









目录
3.4 查看DataFrame基本统计值-describe()
5、查看类别、布尔值等特征分布-value_counts()
7.1 根据列名得到单独的列-DataFrame['Name']
7.8 找出 DataFrame 表中和最小的列-idxmin()/idxmax()
7.9 DataFrame 分组,并得到每一组中最大三个数之和
7.11 删除重复数据-drop_duplicates()
7.15 列名中添加前缀或后缀-add_prefix()或add_suffix()
7.17 通过数据类型选择列-select_dtypes()
13.1 判断DataFrame元素是否为空-isnull()
13.3 删除存在缺失值的行-dropna(how="any")
15.1 按指定列合并-merge(left, right, on="key")
15.2 使用列表拼接多个 DataFrame-concat()
20.1 宽数据转换为长数据,即宽表转为窄表-pd.melt()
20.2 样本的百分位数-pd.Series.quantile()
20.3 pandas的编码函数-将字符串特征转换为数字特征
20.3.2 one-hot编码-pd.get_dummies()
0、查看Pandas版本信息
import pandas as pd
print(pd.__version__)1、DataFrame文件操作
1.1 CSV文件读取数据-read_csv()
pd.read_csv(filepath_or_buffer,header,parse_dates,index_col)import numpy as np
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
df = pd.read_csv( 'https://labfile.oss.aliyuncs.com/courses/1283/telecom_churn.csv')
df1.2CSV文件写入数据-to_csv()
df3.to_csv('animal.csv')
print("写入成功.")
1.3 EXCEL文件读取数据-read_excel()
pd.read_excel('animal.xlsx', 'Sheet1', index_col=None, na_values=['NA'])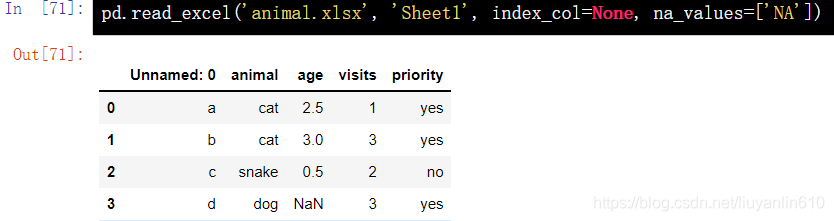
1.4 EXCEL文件写入数据-to_excel()
df3.to_excel('animal.xlsx', sheet_name='Sheet1')
print("写入成功.")
2、查看前5行或后5行数据
2.1 查看前5行数据-head()
df.head()
2.2 查看后3行数据-tail()
df.tail(3)3、查看数据维度、特征名称和特征类型
3.1 查看数据维度-shape
# 查看数据维度
df.shape
3.2 查看数据特征名称-columns
# 查看数据特征名称
df.columns
3.3 查看DataFrame的一些总体信息-info()
# 查看DataFrame的一些总体信息
df.info()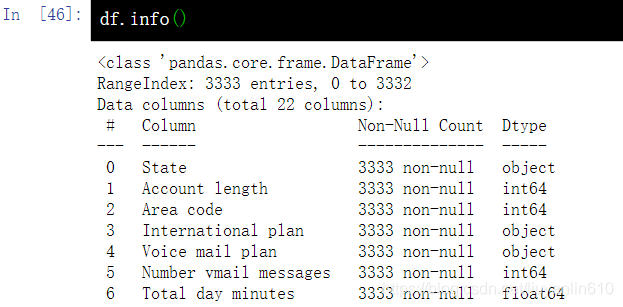
3.4 查看DataFrame基本统计值-describe()
3.4.1 查看DataFrame中数值特征的基本统计值
# 查看DataFrame中数值特征的基本统计值,如未缺失值数值、均值、标准差等
df.describe()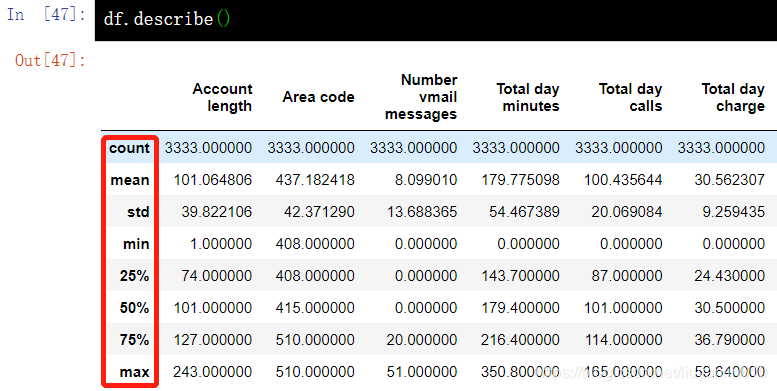
3.4.2 查看非数值特征的统计数据
#通过 include 参数显式指定包含的数据类型,可以查看非数值特征的统计数据。
df.describe(include=['object', 'bool'])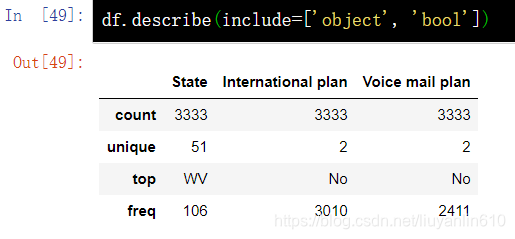
3.5 查看数据类型-dtypes
