址进行哈希计算,使用哈希后的结果对2^32取模,可以使用如下公式:
hash(服务器的IP地址) % 2^32
通过上述公式算出的结果一定是一个0到232-1之间的一个整数,我们就用算出的这个整数,代表服务器A、服务器B、服务器C,既然这个整数肯定处于0到232-1之间,那么,上图中的hash环上必定有一个点与这个整数对应,也就是服务器A、服务器B、服务C就可以映射到这个环上,如下图:
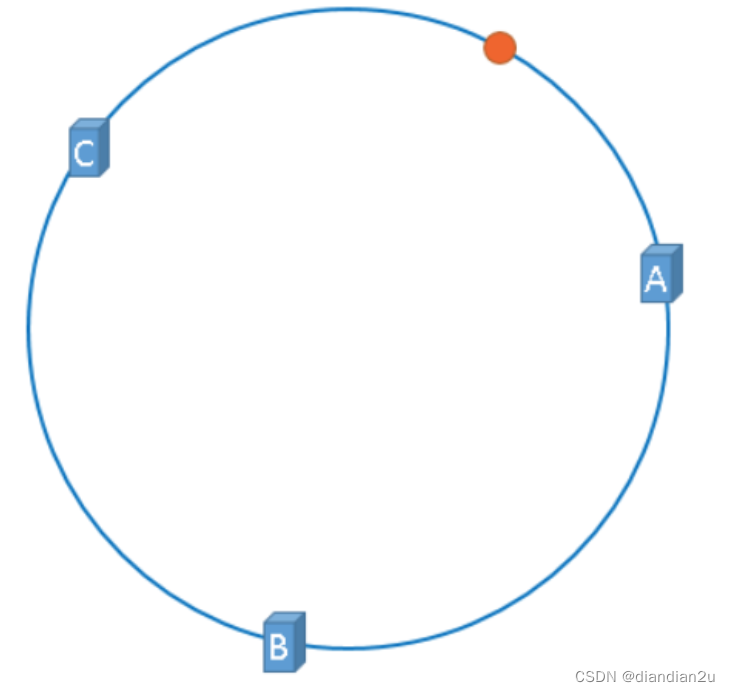
假设,我们需要使用Redis缓存数据,那么我们使用如下公式可以将数据映射到上图中的hash环上。
**hash(key) % 2^32
** 映射后的示意图如下,下图中的橘黄色圆形表示数据
现在服务器与数据都被映射到了hash环上,上图中的数据将会被缓存到服务器A上,因为从数据的位置开始,沿顺时针方向遇到的第一个服务器就是A服务器,所以,上图中的数据将会被缓存到服务器A上。 如图:
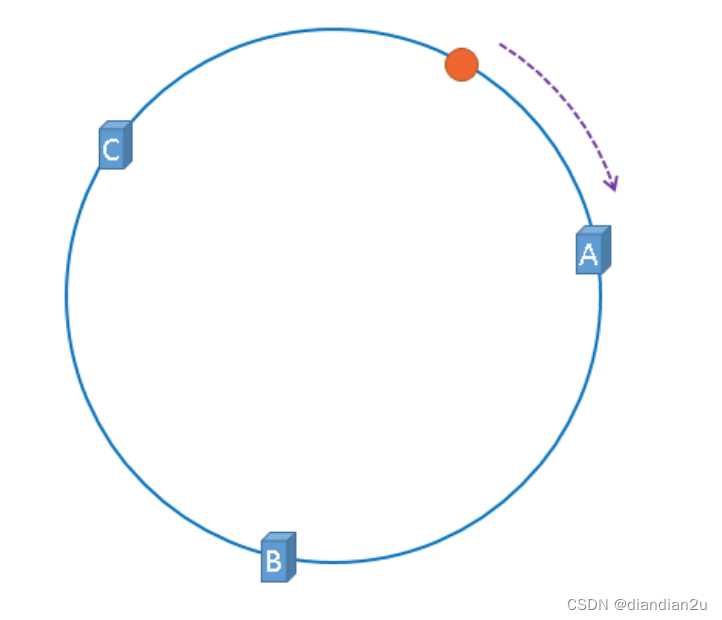
将缓存服务器与被缓存对象都映射到hash环上以后,从被缓存对象的位置出发,沿顺时针方向遇到的第一个服务器,就是当前对象将要缓存的服务器,由于被缓存对象与服务器hash后的值是固定的,所以,在服务器不变的情况下,数据必定会被缓存到固定的服务器上,那么,当下次想要访问这个数据 时,只要再次使用相同的算法进行计算,即可算出这个数据被缓存在哪个服务器上,直接去对应的服务 器查找对应的数据即可。多条数据存储如下:
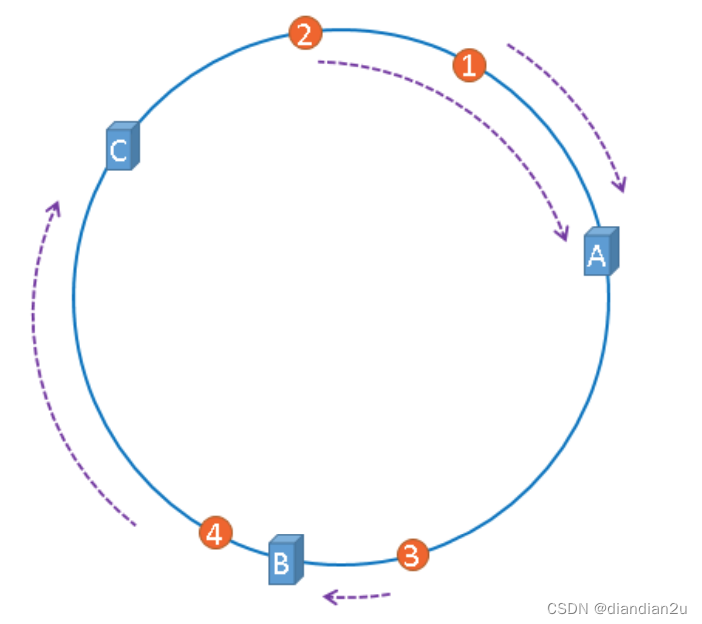
优点
添加或移除节点时,数据只需要做部分的迁移,比如上图中把C服务器移除,则数据4迁移到服务器A中,而其他的数据保持不变。添加效果是一样的。
hash环偏移
在介绍一致性哈希的概念时,我们理想化的将3台服务器均匀的映射到了hash环上。也就是说数据的范围是2^32/N。但实际情况往往不是这样的。有可能某个服务器的数据会很多,某个服务器的数据会很少,造成服务器性能不平均。这种现象称为hash环偏移。

理论上我们可以通过增加服务器的方式来减少偏移,但这样成本较高,所以我们可以采用虚拟节点的方
式,也就是虚拟服务器,如图:
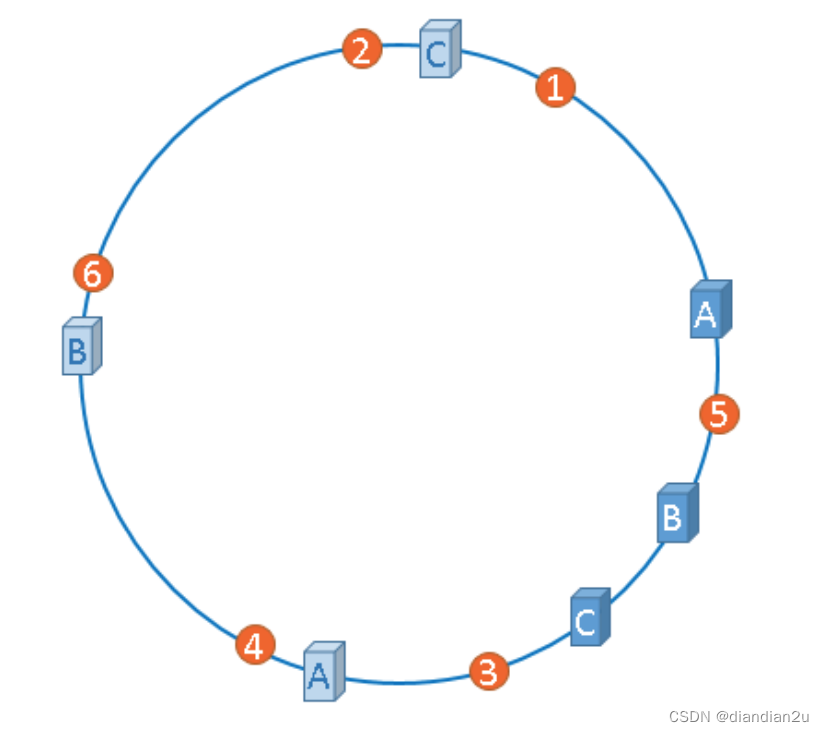
“虚拟节点"是"实际节点”(实际的物理服务器)在hash环上的复制品,一个实际节点可以对应多个虚拟节 点。
从上图可以看出,A、B、C三台服务器分别虚拟出了一个虚拟节点,当然,如果你需要,也可以虚拟出更多的虚拟节点。引入虚拟节点的概念后,缓存的分布就均衡多了,上图中,1号、3号数据被缓存在服务器A中,5号、4号数据被缓存在服务器B中,6号、2号数据被缓存在服务器C中,如果你还不放心,可以虚拟出更多的虚拟节点,以便减小hash环偏斜所带来的影响,虚拟节点越多,hash环上的节点就越 多,缓存被均匀分布的概率就越大。
客户端分区的缺点
复杂度高
客户端需要自己处理数据路由、高可用、故障转移等问题
使用分区数据的处理会变得复杂,不得不应对多个redis数据库和AOF文件,在多个实例和主机之间持久化数据。
不易扩展
普通hash,一旦节点的增或者删操作,都会导致key无法在redis命中,必须重新根据节点计算,并手动迁移全部或部分数据。
proxy端分区
在客户端和服务器端引入一个代理或代理集群,客户端将命令发送到代理上,由代理根据算法,将命令路由到相应的服务器上。常见的代理有Codis(豌豆荚,非原生)和Cluster集群。
目前Codis 不再更新了,所以就不多关注
cluster集群分区
Redis3.0之后,Redis官方提供了完整的集群解决方案。
RedisCluster方案采用去中心化的方式,包括:sharding(分区)、replication(复制)、failover(故障转移)。
Redis5.0前采用redis-trib进行集群的创建和管理,需要ruby支持
Redis5.0之后可以直接使用Redis-cli进行集群的创建和管理
架构
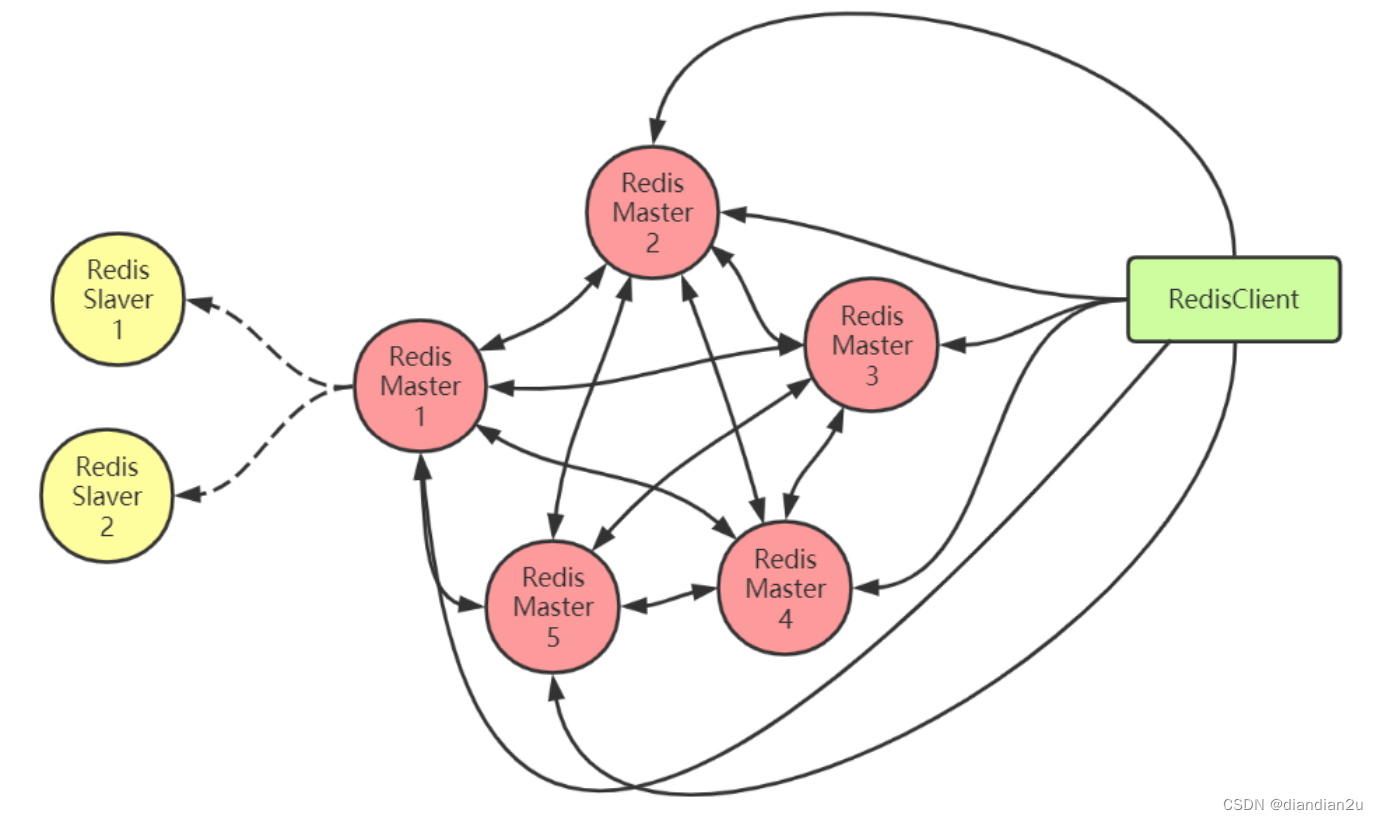
去中心化
RedisCluster由多个Redis节点构成,是一个P2P(点对点)无中心节点的集群架构,依靠Gossip协议传播的集群。
Gossip协议
Gossip协议是一个通信协议,一种传播消息的方式。起源于:病毒传播
Gossip协议基本思想就是:
一个节点周期性(每秒)随机选择一些节点,并把信息传递给这些节点。
这些收到信息的节点接下来会做同样的事情,即把这些信息传递给其他一些随机选择的节点。
信息会周期性的传递给N个目标节点,传递的动作被称为fanout(扇出)
gossip协议包含多种消息,包括meet、ping、pong、fail、publish等等。
| 命令 | 说明 |
|---|---|
| meet | sender向receiver发出,请求receiver加入sender的集群 |
| ping | 节点检测其他节点是否在线 |
| pong | receiver收到meet或ping后的回复信息;在failover后,新的Master也会广播pong |
| fail | 节点A判断节点B下线后,A节点广播B的fail信息,其他收到节点会将B节点标记为下线 |
