






一文带你搞懂匈牙利算法

附赠自动驾驶学习资料和量产经验:链接
什么是匈牙利算法
最近在研究一个比较有意思的应用—车辆追踪算法。传统的车辆追踪算法是基于检测器检出车辆,之后使用卡尔曼滤波和匈牙利算法来进行位置预测与数据级联的。关于卡尔曼滤波,我之前已经写过一篇文章进行了详细的介绍;最近则是在研究匈牙利算法是如何工作的。这里简单的记录一下相关原理。
匈牙利算法是一种在多项式时间内求解任务分配问题的组合优化算法,广泛应用在运筹学领域。 美国数学家哈罗德·库恩于1955年提出该算法。之所以被称作匈牙利算法,是因为算法很大一部分是基于以前匈牙利数学家Dénes Kőnig(1884-1944)和Jenő Egerváry(1891-1958)的工作上创建起来的。
在车辆追踪中,匈牙利算法(Hungarian Algorithm)与KM算法(Kuhn-Munkres Algorithm)都是用来解决多目标跟踪中的数据关联问题,而数据关联问题,亦可转化为求解二分图的最大匹配问题。二分图的最大匹配问题听起来很绕口,这里如何理解呢?换句话说,就是求解任务分配问题,也叫指派问题,即n项任务,对应分配给n个人去做,应该由哪个人来完成哪项任务,能够使完成效率最高。
这里举一个例子
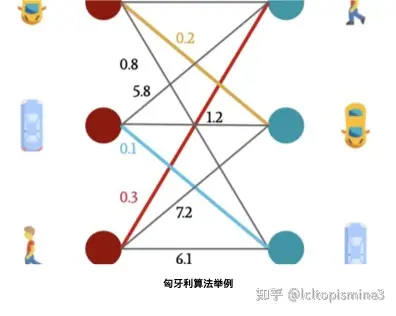
从图上可以看到,不同的车和人,之间的距离是不一样的。那么如果正确的把对应的车和对应的人匹配起来呢?这时候就需要用到匈牙利算法。
一个关于匈牙利算法的例子
这里我们使用一个例子来说明如何使用匈牙利算法
假设你有4个检测框(简写为det),对应于四个相应的追踪轨迹(简写为tracking), 给定相应之间的距离(稍后会讲到怎么算这个距离),那么如何匹配检测框与对应的追踪轨迹呢?
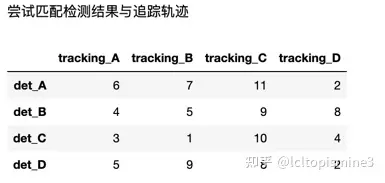
我们可以采用这样几个步骤来进行匹配
-
按照行,减去本行最小值
-
按照列,减去本列最小值
-
尝试以最少数量的线条划掉所有零;如果这个数量大于等于矩阵的行列数,那么跳到第五步
-
在剩下的矩阵中,减去最小值;如果有零被交叉,那么把这个最小值加上去,然后重复第三步
-
从只有一个零的行开始一一对应,对应完则整个行列删除
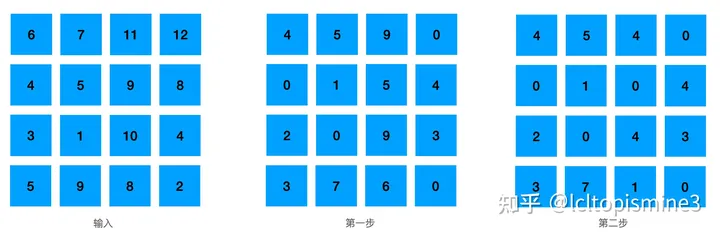
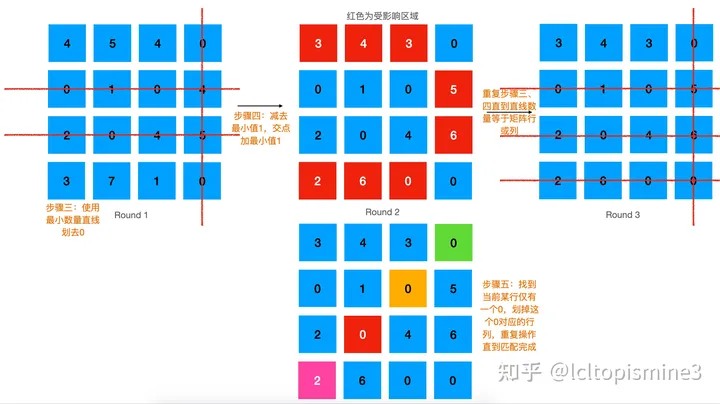
详细的执行步骤可以看一下这里的两张图,有比较清晰的描述。
最终结果: det_A->D det_B->A det_C->B det_D->C, 这里 -> 代表 “匹配”的意思。
额外要注意的是,这里我们求解的矩阵是N * N的,如果对应矩阵是 M * N的话,需要给少的维度补齐,补的值是当前矩阵中的最大值即可。
匈牙利算法原理与实现
接下来,我们简单聊一下匈牙利算法的原理和实现。
