









0、概述
统计分析是可以帮助人们认清、刻画不确定性的方法。总体是某一特定事物可能发生结果的集合, 随机变量(Random Variable) 则是一个不确定事件结果是数值函数(Function)。也就是说,把不确定事件的结果用数值来表述,即得到随机变量。随机变量包括离散型随机变量(Discrete Random Variable) 和 连续型随机变量(Continuous Radom Variable)。常用的离散型随机变量分布包括:0-1分布、二项分布、泊松分布和二项式分布等。常用的连续型随机变量分布包括:正态分布、卡方分布、T分布和 F分布等。
1、概率与概率分布
概率(Probability)是用来表示事物不确定性的一种测度(Measure),根据概率的大小,我们可以判断不确定性的高低。
1.1 离散型随机变量
1.1.1概率质量函数(PMF)
假设X是一个离散型随机变量,其所有可能取值为集合{ak},k=1,2,…,我们定义X的概率质量函数(Probability Mass Function) 为:
fX (ak) = P{ X = ak } , k = 1 , 2 , ⋯
概率质量函数可以量化地表达随机变量X取每个数值可能性的大小
1.1.2 累计分布密度函数(CDF)
对于离散型随机变量,累计分布函数可以用概率质量函数累加来获得:
FX(a) = P{ X ≤ a } = ∑fX (ai)
1.1.3 Python 实现
通过Numpy包的random模块中的choice()函数可以生成服从待定的概率质量函数的随机数。
choice()函数:
choice(a, size=None, replace=True, p=None)
参数a: 随机变量可能的取值序列。
参数size: 我们要生成随机数数组的大小。
参数replace: 决定了生成随机数时是否是有放回的。
参数p:为一个与x等长的向量,指定了每种结果出现的可能性。
计算频数分布使用value_counts()函数
# 以数组形式
import numpy as np
import pandas as pd
RandomNumber=np.random.choice([1,2,3,4,5],size=100, replace=True,p=[0.1,0.1,0.3,0.3,0.2])
pd.Series(RandomNumber).value_counts() # 计算频数分布value_counts()函数