| publish | 节点A收到publish命令,节点A执行该命令,并向集群广播publish命令,收到publish 命令的节点都会执行相同的publish命令 |
通过gossip协议,cluster可以提供集群间状态同步更新、选举自助failover等重要的集群功能。
分区槽(slot)
redis-cluster把所有的物理节点映射到[0-16383]个slot上,基本上采用平均分配和连续分配的方式。
比如上图中有5个主节点,这样在RedisCluster创建时,slot槽可按下表分配:
| 节点名称 | slot范围 | |
|---|---|---|
| Redis1 | 0-3270 | |
| Redis2 | 3271-6542 | |
| Redis3 | 6543-9814 | |
| Redis4 | 9815-13087 | |
| Redis5 | 13088-16383 |
当需要在 Redis 集群中放置一个 key-value 时,redis 先对 key 使用 crc16 算法算出一个结果,然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,redis 会根据节点数量大致均等的将哈希槽映射到不同的节点。
比如:
set name zhaoyun
hash(“name”)采用crc16算法,得到值:1324203551%16384=15903
根据上表15903在13088-16383之间,所以name被存储在Redis5节点。
slot槽必须在节点上连续分配,如果出现不连续的情况,则RedisCluster不能工作,详见容错。
cluster 负责维护节点和slot槽的对应关系 value------>slot-------->节点
RedisCluster的优势
-
高性能
Redis Cluster 的性能与单节点部署是同级别的。 多主节点、负载均衡、读写分离
-
高可用
Redis Cluster 支持标准的主从复制配置来保障高可用和高可靠。
failover— Redis Cluster 也实现了一个类似 Raft 的共识方式,来保障整个集群的可用性。
-
易扩展
向 Redis Cluster 中添加新节点,或者移除节点,都是透明的,不需要停机。
水平、垂直方向都非常容易扩展
数据分区,海量数据,数据存储
-
原生
部署 Redis Cluster 不需要其他的代理或者工具,而且 Redis Cluster 和单机 Redis 几乎完全兼容。
Redis集群搭建
RedisCluster最少需要三台主服务器,三台从服务器。
端口号分别为:7001~7006
mkdir redis-cluster/7001
make install PREFIX=/var/redis-cluster/7001
cp /var/redis-5.0.5/redis.conf /var/redis-cluster/7001/bin
-
第一步:创建7001实例,并编辑redis.conf文件,修改port为7001。
注意:创建实例,即拷贝单机版安装时,生成的bin目录,为7001目录。
-
第二步:修改redis.conf配置文件,打开cluster-enable yes
-
第三步:复制7001,创建7002~7006实例,注意端口修改。
cp -r /var/redis-cluster/7001/* /var/redis-cluster/7002 cp -r /var/redis-cluster/7001/* /var/redis-cluster/7003 cp -r /var/redis-cluster/7001/* /var/redis-cluster/7004 cp -r /var/redis-cluster/7001/* /var/redis-cluster/7005 cp -r /var/redis-cluster/7001/* /var/redis-cluster/7006 -
第四步:创建start.sh,启动所有的实例
cd 7001/bin ./redis-server redis.conf cd .. cd .. cd 7002/bin ./redis-server redis.conf cd .. cd .. cd 7003/bin ./redis-server redis.conf cd .. cd .. cd 7004/bin ./redis-server redis.conf cd .. cd .. cd 7005/bin ./redis-server redis.conf cd .. cd .. cd 7006/bin ./redis-server redis.conf cd .. cd ..chmod u+x start.sh (赋写和执行的权限)
./start.sh(启动RedisCluster) -
第五步:创建Redis集群(创建时Redis里不要有数据)