df2.dtypes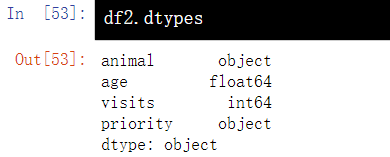
3.6 查看索引-index
df.index3.7 查看数值-values
df.values3.8 重命名列名-rename()
df.rename(columns={"category":"category-size"})4、更改列的类型-astype()
df['Churn'] = df['Churn'].astype('int64')5、查看类别、布尔值等特征分布-value_counts()
5.1 按出现频次
df['Churn'].value_counts()
5.2 按出现比例
df['Churn'].value_counts(normalize=True)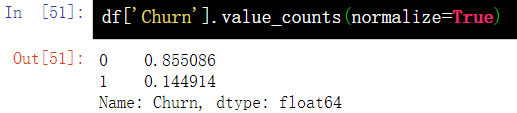
6、排序-sort_values()
6.1 根据单列的值排序
df.sort_values(by='Total day charge', ascending=False).head()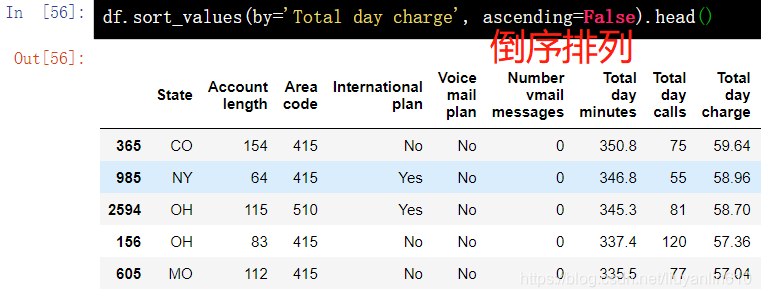 6.2 根据多列数值排序
6.2 根据多列数值排序
df.sort_values(by=['Churn', 'Total day charge'], ascending=[True, False]).head()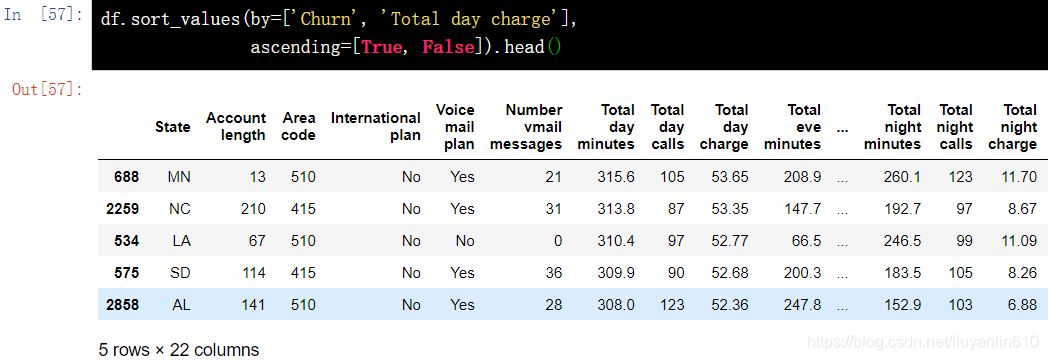
7、获取数据
7.1 根据列名得到单独的列-DataFrame['Name']
df['Churn'].mean()7.2 用布尔值索引
df[df['Churn'] == 1].mean()
df[(df['Churn'] == 0) & (df['International plan'] == 'No') ]['Total intl minutes'].max()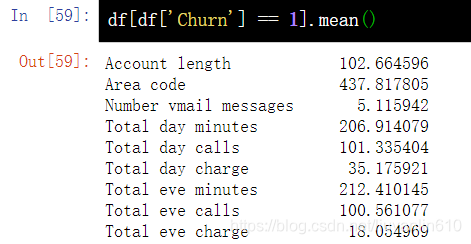
7.3 通过名称索引-loc
df.loc[0:5, 'State':'Area code']
7.4 通过数字索引-iloc
df.iloc[0:5, 0:3]
7.5 DataFrame的首行和末行
df[:1]
df[-1:]7.6 DataFrame的拷贝-copy()
df = df2.copy()7.7 按关键字查询-isin()
df[df['animal'].isin(['cat', 'dog'])]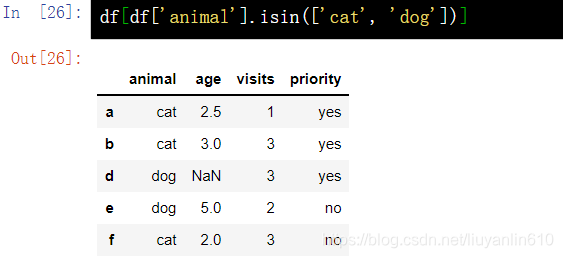
7.8 找出 DataFrame 表中和最小的列-idxmin()/idxmax()
df = pd.DataFrame(np.random.random(size=(5, 5)), columns=list('abcde'))
print(df)
df.sum().idxmin() # idxmax(), idxmin() 为 Series 函数返回最大最小值的索引值 7.9 DataFrame 分组,并得到每一组中最大三个数之和
7.9 DataFrame 分组,并得到每一组中最大三个数之和
df = pd.DataFrame({'A': list('aaabbcaabcccbbc'), 'B': [12, 345, 3, 1, 45, 14, 4, 52, 54, 23, 235, 21, 57, 3, 87]})
print(df)
df.groupby('A')['B'].nlargest(3).sum(level=0)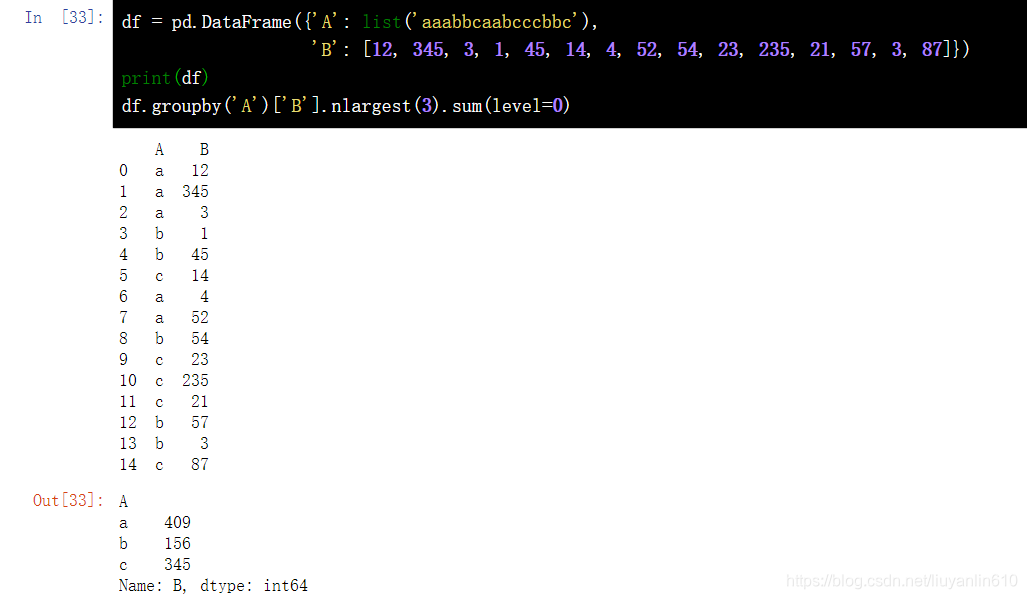
7.10 查看城市有多少个-unique()
df.city.unique()
set(df.city) 7.11 删除重复数据-drop_duplicates()
7.11 删除重复数据-drop_duplicates()
# 删除重复的数据 df.city.str.lower().drop_duplicates()
df.city.str.lower().drop_duplicates(keep="last")