pd.Series(RandomNumber).value_counts()/100 #计算概率分布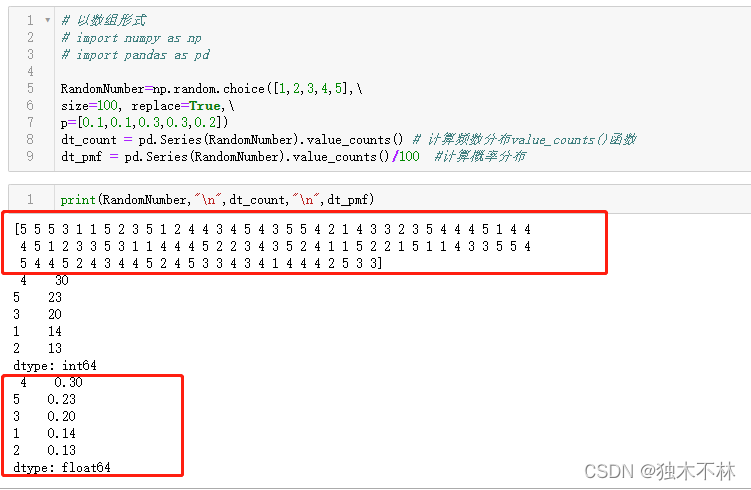
- 增大size参数,即生成随机数的数目,得到的结果则会更接近设定的概率。
1.2 连续性随机变量
若随机变量X是连续的,我们则不再能通过概率质量函数来刻画随机变量的随机性,对任意ak都有P { X = ak } = 0
连续型随机变量没有PMF。对于连续型随机变量,累积分布函数FX ( a ) = P { X ≤ a } 可以表达为:
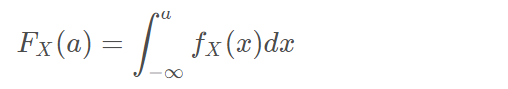
其中fX = dFX(x) / dx ,被称作概率密度函数(Probability Density Function)(PDF),X的取值落在某个区间的概率可以用概率密度函数在这个区间上的积分来求得。
算法逻辑:
- 使用stats模块kde包中的gaussian_kde()可以估计数据的概率密度,在其中传入我们要统计的Series类型的变量名即可,得到的是一个“scipy.stats.kde.gaussian_kde”类型的对象,我们暂先给其命名为density。
- 然后设定好分割区间,设为数组格式,暂将该对象命名为bins。
- 注意,这次与以往绘图不同,这次是以研究的对象数据为行进行绘图。
- 使用上边得到的数据类型density,以 density(bins)格式的语法可以得到一个以设定的分割区间为界限的概率密度数组,让将density(bins)这个对象作为行传入plot即可。
- 如果要绘制累计分布函数图,则只需在上边的density(bins)对象后再调用一下cumsum()函数,对数组数据进行累加后在传入即可。
# 实现概率分布
import matplotlib.pyplot as plt
from scipy import stats
df = pd.DataFrame(np.random.normal(0,1,[100,5]),columns=["a","b","c","d","e"])
density = stats.kde.gaussian_kde(df['a']) #研究数据格式化
bins=np.arange(-3.2,3,0.02) # 设定分割区间
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.subplot(211)