# cluster-replicas : 1 1从机 前三个为主 [root@localhost bin]# ./redis-cli --cluster create 192.168.72.128:7001 192.168.72.128:7002 192.168.72.128:7003 192.168.72.128:7004 192.168.72.128:7005 192.168.72.128:7006 --cluster-replicas 1 >>> Performing hash slots allocation on 6 nodes... Master[0] -> Slots 0 - 5460 Master[1] -> Slots 5461 - 10922 Master[2] -> Slots 10923 - 16383 Adding replica 192.168.127.128:7005 to 192.168.127.128:7001 Adding replica 192.168.127.128:7006 to 192.168.127.128:7002 Adding replica 192.168.127.128:7004 to 192.168.127.128:7003 >>> Trying to optimize slaves allocation for anti-affinity [WARNING] Some slaves are in the same host as their master M: 02fdca827762904854293590323bb398e6bee971 192.168.127.128:7001 slots:[0-5460] (5461 slots) master M: 2dddc9d3925d129edd4c6bd5eab3bbad531277ec 192.168.127.128:7002 slots:[5461-10922] (5462 slots) master M: 95598dd50a91a72812ab5d441876bf2ee40ceef4 192.168.127.128:7003 slots:[10923-16383] (5461 slots) master S: 633af51cfdadb907e4d930f3f10082a77b256efb 192.168.127.128:7004 replicates 02fdca827762904854293590323bb398e6bee971 S: 2191b40176f95a2a969bdcaccdd236aa01a3099a 192.168.127.128:7005 replicates 2dddc9d3925d129edd4c6bd5eab3bbad531277ec S: 1d35bec18fcc23f2c555a25563b1e6f2ffa3b0e9 192.168.127.128:7006 replicates 95598dd50a91a72812ab5d441876bf2ee40ceef4 Can I set the above configuration? (type 'yes' to accept): yes >>> Nodes configuration updated >>> Assign a different config epoch to each node >>> Sending CLUSTER MEET messages to join the cluster Waiting for the cluster to join ..... >>> Performing Cluster Check (using node 192.168.127.128:7001) M: 02fdca827762904854293590323bb398e6bee971 192.168.127.128:7001 slots:[0-5460] (5461 slots) master 1 additional replica(s) M: 95598dd50a91a72812ab5d441876bf2ee40ceef4 192.168.127.128:7003 slots:[10923-16383] (5461 slots) master 1 additional replica(s) S: 2191b40176f95a2a969bdcaccdd236aa01a3099a 192.168.127.128:7005 slots: (0 slots) slave replicates 2dddc9d3925d129edd4c6bd5eab3bbad531277ec S: 633af51cfdadb907e4d930f3f10082a77b256efb 192.168.127.128:7004 slots: (0 slots) slave replicates 02fdca827762904854293590323bb398e6bee971 S: 1d35bec18fcc23f2c555a25563b1e6f2ffa3b0e9 192.168.127.128:7006 slots: (0 slots) slave replicates 95598dd50a91a72812ab5d441876bf2ee40ceef4 M: 2dddc9d3925d129edd4c6bd5eab3bbad531277ec 192.168.127.128:7002 slots:[5461-10922] (5462 slots) master 1 additional replica(s) [OK] All nodes agree about slots configuration. >>> Check for open slots... >>> Check slots coverage... [OK] All 16384 slots covered.
命令客户端连接集群