df.city.str.lower().replace("sh","shanghai").drop_duplicates()7.12 数据筛选-query()
# 使用query函数筛选
df.query('city==["beijing","shanghai"]')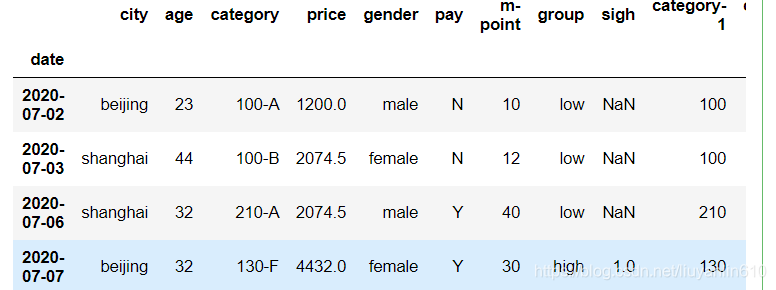
7.13 相关系数计算-corr()
# m-point和price的相关性系数
df_inner["price"].corr(df_inner["m-point"])
# 整个数据,数值变量的相关性系数
df_inner.corr().round(2)
7.14 计算同比环比-pct_change()
df1.pct_change() #计算当前元素与先前元素之间的百分比变化
7.15 列名中添加前缀或后缀-add_prefix()或add_suffix()
df.add_prefix("X_")
df.add_suffix()
7.16 重置索引-reset_index()
df.reset_index(drop=True)7.17 通过数据类型选择列-select_dtypes()
df.select_dtypes(include="number").head()

7.18 从多个文件构建DataFrame-glob模块

from glob import glob
stock_files = sorted(glob("stock*.csv))
stock_files
pd.concat((pd.read_csv(file) for file in stock_files))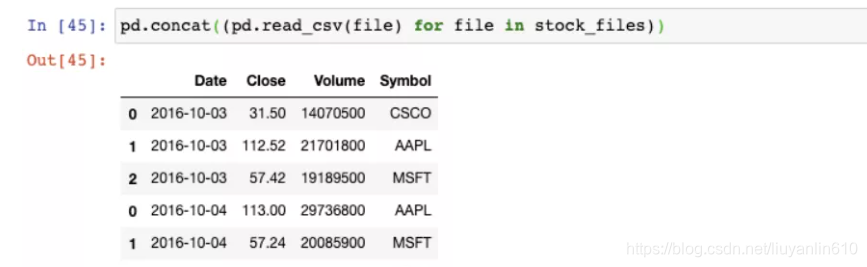
8、应用函数到单元格、列、行-apply()
8.1 应用到列
df.apply(np.max)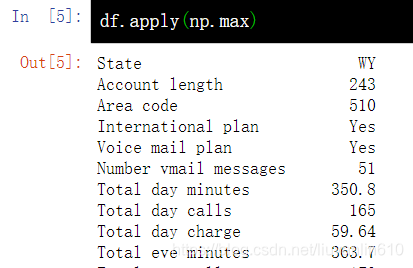
8.2 应用到每一行
apply() 方法也可以应用函数至每一行,指定 axis=1 即可。在这种情况下,使用 lambda 函数十分方便。比如,下面函数选中了所有以 W 开头的州。
df[df['State'].apply(lambda state: state[0] == 'W')].head()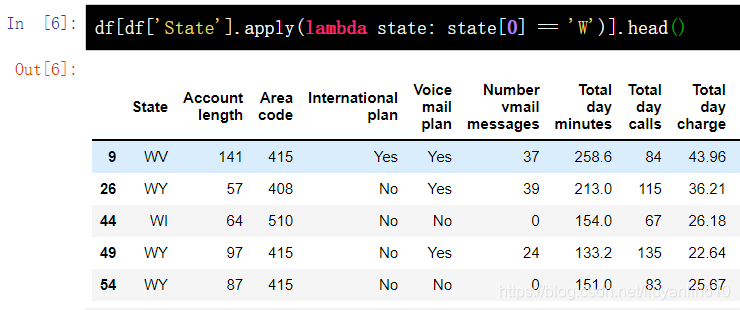
9、替换值
9.1 替换某一列中的值-map()
d = {'No': False, 'Yes': True}
df['International plan'] = df['International plan'].map(d)
df.head()
9.2 替换某一列中的值-replace()
df = df.replace({'Voice mail plan': d})
df.head()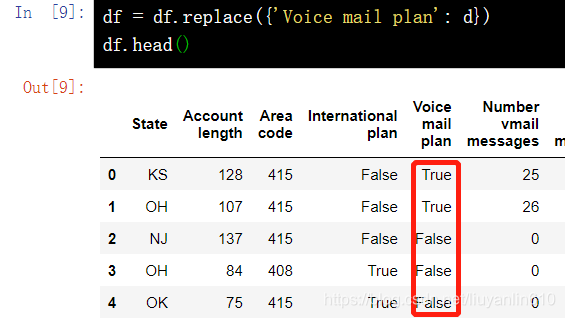
10、分组-groupby()
pandas中分组数据的一般形式为:
df.groupby(by=grouping_columns)[columns_to_show].function()- groupby() 方法根据 grouping_columns 的值进行分组。
- 接着,选中感兴趣的列(columns_to_show)。若不包括这一项,那么就会选中所有非 groupby 列(即除 grouping_colums 外的所有列)。
- 最后,应用一个或多个函数(function)。
columns_to_show = ['Total day minutes', 'Total eve minutes', 'Total night minutes']
df.groupby(['Churn'])[columns_to_show].describe(percentiles=[])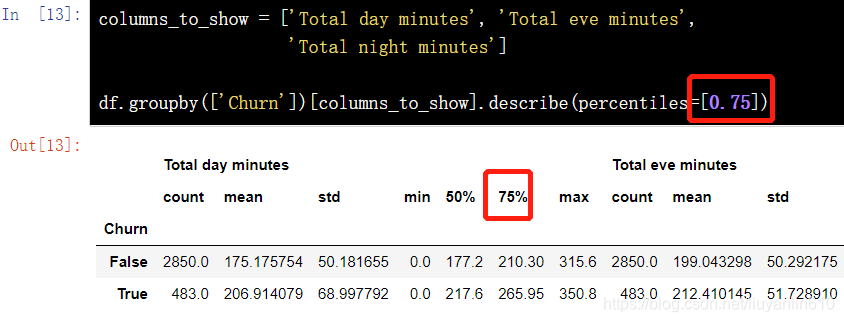
和上面的例子类似,只不过这次将一些函数传给 agg(),通过 agg() 方法对分组后的数据进行聚合。