plt.plot(bins,density(bins))
plt.title('序列a概率密度曲线图')
plt.subplot(212)
plt.plot(bins,density(bins).cumsum())
plt.title('序列a累积分布函数图')
plt.subplots_adjust(left=None,bottom=None,right=None,top=None,wspace=0.35,hspace=0.35)
plt.show()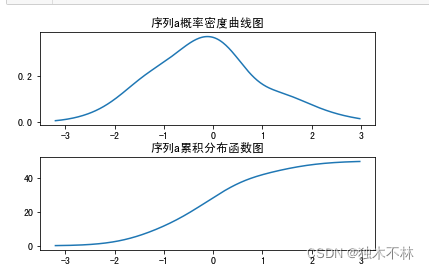
1.3 分位数的概念
分位数是指将一个随机变量的概率分布范围分为几个等份的数值点,用于分析数据变量的趋势。分位数分的是某个特定分布的概率密度函数曲线下的面积。常用的有中位数、四分位数、百分位数等。
假设连续型随机变量 X的分布函数为 F(X) ,那么满足条件的 F(X0=1/4 ,称为 X或分布 F 的四分位数。也就是说,对于概率密度函数,四分位点就是将概率密度曲线下的面积均分为4部分的点。
上 α分位数:该数值将概率密度函数曲线下的面积沿x轴分成两部分,其中该点右侧部分概率密度函数曲线与x轴围成的面积等于 α 。
调用scipy包的stats统计模块,可以直接得出不同分布的分为点的值,相对于,查表,或使用excel,使用起来会更加便捷
 对于概率密度函数曲线,它下方的面积就是概率,因此上 α 分位数中的 α 既是该点右侧区域的面积,又是在这个分布中取到所有大于该点的值的概率。
对于概率密度函数曲线,它下方的面积就是概率,因此上 α 分位数中的 α 既是该点右侧区域的面积,又是在这个分布中取到所有大于该点的值的概率。
2、期望与方差
可以用样本数据的平均值来刻画样本的中心位置,期望(Expectation)是随机变量所有可能取的结果的均值,用来呈现总体的中心位置。对于离散型随机变量,期望是该随机变量所有可能结果的取值与其概率的乘积之和:
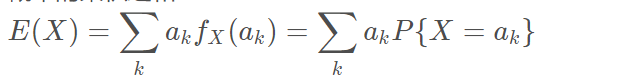
方差(Variance)则是:
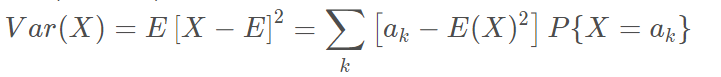 随机变量可能的取值有很多(比如连续型随机变量的取值为无穷),但其观测值(实际值)个数有限,因此现实中随机变量的概率分布、期望、方差等特征值通常是不可知的,推断统计就是透过其观测值的集合——样本数据来刻画这些特征的。