命令:
./redis-cli -h 127.0.0.1 -p 7001 -c
注意:-c 表示是以redis集群方式进行连接
[root@localhost redis-cluster]# cd 7001
[root@localhost 7001]# ./redis-cli -h 127.0.0.1 -p 7001 -c
127.0.0.1:7001> set name1 aaa
-> Redirected to slot [12933] located at 127.0.0.1:7003
OK
127.0.0.1:7003>
查看集群的命令
- 查看集群状态
127.0.0.1:7003> cluster info
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:6
cluster_my_epoch:3
cluster_stats_messages_sent:926
cluster_stats_messages_received:926
- 查看集群中的节点:
127.0.0.1:7003> cluster nodes
d277cd2984639747a17ca79428602480b28ef070 127.0.0.1:7003@17003 myself,master - 0
1570457306000 3 connected 10923-16383
af559fc6c82c83dc39d07e2dfe59046d16b6a429 127.0.0.1:7001@17001 master - 0
1570457307597 1 connected 0-5460
e7b1f1962de2a1ffef2bf1ac5d94574b2e4d67d8 127.0.0.1:7005@17005 slave
068b678923ad0858002e906040b0fef6fff8dda4 0 1570457308605 5 connected
068b678923ad0858002e906040b0fef6fff8dda4 127.0.0.1:7002@17002 master - 0
1570457309614 2 connected 5461-10922
51c3ebdd0911dd6564040c7e20b9ae69cabb0425 127.0.0.1:7004@17004 slave
af559fc6c82c83dc39d07e2dfe59046d16b6a429 0 1570457307000 4 connected
78dfe773eaa817fb69a405a3863f5b8fcf3e172f 127.0.0.1:7006@17006 slave
d277cd2984639747a17ca79428602480b28ef070 0 1570457309000 6 connected
127.0.0.1:7003>
分片
不同节点分组服务于相互无交集的分片(sharding),Redis Cluster 不存在单独的proxy或配置服务器,所以需要将客户端路由到目标的分片。
客户端路由
Redis Cluster的客户端相比单机Redis 需要具备路由语义的识别能力,且具备一定的路由缓存能力。
➜ bin redis-cli -h 127.0.0.1 -p 7001 -c
127.0.0.1:7001> set k2 v2
-> Redirected to slot [449] located at 10.132.1.20:7007
OK
10.132.1.20:7007>
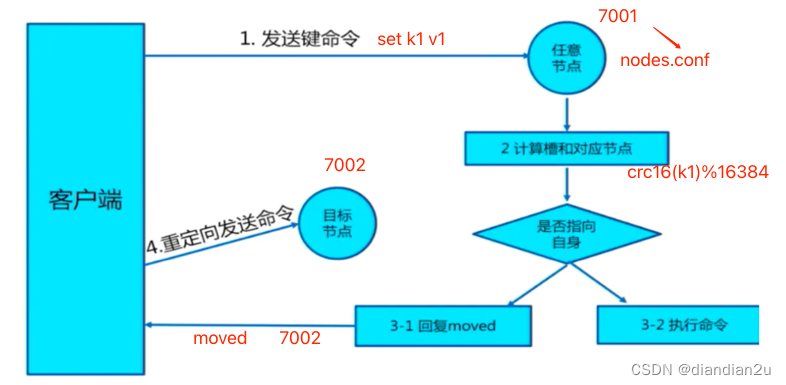
moved重定向
1.每个节点通过通信都会共享Redis Cluster中槽和集群中对应节点的关系
2.客户端向Redis Cluster的任意节点发送命令,接收命令的节点会根据CRC16规则进行hash运算与16384取余,计算自己的槽和对应节点
3.如果保存数据的槽被分配给当前节点,则去槽中执行命令,并把命令执行结果返回给客户端
4.如果保存数据的槽不在当前节点的管理范围内,则向客户端返回moved重定向异常
5.客户端接收到节点返回的结果,如果是moved异常,则从moved异常中获取目标节点的信息
6.客户端向目标节点发送命令,获取命令执行结果
[root@localhost bin]# ./redis-cli -h 127.0.0.1 -p 7001 -c
127.0.0.1:7001> set name:001 zhaoyun
OK
127.0.0.1:7001> get name:001
"zhaoyun"
[root@localhost bin]# ./redis-cli -h 127.0.0.1 -p 7002 -c
127.0.0.1:7002> get name:001
-> Redirected to slot [4354] located at 127.0.0.1:7001
"zhaoyun"