columns_to_show = ['Total day minutes', 'Total eve minutes', 'Total night minutes']
df.groupby(['Churn'])[columns_to_show].agg([np.mean, np.std, np.min, np.max])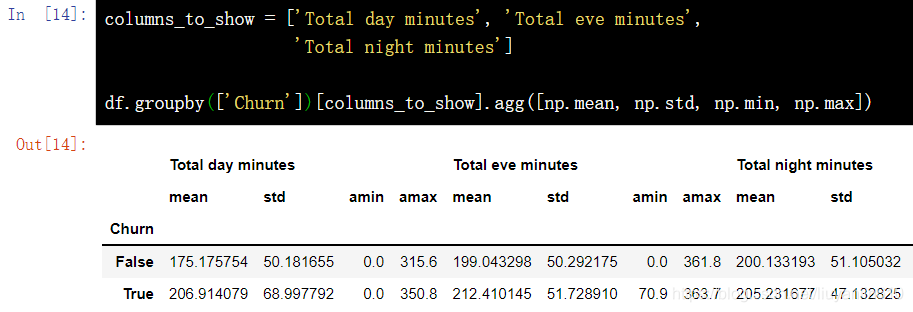
11、汇总表/透视表
11.1 透视表-pivot_table()
Pandas 中的透视表定义如下:
透视表(Pivot Table)是电子表格程序和其他数据探索软件中一种常见的数据汇总工具。它根据一个或多个键对数据进行聚合,并根据行和列上的分组将数据分配到各个矩形区域中。
通过 pivot_table() 方法可以建立透视表,其参数如下:
- values 表示需要计算的统计数据的变量列表
- index 表示分组数据的变量列表
- aggfunc 表示需要计算哪些统计数据,例如,总和、均值、最大值、最小值等。
11.1.1 透视表的创建
df.pivot_table(['Total day calls', 'Total eve calls', 'Total night calls'], ['Area code'], aggfunc='mean')
pd.pivot_table(df, values=['D'], index=['A', 'B'], aggfunc=[np.sum, len])
11.1.2 透视表的缺省值处理
pd.pivot_table(df, values=['D'], index=['A', 'B'], columns=['C'], aggfunc=np.sum, fill_value=0)
11.2 交叉表-crosstab()
交叉表(Cross Tabulation)是一种用于计算分组频率的特殊透视表,在 Pandas 中一般使用 crosstab() 方法构建交叉表。
11.2.1 按出现频次看分布
pd.crosstab(df['Churn'], df['International plan'])
11.2.2 按出现比例看分布
pd.crosstab(df['Churn'], df['Voice mail plan'], normalize=True)
12、增减DataFrame的行列
12.1 增加列的方法
12.1.1 insert()
total_calls = df['Total day calls'] + df['Total eve calls'] + \ df['Total night calls'] + df['Total intl calls']
# loc 参数是插入 Series 对象后选择的列数
# 设置为 len(df.columns)以便将计算后的 Total calls 粘贴到最后一列
df.insert(loc=len(df.columns), column='Total calls', value=total_calls)
df.head()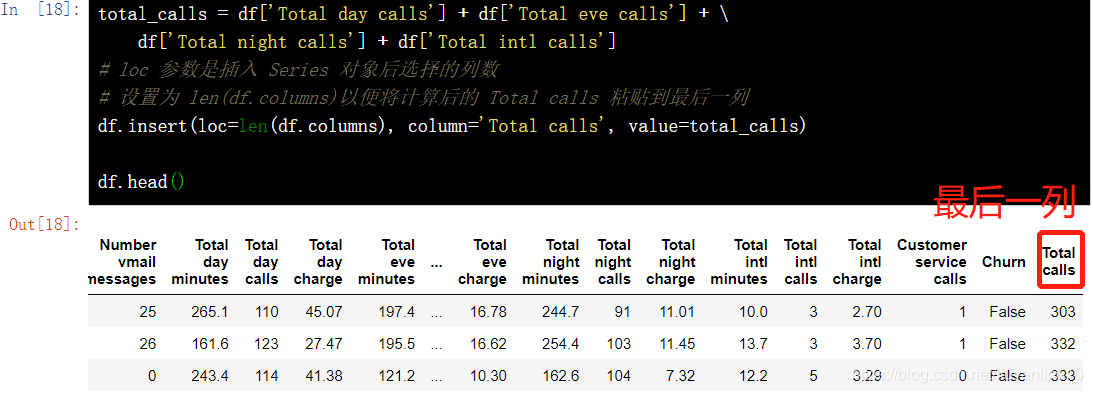
12.1.2 直接添加
df['Total charge'] = df['Total day charge'] + df['Total eve charge'] + \ df['Total night charge'] + df['Total intl charge']
df.head()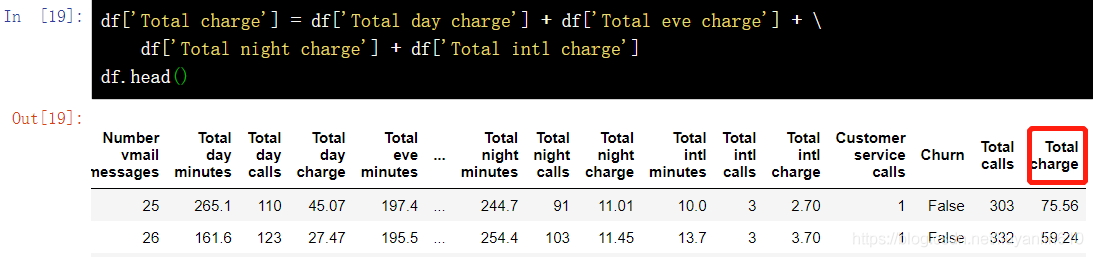
12.2 删除列和行-drop()
# 移除先前创捷的列
df.drop(['Total charge', 'Total calls'], axis=1, inplace=True)
# 删除行
df.drop([1, 2]).head()
13、DataFrame缺失值操作
13.1 判断DataFrame元素是否为空-isnull()
df.isnull()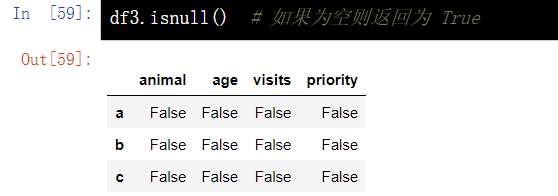