随机变量可能的取值有很多(比如连续型随机变量的取值为无穷),但其观测值(实际值)个数有限,因此现实中随机变量的概率分布、期望、方差等特征值通常是不可知的,推断统计就是透过其观测值的集合——样本数据来刻画这些特征的。
3、常见分布
3.1 离散型随机变量及其分布规律
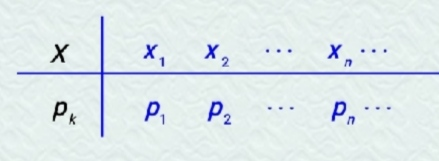
设离散型随机变量X的所有可能取的值为Xk(k=1,2,···),X取各个可能值的概率,即事件{X=Xk}的概率,为
P{X=Xk}=pk ,k=1,2,···
则为离散型随机变量 X 的概率分布或分布。显然,离散型随机变量的概念分布具有
pk >0 和 sum(pk)=1 两个基本性质。离散型随机变量的分布律也可以表示为:
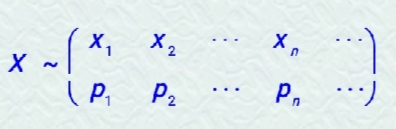
常见的离散型随机变量的概率分布:
3.1.1 0-1分布(又称伯努利分布或两点分布)
如果随机变量X的分布为
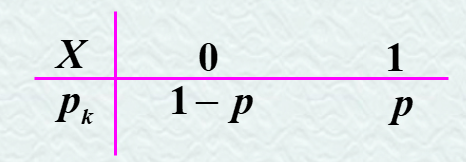
称X服从参数为p的(0-1)分布
0-1分布的数学期望,方差分别为
E(X) = p
D(X) = p*(1-p)
3.1.2 二项分布
(1) 独立重复试验
将试验E重复进行n次,若个各次试验的结果互不影响,则称这n次试验是相互独立的或称为n次独立重复试验
(2) n重伯努利试验
设试验E只有两个可能结果,则称E为伯努利试验。将E独立重复进行n次,则称为n重伯努利试验
(3)、二项概率公式
若X表示n重伯努利试验中A发生的次数,X所有可能取的值为0,1,2,···,n
X的分布律为
 称这样的分布为二项分布,记为X~b(n,p)
称这样的分布为二项分布,记为X~b(n,p)
二项分布的数学期望,方差分别为
E(X) = p
D(X) = n*p*(1-p)
在Numpy库中可以使用binomial()函数来生成二项分布随机数。
形式为:binomial(n, p, size=None)
参数n是进行伯努利试验的次数,参数p是伯努利变量取值为1的概率,size是生成随机数的数量。
研究0-1分布时,我们关注的期望是进行一次试验结果的期望值,这样的结果有两种情况,所以伯努利分布也称“两点分布”。
而研究二项分布时,我们关注的是n次试验的结果,这样的结果有多种组合。
为直观说明,假设二点分布结果0的概率为0.4,结果为1的概率为0.6;
二项分布结果为0的概率为0.4,结果为1的概率为0.6,且进行十次。则:
n = 10
p1 = 0.6
p2 = 0.6
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.subplot(221)
plt.bar(['0','1'], [1-p1,p1], width=0.5)
plt.title("二点分布PMF")
plt.subplot(222)
plt.plot(['0','0','1','1',' '], [0, 0.4, 0.4, 1.0,1.0])
plt.title("二点分布CDF")
plt.subplot(223)
b = [stats.binom.pmf(i,10,0.6) for i in range(0,11)]
plt.bar([str(i) for i in range(0,n+1)],b)
plt.title('二项分布PMF')
plt.subplot(224)
plt.title("二项分布CDF")
c = [str(i//2) for i in range(0,2*(n+1))]
c.append('')
d = [stats.binom.cdf(i//2,10,0.6) for i in range(0,22)]
d.insert(0,0)
plt.plot(c,d)
plt.show()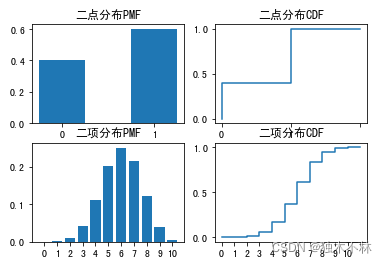
当np≥10,n(1-p)≥10都满足时,二项分布可以近似为正态分布
3.1.3 泊松分布
设随机变量所有可能取的值为0,1,2,···,而取各个值的概率为
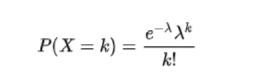
其中λ>0是常数。则称X服从参数为λ的泊松分布,记为X~π(λ)
n->+∞时,λ=np,二项分布=泊松分布
泊松分布的数学期望,方差分别为
E(X) = λ
D(X) = λ
3.1.4 几何分布
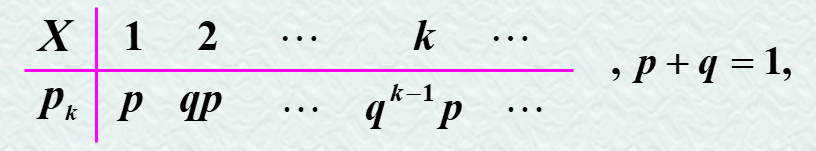 P(X=k)=p⋅qk−1
P(X=k)=p⋅qk−1
期望 :E ( X ) = 1/p
方差:D ( X ) =p/ q 2
3.1.5 超几何分布
如果有N个产品,其中有M个次品,从中随机抽取n个,这n个产品中含有次品的个数是一个离散型随机变量,概率分布为:
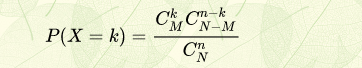