127.0.0.1:7001> cluster keyslot name:001
(integer) 4354
ask重定向
在对集群进行扩容和缩容时,需要对槽及槽中数据进行迁移
当客户端向某个节点发送命令,节点向客户端返回moved异常,告诉客户端数据对应的槽的节点信息
如果此时正在进行集群扩展或者缩空操作,当客户端向正确的节点发送命令时,槽及槽中数据已经被迁移到别的节点了,就会返回ask,这就是ask重定向机制
1.客户端向目标节点发送命令,目标节点中的槽已经迁移至别的节点上了,此时目标节点会返回ask转向给客户端
2.客户端向新的节点发送Asking命令给新的节点,然后再次向新节点发送命令
3.新节点执行命令,把命令执行结果返回给客户端
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JkFChqCd-1685503293025)(/Users/lmn/IdeaProjects/diandian/document/技术文档/技术资料/Redis/image-20230504154733253.png)]](https://img-blog.csdnimg.cn/2e4b20a228614aa18907d751c609b7a3.png)
moved和ask的区别
1、moved:槽已确认转移
2、ask:槽还在转移过程中
迁移
在RedisCluster中每个slot 对应的节点在初始化后就是确定的。在某些情况下,节点和分片需要变更:
- 新的节点作为master加入;
- 某个节点分组需要下线;
- 负载不均衡需要调整slot 分布。
此时需要进行分片的迁移,迁移的触发和过程控制由外部系统完成。包含下面 2 种:
- 节点迁移状态设置:迁移前标记源/目标节点。
- key迁移的原子化命令:迁移的具体步骤。
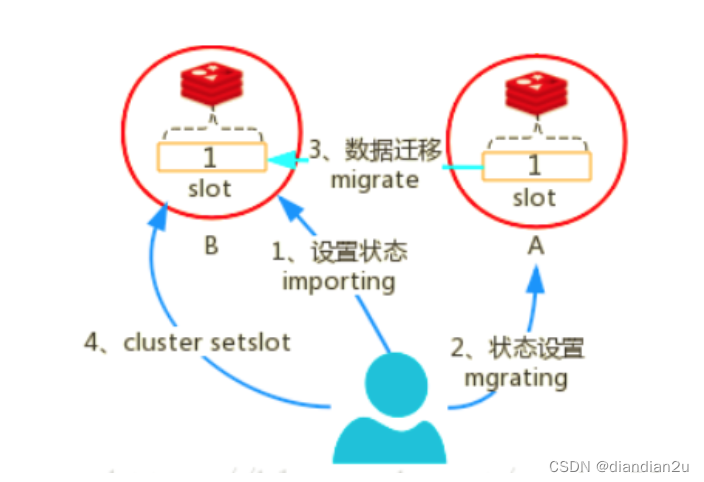
A向B的迁移:
1、向节点B发送状态变更命令,将B的对应slot 状态置为importing。
2、向节点A发送状态变更命令,将A对应的slot 状态置为migrating。
3、向A 发送migrate 命令,告知A 将要迁移的slot对应的key 迁移到B。
4、当所有key 迁移完成后,cluster setslot 重新设置槽位。
扩容
1. 添加主节点
- 先创建7007节点 (无数据)
mkdir redis-cluster/7007
make install PREFIX=/var/redis-cluster/7007
修改端口
./redis-server ./redis.conf
-
添加7007结点作为新节点,并启动
执行命令:
[root@localhost bin]# ./redis-cli --cluster add-node 192.168.72.128:7007
192.168.72.128:7001
>>> Adding node 192.168.127.128:7007 to cluster 192.168.127.128:7001
>>> Performing Cluster Check (using node 192.168.127.128:7001)
M: 02fdca827762904854293590323bb398e6bee971 192.168.127.128:7001
slots:[0-5460] (5461 slots) master
1 additional replica(s)
M: 95598dd50a91a72812ab5d441876bf2ee40ceef4 192.168.127.128:7003
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
S: 2191b40176f95a2a969bdcaccdd236aa01a3099a 192.168.127.128:7005
slots: (0 slots) slave
replicates 2dddc9d3925d129edd4c6bd5eab3bbad531277ec
S: 633af51cfdadb907e4d930f3f10082a77b256efb 192.168.127.128:7004
slots: (0 slots) slave
replicates 02fdca827762904854293590323bb398e6bee971
S: 1d35bec18fcc23f2c555a25563b1e6f2ffa3b0e9 192.168.127.128:7006
slots: (0 slots) slave
replicates 95598dd50a91a72812ab5d441876bf2ee40ceef4
M: 2dddc9d3925d129edd4c6bd5eab3bbad531277ec 192.168.127.128:7002
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
>>> Send CLUSTER MEET to node 192.168.127.128:7007 to make it join the cluster.
[OK] New node added correctly.