匈牙利算法一般是在二分图(Bipartite graph)这样的数据结构上实现的。这种图的名字可以看到,会把图中元素一分为二,其中顶点分为两两不相交的集合,并且同属于一个集合内的点两两不相连。
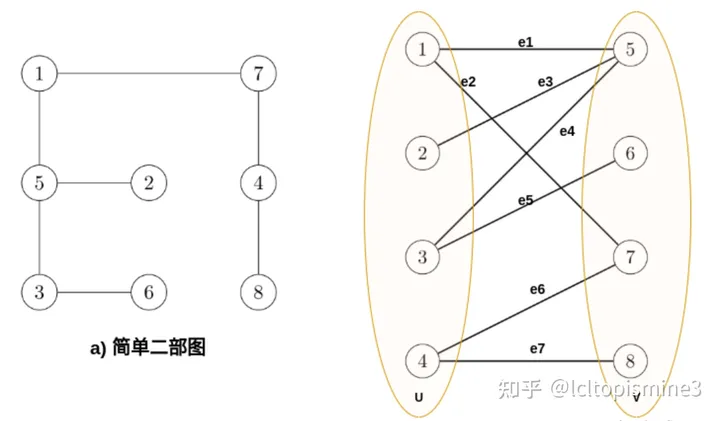
那么如何基于二分图(也叫二部图)判断匹配呢?这里我们说两条边匹配,即为存在两条边e1,e2,有e1,e2的顶点不相交,即为成功匹配。反之,如果相交了,代表的情况就是同一个人完成两个任务,这不符合匹配的要求,具体例子可以看下图。
这里,我们有边 e1 连接 点1和点5, e6连接 点4和点7,且各点之间不相交;红色边表示成功的匹配,被称为匹配边,匹配边所连接的点被称为匹配点。同样可以定义非匹配边和非匹配点(也就是顶点相交)
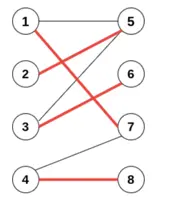
接下来,我们再给出最大匹配的定义:如果给定的二分图里面,有若干边不相交(形成若干匹配),且匹配数量达到这个二分图里所有可能匹配的最大值,那么我们认为这个二分图对应的匹配达到最大匹配(Maximum Matching)。图中 {e2,e3,e5,e7} 即为其中一组最大匹配。
此外有关于二分图(也属于图的定义),还有两个常常提到的定义,这里简单做一下介绍。
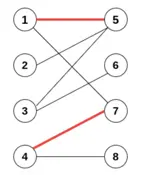
交错路径:图匹配结果中,如果相邻两条边性质不同,也就是出现匹配边->非匹配边->匹配边 相互交错的情况,那么我们说存在交错路径。假设 {e2, e7}相互匹配,我们有 {e1,e2,e6,e7}为交错路径。
增广路径:如果一条路径的首尾是非匹配点,路径中除此之外(如果有)其他的点均是匹配点,那么这条路径就是一条增广路径(Agumenting path)。也就是说,从一个非匹配点出发,走交错路径到另一个非匹配点(保证了两边的边为非匹配边)。这里假设{e1, e6}相互匹配,我们有 {e7,e6,e2,e1,e3}为增广路径。
从增广路径的定义可以看到,增广路径的首尾是非匹配点。因此,增广路径的第一条和最后一条边,必然是非匹配边;由交错路径的定义可知,增广路径从非匹配边开始,匹配边和非匹配边依次交替,最后由非匹配边结束。这样一来,增广路径中非匹配边的数目总比匹配边大 1。考虑置换增广路径中的匹配边和非匹配边,由于增广路径的首尾是非匹配点,其余则是匹配点,这样的置换不会影响原匹配中其他的匹配边和匹配点,因而不会破坏匹配;而增广路径的置换,可使匹配的边数加1,得到比原有匹配更大的匹配。
由于二分图的最大匹配必然存在(比如,上限是包含所有顶点的完全匹配),所以,在任意匹配的基础上,如果有办法不断地搜寻出增广路径,直到最终我们找不到新的增广路径为止。具体来说,每次找到增广路径,就尝试进行替换,使得匹配边数+1。最后就有可能得到二分图的一个最大匹配。这也是匈牙利算法的设计思路。
这里我们再举一个例子来进一步理解这个问题。
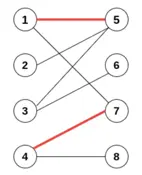