超几何分布的数学期望和方差分别为:
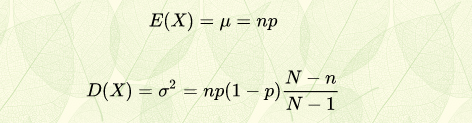
3.2 连续型随机变量及其分布规律
3.2.1 均匀分布

记为X~U(a,b)
分布函数:
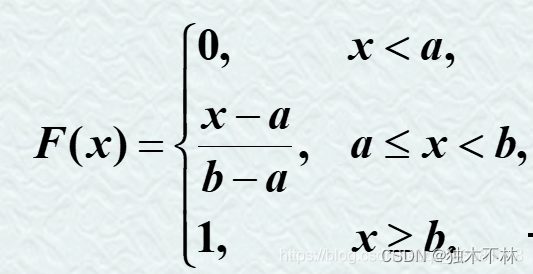
3.2.2 指数分布
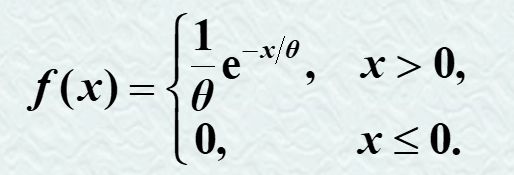
分布函数:
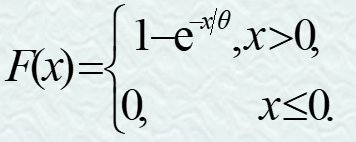
3.2.3 正态分布
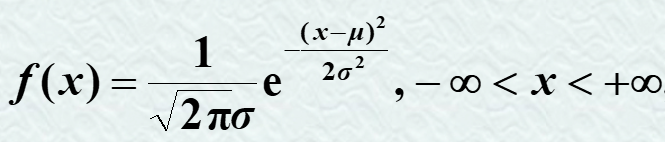
记为X~N(μ,σ2)
标准正态分布:N(0,1)。即:
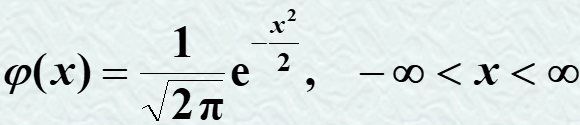
正态分布的分布函数为
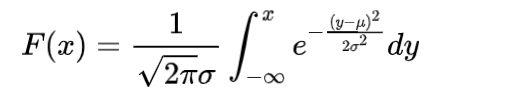
正态分布随机数的生成函数是normal(),其语法为:
normal(loc=0.0, scale=1.0, size=None)
- 参数loc:表示正态分布的均值
- 参数scale:表示正态分布的标准差,默认为1
- 参数size:表示生成随机数的数量
# 生成五个标准正态分布随机数
Norm = np.random.normal(size=5)
# 求生成的正态分布随机数的密度值
stats.norm.pdf(Norm)
# 求生成的正态分布随机数的累积密度值
stats.norm.cdf(Norm)
# 绘制正态分布PDF
# 注意这里使用的pdf和cdf函数是norm包里的
u=0
sigma=1
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.title('X~N({},{})正态分布PDF'.format(u,sigma**2))
x = np.linspace(-5,5,100000) # 设定分割区间
y1 = stats.norm.pdf(x,u,sigma**2)
plt.plot(x,y1)
plt.tight_layout() # 自动调整子图,使之充满画布整个区域
plt.show()
# 绘制正态分布CDF
plt.rcParams['font.sans-serif'] = ['SimHei']
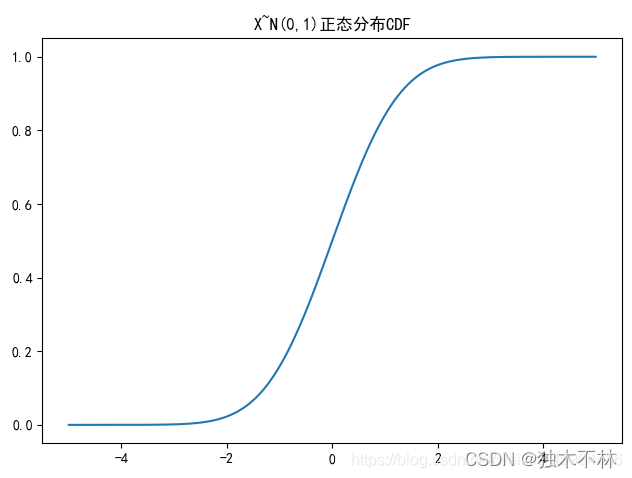