- 查看集群结点发现7007已添加到集群中
127.0.0.1:7001> cluster nodes
d277cd2984639747a17ca79428602480b28ef070 127.0.0.1:7003@17003 master - 0
1570457568602 3 connected 10923-16383
50b073163bc4058e89d285dc5dfc42a0d1a222f2 127.0.0.1:7007@17007 master - 0
1570457567000 0 connected
e7b1f1962de2a1ffef2bf1ac5d94574b2e4d67d8 127.0.0.1:7005@17005 slave
068b678923ad0858002e906040b0fef6fff8dda4 0 1570457569609 5 connected
068b678923ad0858002e906040b0fef6fff8dda4 127.0.0.1:7002@17002 master - 0
1570457566000 2 connected 5461-10922
51c3ebdd0911dd6564040c7e20b9ae69cabb0425 127.0.0.1:7004@17004 slave
af559fc6c82c83dc39d07e2dfe59046d16b6a429 0 1570457567000 4 connected
af559fc6c82c83dc39d07e2dfe59046d16b6a429 127.0.0.1:7001@17001 myself,master - 0
1570457567000 1 connected 0-5460
78dfe773eaa817fb69a405a3863f5b8fcf3e172f 127.0.0.1:7006@17006 slave
d277cd2984639747a17ca79428602480b28ef070 0 1570457567593 6 connected
- hash槽重新分配(数据迁移)
添加完主节点需要对主节点进行hash槽分配,这样该主节才可以存储数据。
- 查看集群中槽占用情况
redis集群有16384个槽,集群中的每个结点分配自已槽,通过查看集群结点可以看到槽占用情况。
127.0.0.1:7001> cluster nodes
d277cd2984639747a17ca79428602480b28ef070 127.0.0.1:7003@17003 master - 0
1570457568602 3 connected 10923-16383
50b073163bc4058e89d285dc5dfc42a0d1a222f2 127.0.0.1:7007@17007 master - 0
1570457567000 0 connected
e7b1f1962de2a1ffef2bf1ac5d94574b2e4d67d8 127.0.0.1:7005@17005 slave
068b678923ad0858002e906040b0fef6fff8dda4 0 1570457569609 5 connected
068b678923ad0858002e906040b0fef6fff8dda4 127.0.0.1:7002@17002 master - 0
1570457566000 2 connected 5461-10922
51c3ebdd0911dd6564040c7e20b9ae69cabb0425 127.0.0.1:7004@17004 slave
af559fc6c82c83dc39d07e2dfe59046d16b6a429 0 1570457567000 4 connected
af559fc6c82c83dc39d07e2dfe59046d16b6a429 127.0.0.1:7001@17001 myself,master - 0
1570457567000 1 connected 0-5460
78dfe773eaa817fb69a405a3863f5b8fcf3e172f 127.0.0.1:7006@17006 slave
d277cd2984639747a17ca79428602480b28ef070 0 1570457567593 6 connected
**给刚添加的7007结点分配槽 **
-
第一步:连接上集群(连接集群中任意一个可用结点都行)
[root@localhost 7007]# ./redis-cli --cluster reshard 192.168.72.128:7007 >>> Performing Cluster Check (using node 127.0.0.1:7007) M: 50b073163bc4058e89d285dc5dfc42a0d1a222f2 127.0.0.1:7007 slots: (0 slots) master S: 51c3ebdd0911dd6564040c7e20b9ae69cabb0425 127.0.0.1:7004 slots: (0 slots) slave replicates af559fc6c82c83dc39d07e2dfe59046d16b6a429 S: 78dfe773eaa817fb69a405a3863f5b8fcf3e172f 127.0.0.1:7006 slots: (0 slots) slave replicates d277cd2984639747a17ca79428602480b28ef070 S: e7b1f1962de2a1ffef2bf1ac5d94574b2e4d67d8 127.0.0.1:7005 slots: (0 slots) slave replicates 068b678923ad0858002e906040b0fef6fff8dda4 M: af559fc6c82c83dc39d07e2dfe59046d16b6a429 127.0.0.1:7001 slots:[0-5460] (5461 slots) master 1 additional replica(s) M: 068b678923ad0858002e906040b0fef6fff8dda4 127.0.0.1:7002 slots:[5461-10922] (5462 slots) master 1 additional replica(s) M: d277cd2984639747a17ca79428602480b28ef070 127.0.0.1:7003 slots:[10923-16383] (5461 slots) master 1 additional replica(s) [OK] All nodes agree about slots configuration. >>> Check for open slots... >>> Check slots coverage... [OK] All 16384 slots covered. -
第二步:输入要分配的槽数量
How many slots do you want to move (from 1 to 16384)? 3000
输入:3000,表示要给目标节点分配3000个槽
-
第三步:输入接收槽的结点id
What is the receiving node ID?输入:50b073163bc4058e89d285dc5dfc42a0d1a222f2
PS:这里准备给7007分配槽,通过cluster nodes查看7007结点id为: 50b073163bc4058e89d285dc5dfc42a0d1a222f2 -
第四步:输入源结点id
Please enter all the source node IDs. Type 'all' to use all the nodes as source nodes for the hash slots. Type 'done' once you entered all the source nodes IDs.输入:all
-
第五步:输入yes开始移动槽到目标结点id

输入:yes
Moving slot 11913 from 192.168.127.128:7003 to 192.168.127.128:7007:
Moving slot 11914 from 192.168.127.128:7003 to 192.168.127.128:7007:
Moving slot 11915 from 192.168.127.128:7003 to 192.168.127.128:7007:
Moving slot 11916 from 192.168.127.128:7003 to 192.168.127.128:7007:
Moving slot 11917 from 192.168.127.128:7003 to 192.168.127.128:7007:
Moving slot 11918 from 192.168.127.128:7003 to 192.168.127.128:7007:
Moving slot 11919 from 192.168.127.128:7003 to 192.168.127.128:7007:
Moving slot 11920 from 192.168.127.128:7003 to 192.168.127.128:7007:
Moving slot 11921 from 192.168.127.128:7003 to 192.168.127.128:7007:
查看结果
127.0.0.1:7001> cluster nodes
95598dd50a91a72812ab5d441876bf2ee40ceef4 192.168.127.128:7003@17003 master - 0
1595301163000 3 connected 11922-16383
