







简介
非结构化数据
世界上大约超过百分之八十的数据都是非结构化数据,例如:图像、音视频、自然语言等,这些模型不遵循预定义的模式或组织方式,可以使用各种人工智能 (AI) 和机器学习 (ML) 模型转换为向量。
嵌入向量(Embedding vectors)
嵌入向量是非结构化数据的特征抽象,例如电子邮件、物联网传感器数据、Instagram 照片、蛋白质结构等等。从数学上来说,嵌入向量是浮点数或二进制数的数组。现代嵌入技术用于将非结构化数据转换为嵌入向量。
向量相似度搜索
向量相似性搜索是将向量与数据库进行比较以查找与查询向量最相似的向量的过程。近似最近邻(ANN - Approximate nearest neighbor)搜索算法用于加速搜索过程。如果两个嵌入向量非常相似,则意味着原始数据源也相似。
索引
FLAT
不经过量化(扁平)的索引,没有分层或分组,进行相似度搜索时,系统会计算查询向量与所有存储向量之前的相似度。因为它需要计算查询向量与所有存储向量之间的相似度,这会随着数据量的增加而变得非常昂贵,大规模数据集时需要更复杂的索引结构,如IVF_FLAT。
特点:每个向量都是扁平的,即未经过量化或者降维的处理,简单高效(更新效率高,不涉及倒排文件等结构)。
适用场景:适用于较小规模(百万级)的数据集,特别是当数据集能够完全加载到内存中时。
IVF_FLAT
Inverted File with FLAT (or non-quantized) vectors,即具有 flat(或非量化)向量的倒排文件索引,对应的还有一个 GPU 版本GPU_IVF_FLAT。
特点:使用了倒排文件(Inverted File)的结构,可以高效地处理大规模数据集。同时,每个向量也是扁平的,即未经过额外处理的原始向量。**
适用场景:适用于需要在大规模数据集中进行相似度搜索的情况,在搜索精度上与FLAT没有区别,但是在大规模数据集上可以先用倒排文件更快定位包含可能相似向量的倒排列表,从而减少计算相似度量的开销。
IVF_SQ8
Inverted File with Scalar Quantizer of 8 bits,即具有8位标量量化器的倒排文件索引。模型量化介绍
特点:它在量化向量时使用了较小的位数(8位),可以在保持较低存储开销的同时,实现相对较快的搜索速度。然而,由于使用了量化,可能会牺牲一些精度。
适用场景:用于在有限的磁盘、CPU 和 GPU 内存资源下,追求显著的资源消耗降低。这意味着在资源受限的环境中,它可以带来存储和内存的显著减少。
IVF_PQ
Inverted File with Product Quantization,对应的还有一个 GPU 版本GPU_IVF_PQ
特点:使用了一种叫做 Product Quantization 的技术,这种技术可以在加快查询速度的同时,对准确度进行一定的牺牲。
适用场景:用于追求高查询速度,会牺牲一定准确度。
HNSW
Hierarchical Navigable Small World,是一种基于图的索引结构,适用于对搜索效率要求较高的场景。这种索引结构通过构建一个分层的可导航小世界图,以支持高效的搜索操作。
相似度度量
欧氏距离(Euclidean Distance)
常用输入:计算机图像领域的内嵌Float向量
适用于连续的数值型数据,如图像处理、数值分析等领域。当各个特征的重要性相等时,欧氏距离是一个常见的选择。

import numpy as np
vector1 = np.array([1, 2, 3])
vector2 = np.array([4, 5, 6])
# 计算欧氏距离
euclidean_distance = np.linalg.norm(vector2 - vector1)
print("Euclidean Distance:", euclidean_distance)
余弦相似度(Cosine Similarity)
常用输入:文本领域的内嵌Float向量
余弦相似度计算两组数据之间的夹角(假设它们都是从[0,0,…]开始的线),它的值范围是[-1, 1],值越大相似度越高。
数学中
主要用于衡量两个向量之间的夹角,而不受向量大小的影响(只比较方向,不关系离坐标原点的远近)。适用于高维稀疏数据,比如文本数据。
数学概念中的余弦,表示的是直角三角形中,临边与斜边的比值,对应到数学中的概念是,空间中的一个点(x,y),余弦值为x / 坐标轴原点到这个点的长度。
假设二维坐标轴中有个点(3,4),根据勾股定义可以得到它的余弦值是 3/5 = 0.6,其中3,4分别对应的是这个点在x轴和y轴的分量。对于三维数组来说,就是三维空间的一个点,只是比二维多了一个维度的分量(z轴)。
在机器学习领域中,Embedding模型对词语进行向量化后,生成的位置信息通常都达到了几百维甚至上千维,但它本质上表示的是多维空间的一个点,从原点到该点都可以形成一条直线,两个输入就会形成两条直线,就可以计算他们的夹角。可以利用下面的公式使用每个维度的分量值来计算两个位置之间夹角的余弦值:
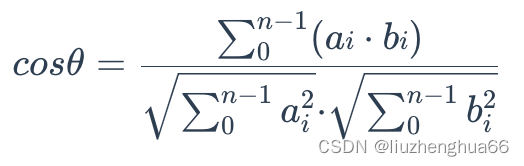
# linear algebra:线性代数,norm:求模
import numpy as np
# 两个一维数组
array1 = np.array([1, 2, 3])
array2 = np.array([4, 5, 6])
# 计算余弦相似度[-1, 1]
cosine_similarity = np.dot(array1, array2) / (np.linalg.norm(array1) * np.linalg.norm(array2))
print("Cosine Similarity:", cosine_similarity)