plt.title('X~N({},{})正态分布CDF'.format(u,sigma**2))
x = np.linspace(-5,5,100000) # 设定分割区间
y2 = stats.norm.cdf(x,u,sigma**2)
plt.plot(x,y2)
plt.tight_layout()
plt.show()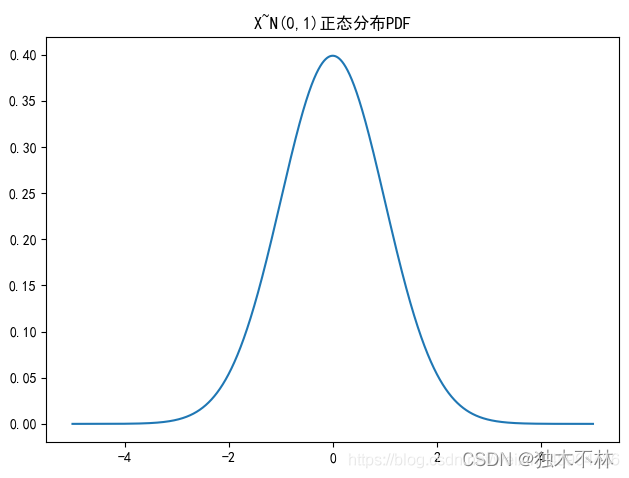
3.2.2 卡方分布
若Z1, Z2, … Zn,为n个服从标准正态分布的随机变量,则变量:

服从自由度为n的卡方分布,因为n的取值可以不同,所以卡方分布是一族分布而不是一个单独的分布。根据X的表达式,服从卡方分布的随机变量值不可能取负值,其期望值为n,方差为2n。
随机变量X的概率密度为
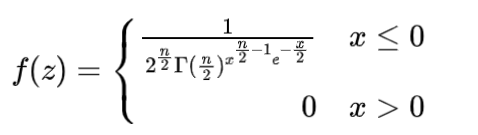
则称X服从自由度为n的卡方分布,记作X~ χ 2 (n)。
plt.plot(np.arange(0, 5, 0.002),\
stats.chi.pdf(np.arange(0, 5, 0.002), 3))
plt.title('卡方分布PDF(自由度为3)')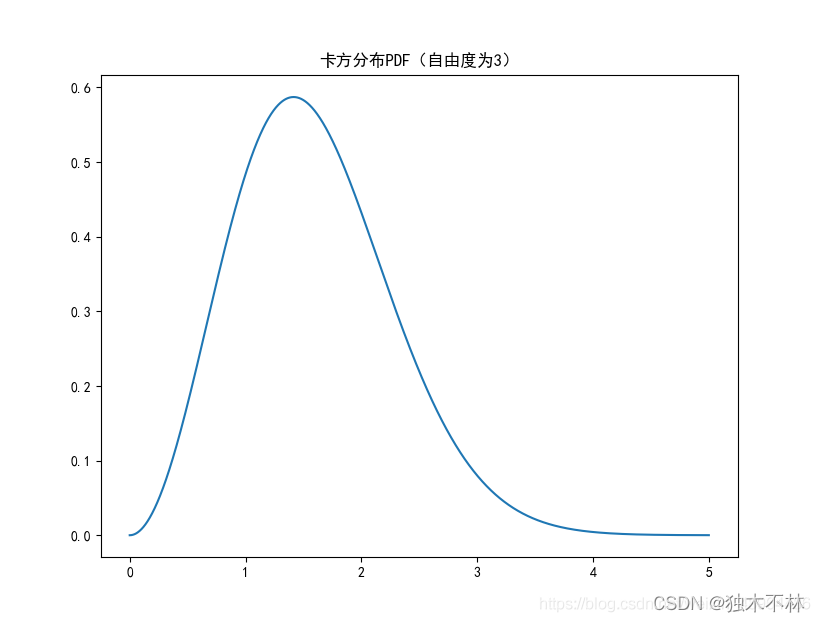 卡方分布以0为起点,分布是偏斜的,即非对称的,在自由度为3的卡方分布下,大多数值都小于8,查表可知只有5%的值大于7.82%。
卡方分布以0为起点,分布是偏斜的,即非对称的,在自由度为3的卡方分布下,大多数值都小于8,查表可知只有5%的值大于7.82%。
3.2.3 T分布
若随机变量Z ~ N ( 0 , 1 ) ,Y ~ χ 2 ( n ) ,且二者相互独立,则变量
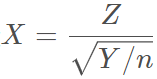
服从自由度为n的t分布,可以记作X ~t ( n )。
随机变量X的概率密度为:
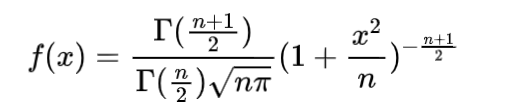
类似卡方分布,t分布也是整整一族,自由度n不同t分布即不同。
t分布变量取值范围为(− ∞ , + ∞ ),其期望值与方差存在于否,取值大小均与t分布的自由度有关。
- t(1)分布无有限期望值。
- t(2)有有限期望值,但方差不存在。
- n>2时,t(n)才同时有有限的期望值和方差,其中期望值为0,方差为n/(n-2),因此自由度越大,变量的方差越小,也就是说分布的离散程度越小。