13.2 对缺失值进行填充-fillna(value)
df4 = df3.copy() df4.fillna(value=3)
13.3 删除存在缺失值的行-dropna(how="any")
df5 = df3.copy() df5.dropna(how='any') # 任何存在 NaN 的行都将被删除
13.4 缺失值拟合-interpolate()
df = pd.DataFrame({'From_To': ['LoNDon_paris', 'MAdrid_miLAN', 'londON_StockhOlm', 'Budapest_PaRis', 'Brussels_londOn'], 'FlightNumber': [10045, np.nan, 10065, np.nan, 10085], 'RecentDelays': [[23, 47], [], [24, 43, 87], [13], [67, 32]], 'Airline': ['KLM(!)', '<Air France> (12)', '(British Airways. )', '12. Air France', '"Swiss Air"']})
df['FlightNumber'] = df['FlightNumber'].interpolate().astype(int)
df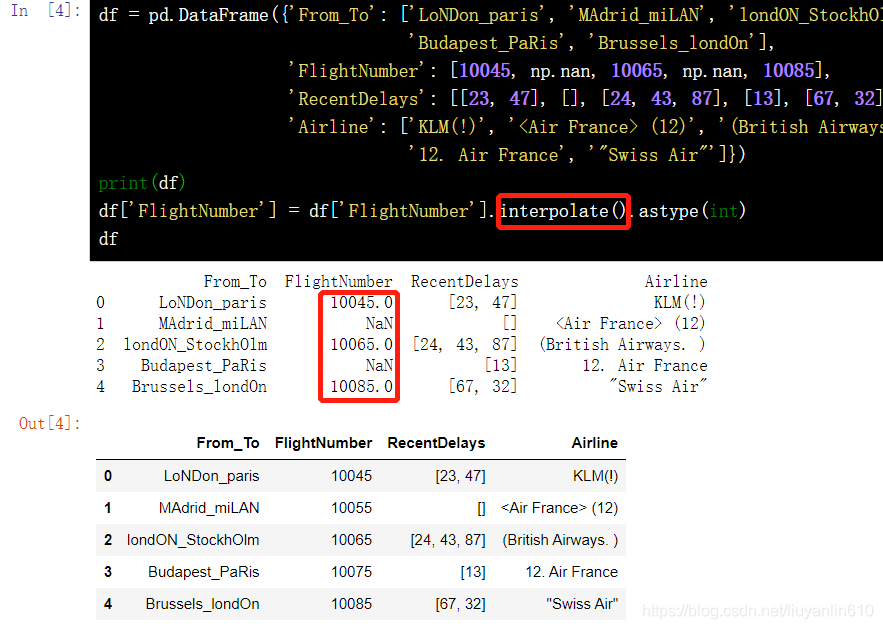
13.5 数据列拆分
temp = df.From_To.str.split('_', expand=True)
temp.columns = ['From', 'To']
temp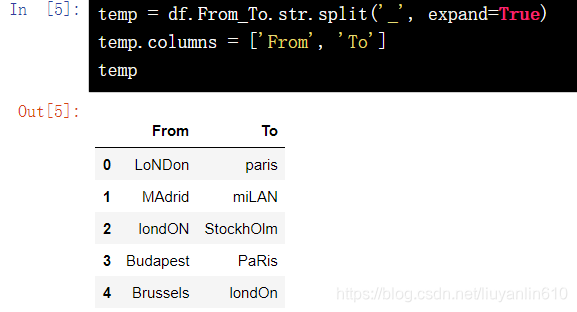
13.6 去除列数据中多余的其他字符-extract()
df['Airline'] = df['Airline'].str.extract( '([a-zA-Z\s]+)', expand=False).str.strip()
df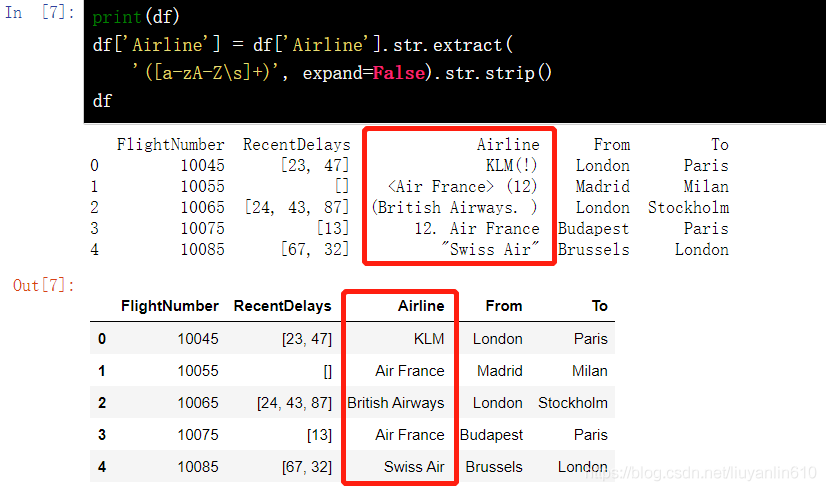
13.7 格式规范
delays = df['RecentDelays'].apply(pd.Series)
delays.columns = ['delay_{}'.format(n) for n in range(1, len(delays.columns)+1)]
df = df.drop('RecentDelays', axis=1).join(delays)
df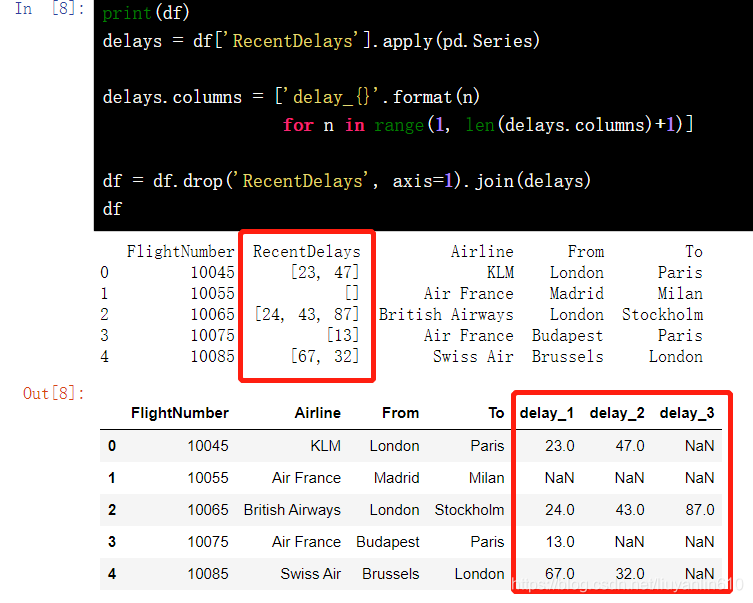
14、字符串操作
14.1 将字符串转化为小写字母-lower()
string = pd.Series(['A', 'B', 'C', 'Aaba', 'Baca', np.nan, 'CABA', 'dog', 'cat'])
string.str.lower()
14.2 将字符串转化为大写字母
string.str.upper()14.3 首字母大写-capitalize()
print(temp) temp['From'] = temp['From'].str.capitalize()
temp['To'] = temp['To'].str.capitalize()
temp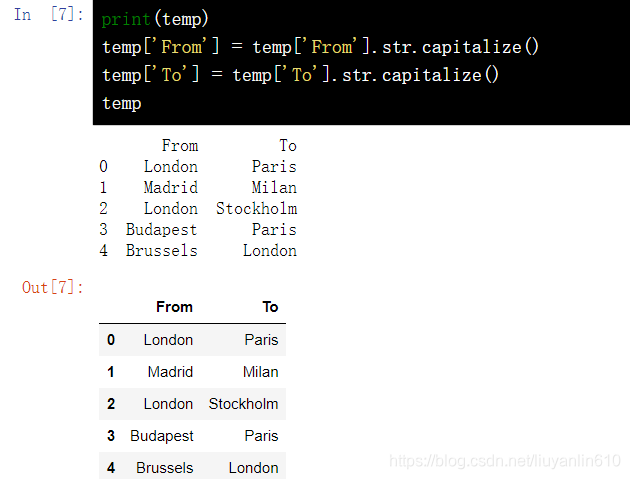
15、DataFrame的多表连接
15.1 按指定列合并-merge(left, right, on="key")
结果集的行数并没有增加,列数则为两个元数据的列数和减去连接键的数量。
DataFrame.merge(left, right, how='inner', on=None, left_on=None, right_on =None, left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'), copy=True, indicator=False, validate =None)[source]left = pd.DataFrame({'key': ['foo1', 'foo2'], 'one': [1, 2]})