这里假设1-4是任务, 5-8是对应要干活的人,我们对应的可以这么分配任务:5->2, 6->3, 7->4
这样子做之后,只有8无法分到任务,这个时候并没有实现最佳匹配。因此,我们进一步的考虑交错路径 1->7; 7->4; 4->8中间是匹配边,其余是非匹配边,而且非匹配=匹配边+1。这时我们尝试交换匹配边与非匹配边,则有1->7, 4->8匹配, 这就找到了最大匹配。
匈牙利算法代码示例
这里提供一个使用python已有库计算匈牙利算法的代码片段,输入数据和“一个关于匈牙利算法的例子”一节中的输入数据一样,我们把这个输入数据叫做 cost_matrix。
import numpy as np
from scipy.optimize import linear_sum_assignment
cost_matrix = assignment.values.copy()
print("cost matrix is: ")
print(cost_matrix)
matches = linear_sum_assignment(cost_matrix)
print("find available matches: {}”.format(matches))
匈牙利算法中如何计算权重(距离)
现在我们尝试把匈牙利算法应用的车辆追踪任务上,这里主要介绍数据关联相关的内容。
使用匈牙利算法,最为重要的是去了解当前追踪问题对应的cost matrix,也就是损失矩阵。那么如果对损失矩阵进行计算呢?这里我们介绍三种常见的方法:
* 基于欧氏距离进行匹配;给定两帧中目标框的中心点,直接计算其中心点的欧式距离,需要迭代MXN次。如果目标形态发生变化,或目标间有重叠,那么效果相应的会受很大影响。
* 计算车辆之间的IOU值并进行计算,取最大值为合理匹配。然而匈牙利算法的目标是最小化损失,而IOU是越大越好,所以两者不相符合。解决方法是,找到待求解矩阵中的最大值,依次减去全部元素,然后继续求解即可
* 使用外观相似度进行判断。可以加入了外观信息,借用了ReID领域模型来提取特征,使用生成的特征来判断相似度。这样子的做法减少了ID switch。
实际进行损失计算,会同时考虑2和3,加权进行计算以获取最终匹配结果。
小结
匈牙利算法是一种二分图匹配算法,常用于二分图的最大匹配。数据追踪任务中,可以使用匈牙利算法进行数据关联,在物体匀速场景下配合卡尔曼滤波,会起到很好的作用。限于匈牙利算法本身是求二分图下最大结果,与数据级联要求的最小损失有冲突,实际使用是会额外追加限制或进行条件转化,使得匈牙利算法可以用于车辆追踪场景下的最优结果匹配。
匈牙利算法并不需要我们手写代码。在了解如何计算损失并可以生成损失矩阵的情况下,可以套用scipy或scikit-learn已有库来直接求解,相对来说还是比较方便的。














 1010
1010











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