x = np.arange(-4,4.004,0.004)
plt.plot(x, stats.norm.pdf(x), label='Normal')
plt.plot(x, stats.t.pdf(x,5), label='df=5')
plt.plot(x, stats.t.pdf(x,30), label='df=30')
plt.legend()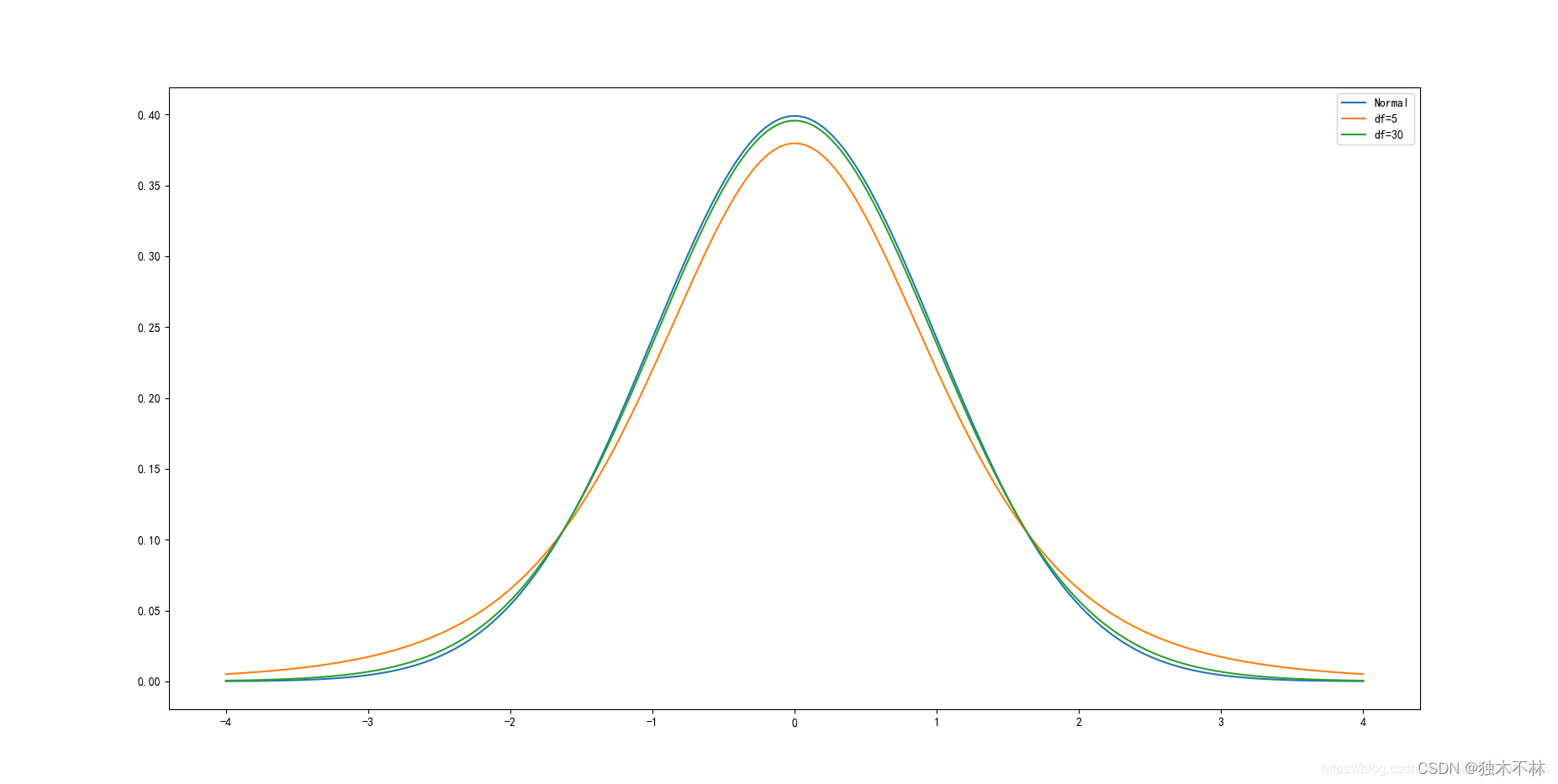 t分布的pdf曲线是以0为中心,左右对称的单峰分布,其形态变化与自由度n的大小有关,自由度越小,分布越分散;自由度越大,变量在其均值周围的聚集程度越高,也越接近标准正态分布曲线。
t分布的pdf曲线是以0为中心,左右对称的单峰分布,其形态变化与自由度n的大小有关,自由度越小,分布越分散;自由度越大,变量在其均值周围的聚集程度越高,也越接近标准正态分布曲线。
自由度为30时,t分布已经接近标准正态分布曲线。相较于标准正态分布,t分布的密度函数呈现出“尖峰厚尾”的特点。在现实中资产收益率分布往往呈现这种形态,因此t分布在对实际抽样结果的刻画上更为精确。t分布是在推断统计中常用的分布。
3.2.4 F分布
若Z,Y为两个独立的随机变量,且Z~χ 2 (n1) 、Y ~ χ 2 ( n2) ,则变量X = (Z /n1) / (Y / n2) 服从第一自由度为n1,第二自由度为n2的F分布。记作X~F ( n1, n2 ) 。
随机变量X的概率密度为
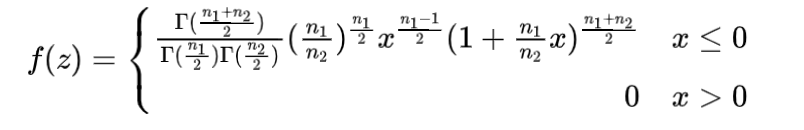
变量X是两个卡方变量(非负)之比,因此X的取值范围也为非负,其期望和方差存在于否取决于第二自由度n。
n > 2时,才存在期望,为n / n − 2
n > 4时,才存在方差,为[2n^2( m + n − 2 )] / [m ( n − 2 )^2 ( n − 4 )]
plt.plot(np.arange(0,5,0.002),\
stats.f.pdf(np.arange(0,5,0.002), 4, 40))
plt.title('F分布PDF(df1=4, df2=40)')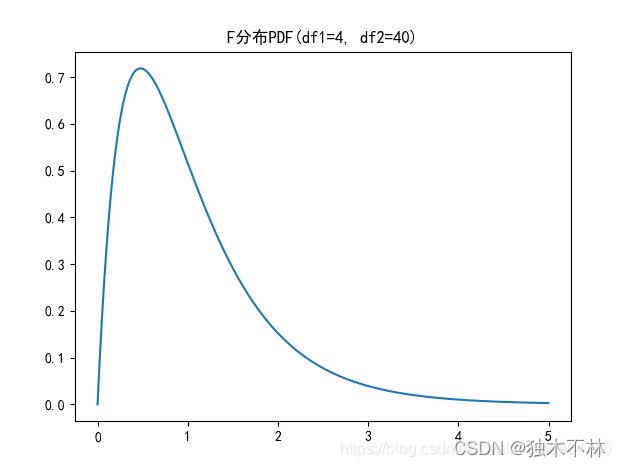

















 1293
1293

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