right = pd.DataFrame({'key': ['foo2', 'foo3'], 'two': [4, 5]})
# 按照 key 列对齐连接,只存在 foo2 相同,所以最后变成一行
pd.merge(left, right, on='key')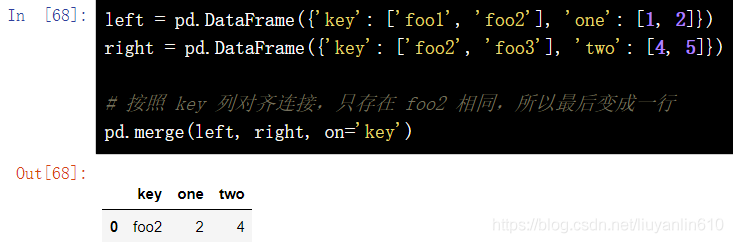
15.2 使用列表拼接多个 DataFrame-concat()
CONCAT的垂直堆叠。垂直堆叠就是axis=0,这种情况下有个参数比较特殊,叫' ignore_index= ',默认情况下是False。如果设成了True,就是把结果的合并表重新编排行索引。否则,行索引还是原来两个表里的值
pandas.concat(objs, axis=0, join='outer', join_axes=None, ignore_index= False, keys=None, levels=None, names=None, verify_integrity= False, sort=None, copy=True)temp_df1 = pd.DataFrame(np.random.randn(5, 4)) # 生成由随机数组成的 DataFrame 1
temp_df2 = pd.DataFrame(np.random.randn(5, 4)) # 生成由随机数组成的 DataFrame 2
temp_df3 = pd.DataFrame(np.random.randn(5, 4)) # 生成由随机数组成的 DataFrame 3
pieces = [temp_df1, temp_df2, temp_df3]
pd.concat(pieces)
15.3 拼接列-join()
JOIN 拼接列,主要用于基于行索引上的合并。
只要两个表列名不同,不加任何参数就可以直接用;如果两个表有重复的列名,需指定lsuffix, rsuffix参数;其中参数的意义与merge方法基本相同,只是join方法默认为左外连接how=left
DataFrame.join(other, on=None, how='left', lsuffix='', rsuffix='', sort= False)df1.join(df2,lsuffix="letter",rsuffix="lerrer)
16、时间序列处理
16.1 建立一个以时间为索引,值为随机数的Series
dti = pd.date_range(start='2018-01-01', end='2018-12-31', freq='D')
s = pd.Series(np.random.rand(len(dti)), index=dti)
s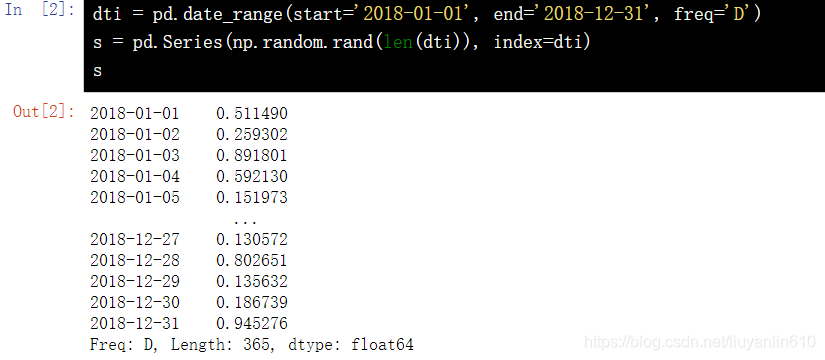
16.2 统计s 中每一个周三对应值的和
# 周一从 0 开始
s[s.index.weekday == 2].sum()
16.3 统计s中每个月值的平均值
s.resample('M').mean()
16.4 将 Series 中的时间进行转换(秒转分钟)
s = pd.date_range('today', periods=100, freq='S')
ts = pd.Series(np.random.randint(0, 500, len(s)), index=s)
ts.resample('Min').sum()
16.5 UTC 世界时间标准
s = pd.date_range('today', periods=1, freq='D') # 获取当前时间
ts = pd.Series(np.random.randn(len(s)), s) # 随机数值
ts_utc = ts.tz_localize('UTC') # 转换为 UTC 时间
ts_utc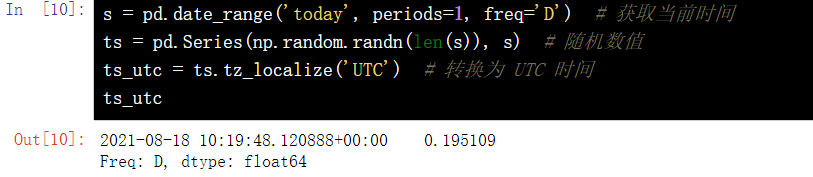