内积(Inner Product)
常用输入:文本/图形像素领域的内嵌Float向量
内积的计算是将两个向量对应位置的元素相乘后再相加。常用于度量两个向量的相似性,特别是在向量表示的语境中,如自然语言处理中的词向量。两个向量的内积越大,表示它们在方向上越相似,而越小则表示它们在方向上差异较大。内积主要用于度量向量之间的相似度,适用于密集向量。
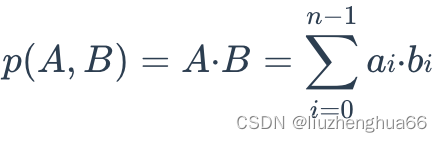
import numpy as np
vector1 = np.array([1, 2, 3])
vector2 = np.array([4, 5, 6])
# 使用 @ 运算符计算内积
result1 = vector1 @ vector2
# 使用 np.dot() 函数计算内积
result2 = np.dot(vector1, vector2)
Jaccard相似度(Jaccard Similarity)
常用输入:文本领域的内嵌Binary向量
主要应用于集合数据,如文档相似度计算、推荐系统中用户行为的相似性等。 Jaccard相似度计算的是两个集合交集与并集的比值。
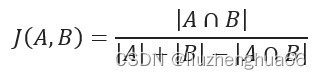
# python中list有序可重复,set无序不可重复。set提供了交、并等函数
import numpy as np
list1 = [1, 2, 3, 4]
list2 = [3, 4, 5, 6]
# 将列表转换为集合
set1 = set(list1)
set2 = set(list2)
# 计算 Jaccard 相似度
jaccard_similarity = len(set1.intersection(set2)) / len(set1.union(set2))
print("Jaccard Similarity:", jaccard_similarity)
分词
在大型语言模型(LLM Large Language Model)中,分词的目标是将输入的文本划分为更小的单元,通常称为 tokens。这有助于模型更好地理解文本的语法和语义。下面是两种常见的大型语言模型中的分词方法:
- BPE (Byte Pair Encoding)
一种基于统计的分词算法,它通过迭代地合并最频繁出现的字节对(byte pair)来构建一个子词词汇。这个过程会将文本切割成更小的单元,包括单个字符和多个字符的组合。BPE 被广泛用于序列到序列的模型和其他自然语言处理任务 - BERT系列
Bidirectional Encoder Representations from Transformers,即Transforms框架提供的双向编码器。它是一种预训练的语言模型,其核心是基于 Transformer 架构的双向编码器。BERT 在训练时要求输入文本在预处理阶段进行分词。通常,BERT 使用的是 WordPiece 或 Byte Pair Encoding(BPE)等分词方法,将文本划分为子词单元。
bert-base-uncased
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
print(tokenizer.tokenize("This is a tokenizer test, 这是一个分词器测试"))
# 输出:['this', 'is', 'a', 'token', '##izer', 'test', ',', '[UNK]', '[UNK]', '一', '[UNK]', '分', '[UNK]', '[UNK]', '[UNK]', '[UNK]']
bert-base-chinese
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
print(tokenizer.tokenize("This is a tokenizer test, 这是一个分词器测试"))
# 输出:['[UNK]', 'is', 'a', 'to', '##ken', '##ize', '##r', 'test', ',', '这', '是', '一', '个', '分', '词', '器', '测', '试']
xlm-roberta-large
from transformers import XLMRobertaTokenizerFast
tokenizer = XLMRobertaTokenizerFast.from_pretrained("xlm-roberta-large")
print(tokenizer.tokenize("This is a tokenizer test, 这是一个分词器测试"))
# 输出:['▁This', '▁is', '▁a', '▁to', 'ken', 'izer', '▁test', ',', '▁', '这是一个', '分', '词', '器', '测试']
选择合适的分词器
对于BERT来说,如果分词后不能识别这个词,会用[UNK]代替。可以通过识别Unknown出现的频率,可以判断分词器的效果。出现Unknown相当于输入中关于这个词丢失了,后续统计词频或者预测下个词的时候,也不会有你输入这个词的相关信息。
除了[UNK]频率这个指标外,我们还可以观察切分后语义的完成性。上述测试示例中可以看到bert简单把每个汉字作为一个分词,但是roberta就能把一个有意义的词语作为一个分词,显然从中文的效果上来看,roberta的效果更好。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