6ff20bf463c954e977b213f0e36f3efc02bd53d6 192.168.127.128:7007@17007 master - 0
1595301164568 7 connected 0-998 5461-6461 10923-11921
2191b40176f95a2a969bdcaccdd236aa01a3099a 192.168.127.128:7005@17005 slave
2dddc9d3925d129edd4c6bd5eab3bbad531277ec 0 1595301163000 5 connected
633af51cfdadb907e4d930f3f10082a77b256efb 192.168.127.128:7004@17004 slave
02fdca827762904854293590323bb398e6bee971 0 1595301164000 4 connected
1d35bec18fcc23f2c555a25563b1e6f2ffa3b0e9 192.168.127.128:7006@17006 slave
95598dd50a91a72812ab5d441876bf2ee40ceef4 0 1595301161521 6 connected
2dddc9d3925d129edd4c6bd5eab3bbad531277ec 192.168.127.128:7002@17002 master - 0
1595301162000 2 connected 6462-10922
02fdca827762904854293590323bb398e6bee971 192.168.127.128:7001@17001
myself,master - 0 1595301160000 1 connected 999-5460
2. 添加从节点
- 添加7008从结点,将7008作为7007的从结点
命令:
./redis-cli --cluster add-node 新节点的ip和端口 旧节点ip和端口 --cluster-slave -- cluster-master-id 主节点id
例如:
./redis-cli --cluster add-node 192.168.72.128:7008 192.168.72.128:7007 --
cluster-slave --cluster-master-id 6ff20bf463c954e977b213f0e36f3efc02bd53d6
6ff20bf463c954e977b213f0e36f3efc02bd53d6是7007结点的id,可通过cluster nodes查看。
[root@localhost bin]# ./redis-cli --cluster add-node 192.168.127.128:7008
192.168.127.128:7007 --cluster-slave --cluster-master-id
6ff20bf463c954e977b213f0e36f3efc02bd53d6
>>> Adding node 192.168.127.128:7008 to cluster 192.168.127.128:7007
>>> Performing Cluster Check (using node 192.168.127.128:7007)
M: 6ff20bf463c954e977b213f0e36f3efc02bd53d6 192.168.127.128:7007
slots:[0-998],[5461-6461],[10923-11921] (2999 slots) master
S: 1d35bec18fcc23f2c555a25563b1e6f2ffa3b0e9 192.168.127.128:7006
slots: (0 slots) slave
replicates 95598dd50a91a72812ab5d441876bf2ee40ceef4
S: 633af51cfdadb907e4d930f3f10082a77b256efb 192.168.127.128:7004
slots: (0 slots) slave
replicates 02fdca827762904854293590323bb398e6bee971
M: 2dddc9d3925d129edd4c6bd5eab3bbad531277ec 192.168.127.128:7002
slots:[6462-10922] (4461 slots) master
1 additional replica(s)
M: 02fdca827762904854293590323bb398e6bee971 192.168.127.128:7001
slots:[999-5460] (4462 slots) master
1 additional replica(s)
S: 2191b40176f95a2a969bdcaccdd236aa01a3099a 192.168.127.128:7005
slots: (0 slots) slave
replicates 2dddc9d3925d129edd4c6bd5eab3bbad531277ec
M: 95598dd50a91a72812ab5d441876bf2ee40ceef4 192.168.127.128:7003
slots:[11922-16383] (4462 slots) master
1 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
>>> Send CLUSTER MEET to node 192.168.127.128:7008 to make it join the cluster.
Waiting for the cluster to join
>>> Configure node as replica of 192.168.127.128:7007.
[OK] New node added correctly.
注意:如果原来该结点在集群中的配置信息已经生成到cluster-config-file指定的配置文件中(如果 cluster-config-file没有指定则默认为nodes.conf),这时可能会报错:
[ERR] Node XXXXXX is not empty. Either the node already knows other nodes (check
with CLUSTER NODES) or contains some key in database 0
解决方法是删除生成的配置文件nodes.conf,删除后再执行./redis-cli --cluster add-node **指令 **
- 查看集群中的结点,刚添加的7008为7007的从节点:
[root@localhost 7008]# ./redis-cli -h 127.0.0.1 -p 7001 -c
127.0.0.1:7001> cluster nodes
95598dd50a91a72812ab5d441876bf2ee40ceef4 192.168.127.128:7003@17003 master - 0
1595301378000 3 connected 11922-16383
6be94480315ab0dd2276a7f70c82c578535d6666 192.168.127.128:7008@17008 slave
6ff20bf463c954e977b213f0e36f3efc02bd53d6 0 1595301378701 7 connected
6ff20bf463c954e977b213f0e36f3efc02bd53d6 192.168.127.128:7007@17007 master - 0
1595301379715 7 connected 0-998 5461-6461 10923-11921
2191b40176f95a2a969bdcaccdd236aa01a3099a 192.168.127.128:7005@17005 slave
2dddc9d3925d129edd4c6bd5eab3bbad531277ec 0 1595301375666 5 connected
633af51cfdadb907e4d930f3f10082a77b256efb 192.168.127.128:7004@17004 slave
02fdca827762904854293590323bb398e6bee971 0 1595301379000 4 connected
1d35bec18fcc23f2c555a25563b1e6f2ffa3b0e9 192.168.127.128:7006@17006 slave
95598dd50a91a72812ab5d441876bf2ee40ceef4 0 1595301380731 6 connected
2dddc9d3925d129edd4c6bd5eab3bbad531277ec 192.168.127.128:7002@17002 master - 0
1595301376000 2 connected 6462-10922
02fdca827762904854293590323bb398e6bee971 192.168.127.128:7001@17001
myself,master - 0 1595301376000 1 connected 999-5460
缩容
命令:
./redis-cli --cluster del-node 192.168.127.128:7008
6be94480315ab0dd2276a7f70c82c578535d6666
删除已经占有hash槽的结点会失败,报错如下:
[ERR] Node 192.168.127.128:7008 is not empty! Reshard data away and try again.