转换为上海所在时区
ts_utc.tz_convert('Asia/Shanghai')16.6 不同时间表示方式的转换
rng = pd.date_range('1/1/2018', periods=5, freq='M')
ts = pd.Series(np.random.randn(len(rng)), index=rng)
print(ts)
ps = ts.to_period()
print(ps)
ps.to_timestamp()
17、DataFrame多重索引
17.1 根据多重索引创建 DataFrame
frame = pd.DataFrame(np.arange(12).reshape(6, 2), index=[list('AAABBB'), list('123123')], columns=['hello', 'shiyanlou'])
frame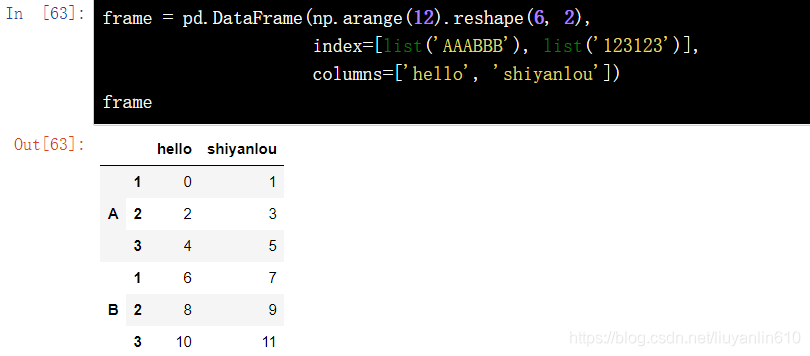
17.2 多重索引设置列名称
frame.index.names = ['first', 'second']
frame
17.3 DataFrame 行列名称转换-stack()
stack()是将原来的列索引(A,B)转成了最内层的行索引(ABABABAB)
print(frame)
frame.stack()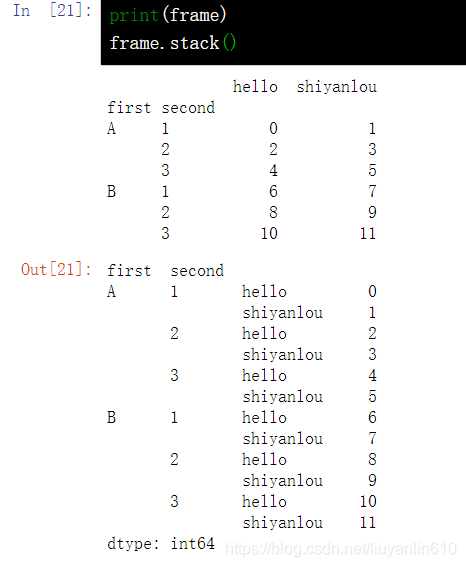
17.4 DataFrame 索引转换-unstack()
unstack()方法和pivot()方法是很像的,主要的不同在于,unstack()方法是针对索引或者标签的,即将列索引转成最内层的行索引;而pivot()方法则是针对列的值,即指定某列的值作为行索引,指定某列的值作为列索引,然后再指定哪些列作为索引对应的值
print(frame)
frame.unstack()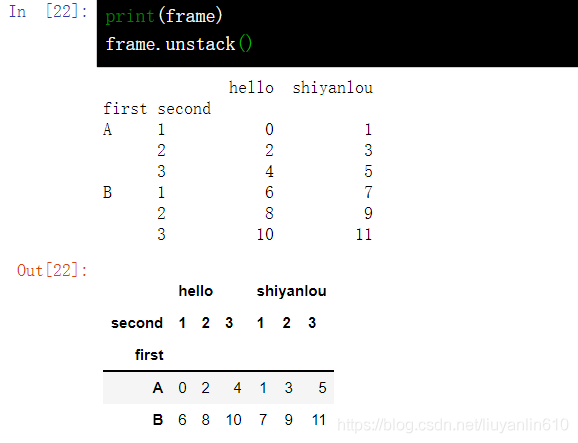
18、Pandas绘图操作
18.1 DataFrame 折线图
f = pd.DataFrame({"xs": [1, 5, 2, 8, 1], "ys": [4, 2, 1, 9, 6]})
df = df.cumsum()
df.plot()18.2 DataFrame 散点图
df = pd.DataFrame({"xs": [1, 5, 2, 8, 1], "ys": [4, 2, 1, 9, 6]})
df = df.cumsum()
df.plot.scatter("xs", "ys", color='red', marker="*")
18.3 DataFrame 柱形图
df = pd.DataFrame({"revenue": [57, 68, 63, 71, 72, 90, 80, 62, 59, 51, 47, 52], "advertising": [2.1, 1.9, 2.7, 3.0, 3.6, 3.2, 2.7, 2.4, 1.8, 1.6, 1.3, 1.9], "month": range(12) })
ax = df.plot.bar("month", "revenue", color="yellow")
df.plot("month", "advertising", secondary_y=True, ax=ax)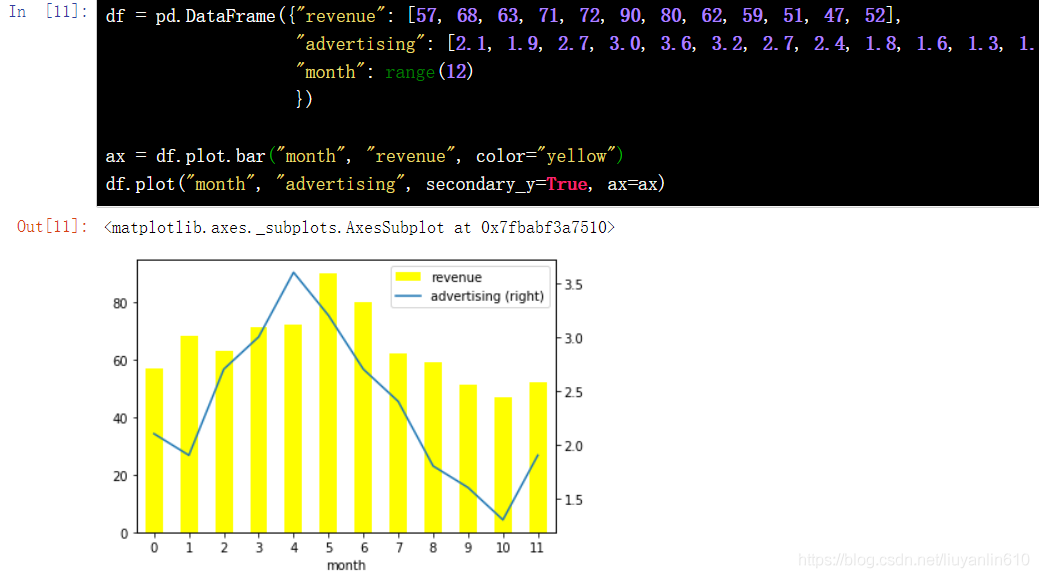
18.4 设置图的大小
方法一:
%pylab inline figsize(16, 6)方法二:
import matplotlib.pyplot as plt
plt.style.use({'figure.figsize':(12, 6)})18.5 出现中文乱码和符号不显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] =False19、减小DataFrame空间大小
19.1 查看空间使用大小
drinks.info(memory_usage="deep")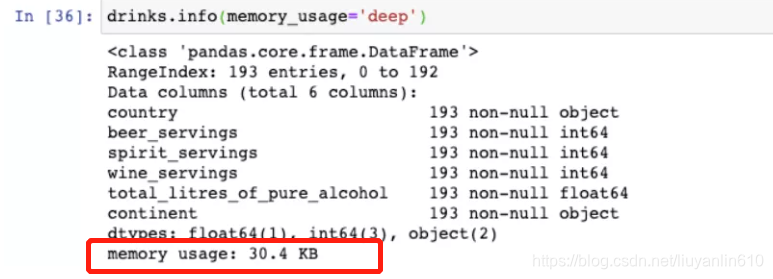
19.2 减小空间大小
1)只读实际需要用到的列
cols= ["beer_servings","continent"]
small_drinks = pd.read_csv("./drinksbycountry.csv",usecols=cols)
small_drinks.info(memory_usage="deep")
2)将所有实际上为类别变量的object列转换成类别变量
dtypes={"continent":"category"}
smaller_drinks = pd.read_csv("./drinksbycountry.csv",usecols=cols,dtype=dtypes)
smaller_drinks.info(memory_usage="deep")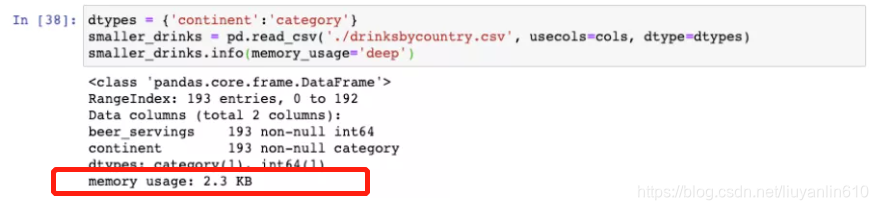
20、其他方法补充
前期系统整理了pandas常用的方法,但是后期学习或工作过程中,还是会遇到未作整理的方法。为了方便快捷的记录,未在原有框架上做补充,而是单独新增一个目录,进行记录。
20.1 宽数据转换为长数据,即宽表转为窄表-pd.melt()
pandas.melt(frame, id_vars=None, value_vars=None, var_name=None, value_name='value', col_level=None)参数解释:
frame:要处理的数据集。
id_vars:不需要被转换的列名。
value_vars:需要转换的列名,如果剩下的列全部都要转换,就不用写了。
var_name和value_name是自定义设置对应的列名。
col_level :如果列是MultiIndex,则使用此级别。
df.head()
df_uniques = pd.melt(frame=df, value_vars=['gender', 'cholesterol',
'gluc', 'smoke', 'alco',
'active', 'cardio'])
df_uniquesniques

20.2 样本的百分位数-pd.Series.quantile()
df["height"].quantile(0.25)
df["height"].describe()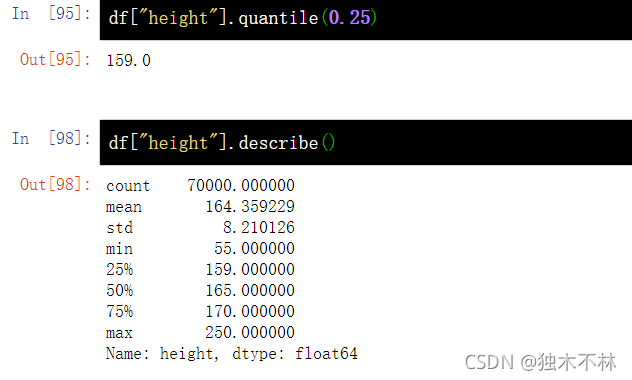
20.3 pandas的编码函数-将字符串特征转换为数字特征
所谓编码,自然是将一种符号编成一种数字码-----即数字变量。
20.3.1 因式分解 -pd.factorize()
pd.factorize()做的也是“因式分解”,把常见的字符型变量分解为数字。
df['International plan']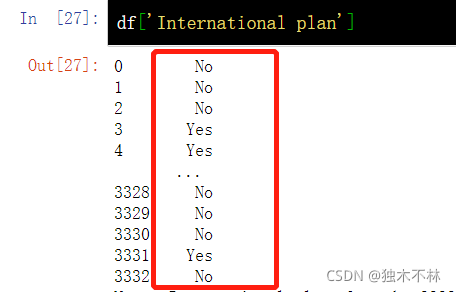
df['International plan']=pd.factorize(df['International plan'])
20.3.2 one-hot编码-pd.get_dummies()
pd.get_dummies()就是讲一种字符型或者其他类型编程成一串数字向量,也就是所谓的one-hot编码。
import pandas as pd
dt = pd.DataFrame([
['green' , 'A'],
['red' , 'B'],
['blue' , 'A']])
dt.columns = ['color', 'class']
print(dt)
pd.get_dummies(dt) 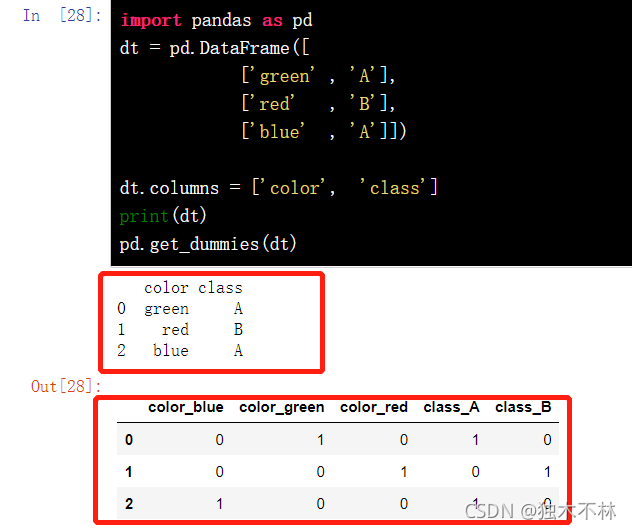
20.4 找到众数-mode()
df = pd.DataFrame({'A': [1, 2, 1, 1, 1, 2, 3]})
df["A"].mode() 














 2664
2664











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