需要将该结点占用的hash槽分配出去。
容灾(failover)
1. 故障检测
集群中的每个节点都会定期地(每秒)向集群中的其他节点发送PING消息
如果在一定时间内(cluster-node-timeout),发送ping的节点A没有收到某节点B的pong回应,则A将B标识pfail。
A在后续发送ping时,会带上B的pfail信息, 通知给其他节点。
如果B被标记为pfail的个数大于集群主节点个数的一半(N/2 + 1)时,B会被标记为fail,A向整个集群广播,该节点已经下线。
其他节点收到广播,标记B为fail。
2. 从节点选举
raft算法,每个从节点都根据自己对master复制数据的offset,来设置一个选举时间,offset越大(复制数据越多)的从节点,选举时间越靠前,优先进行选举。
slave 通过向其他master发送FAILVOER_AUTH_REQUEST 消息发起竞选, master 收到后回复FAILOVER_AUTH_ACK 消息告知是否同意。
slave 发送FAILOVER_AUTH_REQUEST 前会将currentEpoch 自增,并将最新的Epoch 带入到 FAILOVER_AUTH_REQUEST 消息中发送给其他的master,如果master自己未投过票,则回复同意,否则回复拒绝。
所有的Master开始slave选举投票,给要进行选举的slave进行投票,如果大部分master node(N/2 + 1)都投票给了某个从节点,那么选举通过,那个从节点可以切换成master。
RedisCluster失效的判定:
1、集群中半数以上的主节点都宕机(无法投票)
2、宕机的主节点的从节点也宕机了(slot槽分配不连续)
3. 变更通知
当slave 收到过半的master 同意时,会成为新的master。此时会以最新的Epoch 通过PONG 消息广播自己成为master,让Cluster 的其他节点尽快的更新拓扑结构(nodes.conf)。
4. 主从切换
自动切换
如上的 从节点选举
手动切换
人工故障切换是预期的操作,而非发生了真正的故障,目的是以一种安全的方式(数据无丢失)将当前 master节点和其中一个slave节点(执行cluster-failover的节点)交换角色
1、向从节点发送cluster failover 命令(slaveof no one)
2、从节点告知其主节点要进行手动切换(CLUSTERMSG_TYPE_MFSTART)
3、主节点会阻塞所有客户端命令的执行(10s)
4、从节点从主节点的ping包中获得主节点的复制偏移量
5、从节点复制达到偏移量,发起选举、统计选票、赢得选举、升级为主节点并更新配置
6、切换完成后,原主节点向所有客户端发送moved指令重定向到新的主节点
以上是在主节点在线情况下。
如果主节点下线了,则采用cluster failover force或cluster failover takeover 进行强制切换。
5. 副本漂移
我们知道在一主一从的情况下,如果主从同时挂了,那整个集群就挂了。
为了避免这种情况我们可以做一主多从,但这样成本就增加了。
Redis提供了一种方法叫副本漂移,这种方法既能提高集群的可靠性又不用增加太多的从机。 如图:
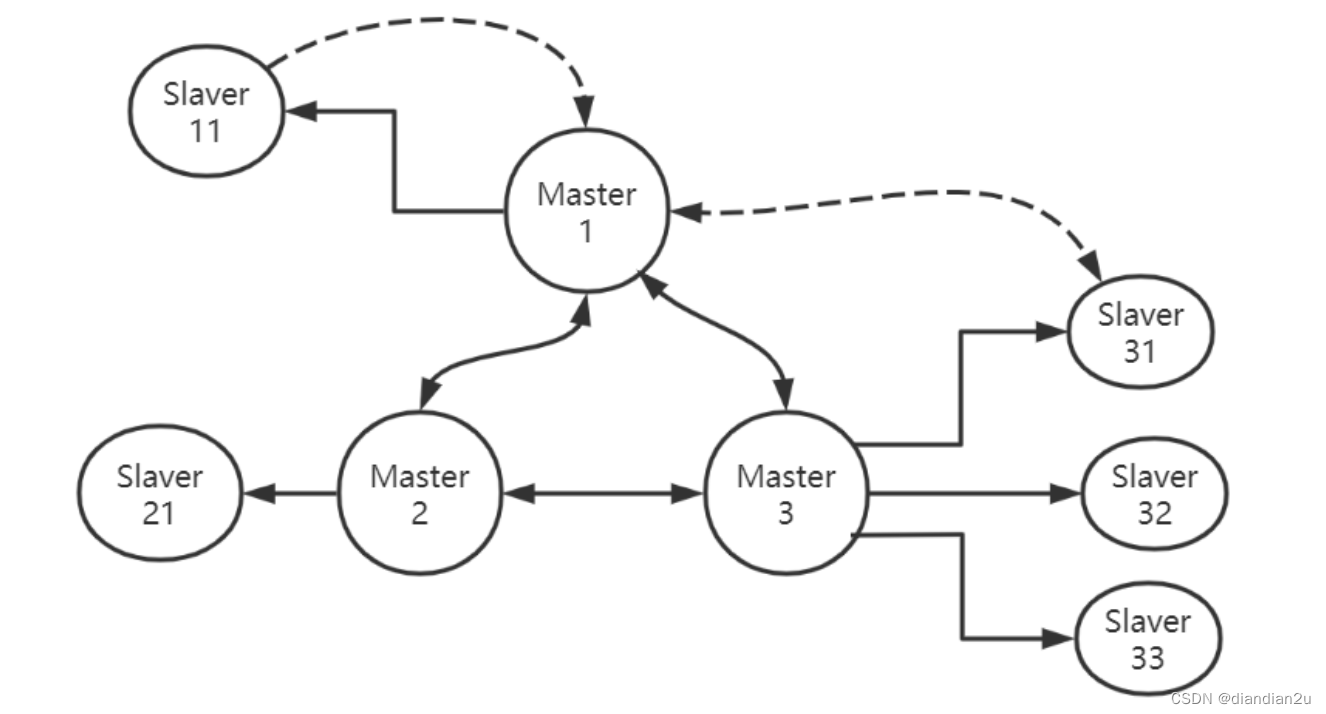
Master1宕机,则Slaver11提升为新的Master1
集群检测到新的Master1是单点的(无从机)
集群从拥有最多的从机的节点组(Master3)中,选择节点名称字母顺序最小的从机(Slaver31)漂移 到单点的主从节点组(Master1)。
具体流程如下(以上图为例):
1、将Slaver31的从机记录从Master3中删除
2、将Slaver31的的主机改为Master1
3、在Master1中添加Slaver31为从节点
4、将Slaver31的复制源改为Master1
5、通过ping包将信息同步到集群的其他节点














 351
351











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









